Anda mungkin juga menyukai
- 2-Boletin Matrices - Determinantes BDokumen9 halaman2-Boletin Matrices - Determinantes BSamuelBelum ada peringkat
- A3 Espazos VectoriaisDokumen12 halamanA3 Espazos VectoriaisMaydayBelum ada peringkat
- Boletin 4 Inferencia SolucionesDokumen24 halamanBoletin 4 Inferencia Solucionesana riveiroBelum ada peringkat
- Listado5 Solución EMDokumen2 halamanListado5 Solución EMreypincheiraBelum ada peringkat
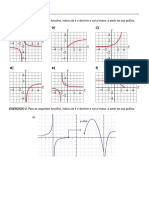
- Exercicios T0derivada2019-20jpgDokumen6 halamanExercicios T0derivada2019-20jpgManuel Caeiro MatinBelum ada peringkat
- Solución Extraordinaria Matemáticas 2014Dokumen8 halamanSolución Extraordinaria Matemáticas 2014Alejandro Iglesias GilBelum ada peringkat
- Boletin 7 DiagonalizacionDokumen5 halamanBoletin 7 DiagonalizacionSamuelBelum ada peringkat
- Identidades TrigonométricasDokumen9 halamanIdentidades TrigonométricasCarlos David Laura Quispe100% (1)
- 2oBachCC EBAU Galicia 2020-Ordinaria Resuelto CiuGDokumen8 halaman2oBachCC EBAU Galicia 2020-Ordinaria Resuelto CiuGCarla Castillo FernándezBelum ada peringkat
- 310ea3100104 01Dokumen12 halaman310ea3100104 01Yair De La PeñaBelum ada peringkat
- FUNCIONESDokumen3 halamanFUNCIONESIgnacio Arroyo CunhaBelum ada peringkat
- Practica 4Dokumen4 halamanPractica 4yagormarquezBelum ada peringkat
- TALLER 3 METODOS Segundo CorteDokumen22 halamanTALLER 3 METODOS Segundo CorteMaria Del Pilar ArciniegasBelum ada peringkat
- Func DerivablesDokumen9 halamanFunc DerivablesAlejandro Barrosa CampilloBelum ada peringkat
- B03GDokumen8 halamanB03Gbvsfkwdgw9Belum ada peringkat
- Boletin 2Dokumen4 halamanBoletin 2Yago Carbonell VázquezBelum ada peringkat
- 1-Boletin Iniciacion Complexos 7062016 C PDFDokumen4 halaman1-Boletin Iniciacion Complexos 7062016 C PDFSamuelBelum ada peringkat
- Solución Matemáticas 2014Dokumen8 halamanSolución Matemáticas 2014Alejandro Iglesias GilBelum ada peringkat
- Boletin 7Dokumen2 halamanBoletin 7sergiovicentegomezBelum ada peringkat
- 20 MatematicasDokumen2 halaman20 Matematicasv.arroyomanasseroBelum ada peringkat
- Exame 05 - 04 - 24Dokumen13 halamanExame 05 - 04 - 24luciavilaboy06Belum ada peringkat
- Lista 1 EDODokumen2 halamanLista 1 EDOEneias Moreira JuniorBelum ada peringkat
- Propostas de Resolução (Caderno de Fichas) PDFDokumen91 halamanPropostas de Resolução (Caderno de Fichas) PDFdwiwhfiwjbfsfnBelum ada peringkat
- Xeometría e Análise 2021Dokumen2 halamanXeometría e Análise 2021Lola Cousido PiñeiroBelum ada peringkat
- Reforzo UD 5 - Xeometría AnalíticaDokumen1 halamanReforzo UD 5 - Xeometría AnalíticamartinixvcBelum ada peringkat
- 20 MatematicasuyvuygDokumen21 halaman20 MatematicasuyvuyglaurapazosssssBelum ada peringkat
- 2022 AbauDokumen31 halaman2022 AbauPabloffvigoBelum ada peringkat
- Estimacià N IIDokumen2 halamanEstimacià N IISergio García MartínBelum ada peringkat
- EXAMEN PARCIAL 01 - SoluciónDokumen15 halamanEXAMEN PARCIAL 01 - Soluciónjairisaacdiazlozano83Belum ada peringkat
- Solución Examen Matemáticas II de Galicia (Ordinaria de 2015)Dokumen9 halamanSolución Examen Matemáticas II de Galicia (Ordinaria de 2015)Alejandro Iglesias GilBelum ada peringkat
- ENQ 2015 1 GabaritoDokumen10 halamanENQ 2015 1 GabaritoLoveleeGirlBelum ada peringkat
- Correccion T1Dokumen5 halamanCorreccion T1María Ángel OHBelum ada peringkat
- Ecuaciones Líneales 4Dokumen7 halamanEcuaciones Líneales 4Yair De La PeñaBelum ada peringkat
- Ejercicios Cap7Dokumen10 halamanEjercicios Cap7Geovanni GonzalezBelum ada peringkat
- Números Complexos: Unidade Didáctica 8Dokumen1 halamanNúmeros Complexos: Unidade Didáctica 8Almendrillas AlmendrasBelum ada peringkat
- Examen Matematicas A Acceso Grado Superior Galicia 2014Dokumen11 halamanExamen Matematicas A Acceso Grado Superior Galicia 2014Pablo VarelaBelum ada peringkat
- Beamer CanDokumen27 halamanBeamer CanHugo Carreira RialBelum ada peringkat
- Matematicas IIIDokumen185 halamanMatematicas IIIMacbookaluBelum ada peringkat
- P1 F4 2023 2 VF GABADokumen18 halamanP1 F4 2023 2 VF GABAjgato906Belum ada peringkat
- Solución 1 Aval 2 ExameDokumen2 halamanSolución 1 Aval 2 Exameanamatesverin1321Belum ada peringkat
- Minimos CudaradosDokumen1 halamanMinimos CudaradosFAVIANA ANDREA ZAPATA VALLEJOBelum ada peringkat
- Ecuaciones-Trigonometricas GalegoDokumen4 halamanEcuaciones-Trigonometricas GalegoeuholandeserranteBelum ada peringkat
- 20 MatemDokumen32 halaman20 MatemlaurapazosssssBelum ada peringkat
- Solución Examen Matemáticas II de Galicia (Extraordinaria de 2015)Dokumen8 halamanSolución Examen Matemáticas II de Galicia (Extraordinaria de 2015)Alejandro Iglesias GilBelum ada peringkat
- Boletín DiferenciaciónDokumen4 halamanBoletín DiferenciaciónAndrea ExpidoBelum ada peringkat
- Algebra PDFDokumen1 halamanAlgebra PDFSamuel Abreu PradoBelum ada peringkat
- FórmulasDokumen3 halamanFórmulasDiana OsorioBelum ada peringkat
- Segunda Proba 09 11 2017Dokumen5 halamanSegunda Proba 09 11 2017Kika EsBelum ada peringkat
- Boletin 1.1 5Dokumen2 halamanBoletin 1.1 5claudiagBelum ada peringkat
- A1 Reais ComplexosDokumen9 halamanA1 Reais ComplexosMaydayBelum ada peringkat
- Integración Funciones RacionalesDokumen3 halamanIntegración Funciones RacionalesHaytham EssahmBelum ada peringkat
- Exame Xaneiro 2015Dokumen2 halamanExame Xaneiro 2015Mauricio Andres Reyes NaranjoBelum ada peringkat
- Exercicios Resolvidos Calculo de Deslocamentos TTV Matricial 26fev15 PDFDokumen13 halamanExercicios Resolvidos Calculo de Deslocamentos TTV Matricial 26fev15 PDFRosalia Jacinto MagueleBelum ada peringkat
- Boletin AplicaciónsLinearesDokumen5 halamanBoletin AplicaciónsLinearesAndrea ExpidoBelum ada peringkat
- 1âºav2201 Alxebra (Sol)Dokumen2 halaman1âºav2201 Alxebra (Sol)bbyggrllBelum ada peringkat
- EstadísticaDokumen9 halamanEstadísticaHugo Carreira RialBelum ada peringkat
- 2022年imo预选题及其解答 王正、陈晨 (学而思教育集团)Dokumen23 halaman2022年imo预选题及其解答 王正、陈晨 (学而思教育集团)lingxu maoBelum ada peringkat
- Identidades Trigonométricas IDokumen1 halamanIdentidades Trigonométricas IBranco ChallapaBelum ada peringkat