Anda mungkin juga menyukai
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- Tips - Essential Evolutionary Psychology PDFDokumen281 halamanTips - Essential Evolutionary Psychology PDFRadhey Surve100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Medica Wing Mind Map For Biology NeetDokumen80 halamanMedica Wing Mind Map For Biology NeetFaizan AliBelum ada peringkat
- Animal Cell Coloring GuideDokumen3 halamanAnimal Cell Coloring GuideAlfie Cabario100% (1)
- Endangered Tree Species in The PhilippinesDokumen40 halamanEndangered Tree Species in The PhilippinesKaye Carrillo DuranBelum ada peringkat
- Edited - Earth and Life Science Activity 3 2nd QuarterDokumen12 halamanEdited - Earth and Life Science Activity 3 2nd QuarterBeneath Estefona0% (1)
- Molecular Dynamics SimulationsDokumen14 halamanMolecular Dynamics SimulationsMusyoka Thommas MutemiBelum ada peringkat
- Anchor Your LifeDokumen1 halamanAnchor Your LifeMusyoka Thommas MutemiBelum ada peringkat
- EnergyDokumen170 halamanEnergyMusyoka Thommas MutemiBelum ada peringkat
- Songs Holy CommunionDokumen1 halamanSongs Holy CommunionMusyoka Thommas MutemiBelum ada peringkat
- Happy Birthday Mzee KibakiDokumen1 halamanHappy Birthday Mzee KibakiMusyoka Thommas MutemiBelum ada peringkat
- SHBB 2221Dokumen1 halamanSHBB 2221Musyoka Thommas MutemiBelum ada peringkat
- CpiDokumen16 halamanCpiMusyoka Thommas MutemiBelum ada peringkat
- Songs Holy CommunionDokumen1 halamanSongs Holy CommunionMusyoka Thommas MutemiBelum ada peringkat
- PresDokumen1 halamanPresmutemi musyoka thommasBelum ada peringkat
- Summary 3 ExptDokumen10 halamanSummary 3 ExptMusyoka Thommas MutemiBelum ada peringkat
- SHBB 2221Dokumen1 halamanSHBB 2221Musyoka Thommas MutemiBelum ada peringkat
- Multiple Reads Per Well - AlignmentDokumen6 halamanMultiple Reads Per Well - AlignmentMusyoka Thommas MutemiBelum ada peringkat
- Chapter 2Dokumen3 halamanChapter 2Musyoka Thommas MutemiBelum ada peringkat
- SequenceDokumen4 halamanSequenceMusyoka Thommas MutemiBelum ada peringkat
- Amino AcidsDokumen1 halamanAmino AcidsMusyoka Thommas MutemiBelum ada peringkat
- SequenceDokumen4 halamanSequenceMusyoka Thommas MutemiBelum ada peringkat
- Multiple Reads Per Well - AlignmentDokumen6 halamanMultiple Reads Per Well - AlignmentMusyoka Thommas MutemiBelum ada peringkat
- Multi-Well Plate Absorbance ReadingsDokumen35 halamanMulti-Well Plate Absorbance ReadingsMusyoka Thommas MutemiBelum ada peringkat
- IFN-stimulated Gene 15 (ISG15) Functions AsDokumen15 halamanIFN-stimulated Gene 15 (ISG15) Functions AsMusyoka Thommas MutemiBelum ada peringkat
- Introduction To BiofilmDokumen7 halamanIntroduction To BiofilmferosecifeBelum ada peringkat
- Proyecto de TransgénesisDokumen11 halamanProyecto de Transgénesisguillermo3sg-1Belum ada peringkat
- Timing, Rates and Spectra of Human Germline Mutation: ArticlesDokumen11 halamanTiming, Rates and Spectra of Human Germline Mutation: ArticlesAnonymous n2DPWfNuBelum ada peringkat
- Artikel Bahasa Inggris BiologiDokumen2 halamanArtikel Bahasa Inggris BiologiShahrasyidAbdulMalik100% (3)
- Anthropology of BiologyDokumen37 halamanAnthropology of BiologyFabrielle RafaelBelum ada peringkat
- Mother Tincture Group 9Dokumen3 halamanMother Tincture Group 9vijender AtriBelum ada peringkat
- Zoo SongDokumen1 halamanZoo SongNina UdellBelum ada peringkat
- SJKC YIT KHWAN Preschool English Exam 2022Dokumen2 halamanSJKC YIT KHWAN Preschool English Exam 2022LIM PEI NEE KPM-GuruBelum ada peringkat
- Pengaruh Cara Perbanyakan Vegetatif Terhadap Pertumbuhan Kopi Robusta (Coffea Canephora) Klon BP 308 Dan BP 534Dokumen8 halamanPengaruh Cara Perbanyakan Vegetatif Terhadap Pertumbuhan Kopi Robusta (Coffea Canephora) Klon BP 308 Dan BP 534Laili HijriBelum ada peringkat
- Saponins in Food, Feedstuffs and Medicinal Plants: W. OleszekDokumen4 halamanSaponins in Food, Feedstuffs and Medicinal Plants: W. Oleszekmf720383270Belum ada peringkat
- Tudung AkarDokumen17 halamanTudung AkarSyifa SariBelum ada peringkat
- Biology Revision On Structural AdaptationDokumen6 halamanBiology Revision On Structural AdaptationSelvarani NasaratnamBelum ada peringkat
- Scrapbook BioDokumen29 halamanScrapbook BioAejuewa Wa-waBelum ada peringkat
- Student Exploration: Cell StructureDokumen3 halamanStudent Exploration: Cell StructureMya GrantBelum ada peringkat
- S.no. Name of Pathlab Date of Visit Name of Person Contacted Name of AuthorityDokumen3 halamanS.no. Name of Pathlab Date of Visit Name of Person Contacted Name of AuthorityLinkD ResourcesBelum ada peringkat
- Ecological Study of Asiaticobdella Birmanica in Lendi and Galati Stream Near Palam District Parbhani, Maharashtra IndiaDokumen12 halamanEcological Study of Asiaticobdella Birmanica in Lendi and Galati Stream Near Palam District Parbhani, Maharashtra IndiaTJPRC PublicationsBelum ada peringkat
- Food Chain InteractionsDokumen6 halamanFood Chain InteractionsMaya BabaoBelum ada peringkat
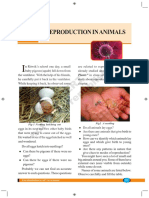
- Reproduction in Animals: Plants" in Class Seventh. Now You WillDokumen18 halamanReproduction in Animals: Plants" in Class Seventh. Now You WillvenkataBelum ada peringkat
- Growing Yeast - Sugar FermentationDokumen2 halamanGrowing Yeast - Sugar FermentationHiba Ammar100% (1)
- IPM Package For Leguminous Veg PDFDokumen55 halamanIPM Package For Leguminous Veg PDFronniel revadeneraBelum ada peringkat
- Soil Types and VegetationDokumen3 halamanSoil Types and VegetationAnushka AnandBelum ada peringkat
- Regulation of sex expression and flowering in papayaDokumen3 halamanRegulation of sex expression and flowering in papayaGustavo SantosBelum ada peringkat
- RNA Protein Synthesis Gizmo COMPLETEDDokumen7 halamanRNA Protein Synthesis Gizmo COMPLETEDcokcreBelum ada peringkat
- SG Unit5progresscheckfrq 5e815f88c4fb70Dokumen9 halamanSG Unit5progresscheckfrq 5e815f88c4fb70api-485795043Belum ada peringkat
- Enfermedades Bacterianas de Eucaliptos Estado ActuDokumen10 halamanEnfermedades Bacterianas de Eucaliptos Estado ActuVictor Eranio RuizBelum ada peringkat