Anda mungkin juga menyukai
- DaganDokumen6 halamanDaganSacdiya MurzalBelum ada peringkat
- Epidemiology Case-Control Studies Research DesignDokumen4 halamanEpidemiology Case-Control Studies Research DesignAndres Suarez UsbeckBelum ada peringkat
- Case Control Study DesignDokumen15 halamanCase Control Study Designgeorgeloto12Belum ada peringkat
- Case-Control Study Design GuideDokumen6 halamanCase-Control Study Design GuideAndre ChundawanBelum ada peringkat
- 3.3 Case-Control StudiesDokumen5 halaman3.3 Case-Control StudiesRicardo GomesBelum ada peringkat
- Case Control StudiesDokumen8 halamanCase Control StudiesInt MSc Batch 1Belum ada peringkat
- Case-Control and Cross-Sectional Study DesignsDokumen3 halamanCase-Control and Cross-Sectional Study DesignsAndrea BardalesBelum ada peringkat
- Case Control StudyDokumen6 halamanCase Control Studyphian0Belum ada peringkat
- Dissertation Ovarian CancerDokumen12 halamanDissertation Ovarian CancerWriteMyPaperForCheapCanada100% (1)
- Literature Review On Cervical Cancer ScreeningDokumen4 halamanLiterature Review On Cervical Cancer Screeningbqvlqjugf100% (1)
- Study DesginDokumen6 halamanStudy DesginRajat GoelBelum ada peringkat
- Tutoriaula 4 ContraseptionDokumen15 halamanTutoriaula 4 Contraseptionrsudlubas14% (7)
- Analytical Epidemiology: Case Control StudyDokumen32 halamanAnalytical Epidemiology: Case Control StudydeissuzaBelum ada peringkat
- MPT 2084 PDFDokumen9 halamanMPT 2084 PDFdebkantha gopeBelum ada peringkat
- Ovarian Cancer DissertationDokumen5 halamanOvarian Cancer DissertationHelpWritingPaperYonkers100% (1)
- A Comparative Analysis of ClassificationDokumen12 halamanA Comparative Analysis of ClassificationSharmi BhatBelum ada peringkat
- Onco Part 3Dokumen2 halamanOnco Part 3Jovan Varona NealaBelum ada peringkat
- What Constitutes Good Trial Evidence?Dokumen6 halamanWhat Constitutes Good Trial Evidence?PatriciaBelum ada peringkat
- Case Control StudyDokumen34 halamanCase Control StudyRENJULAL100% (1)
- 2011 Article 342Dokumen4 halaman2011 Article 342Gilang IrwansyahBelum ada peringkat
- Cohort StudyDokumen31 halamanCohort Studysayednour50% (2)
- Comm 845 P20DLPH80659Dokumen4 halamanComm 845 P20DLPH80659okpala helenBelum ada peringkat
- Sources of Cases: HospitalsDokumen19 halamanSources of Cases: HospitalsShaimaa AbdulkadirBelum ada peringkat
- Designs in Clinical ResearchDokumen29 halamanDesigns in Clinical ResearchAli KhanBelum ada peringkat
- Case control study design examines disease exposureDokumen2 halamanCase control study design examines disease exposuregeorgeloto12100% (1)
- Epidemiological Study Designs and Sampling Techniques (Autosaved 2222Dokumen37 halamanEpidemiological Study Designs and Sampling Techniques (Autosaved 2222officialmidasBelum ada peringkat
- In Biomedical Research: Study DesignsDokumen55 halamanIn Biomedical Research: Study DesignsDinda MutiaraBelum ada peringkat
- Lesson 9 - Etiologic Studies (3) Cohort Study Design Sample Size and Power ConsiderationsDokumen12 halamanLesson 9 - Etiologic Studies (3) Cohort Study Design Sample Size and Power ConsiderationsDawnBelum ada peringkat
- Prospective Study Cohort Study: Assis - Prof.Dr Diaa Marzouk Community MedicineDokumen30 halamanProspective Study Cohort Study: Assis - Prof.Dr Diaa Marzouk Community MedicineMona SamiBelum ada peringkat
- A Cost-Utility Analysis of Cervical Cancer Screening and Human Papillomavirus Vaccination in The PhilippinesDokumen17 halamanA Cost-Utility Analysis of Cervical Cancer Screening and Human Papillomavirus Vaccination in The PhilippinesYukiko CalimutanBelum ada peringkat
- Case Control Studies Abawi 2017Dokumen18 halamanCase Control Studies Abawi 2017Obsinaan Olyke KefelegnBelum ada peringkat
- Encyclopedia of Public Health - Cohort StudyDokumen3 halamanEncyclopedia of Public Health - Cohort StudyPhanindra Vasu KottiBelum ada peringkat
- Different observational study designs and their key featuresDokumen48 halamanDifferent observational study designs and their key featuresHiba MohammedBelum ada peringkat
- Case Control Study 1Dokumen9 halamanCase Control Study 1Marco TolentinoBelum ada peringkat
- 4 6044086027147021765Dokumen6 halaman4 6044086027147021765Gammachuu TarrafaaBelum ada peringkat
- Case Control StudyDokumen23 halamanCase Control StudySwapna JaswanthBelum ada peringkat
- Pi Is 0923753422018580Dokumen22 halamanPi Is 0923753422018580Gorodetchi PetruBelum ada peringkat
- Case Controls Studies Lancet PDFDokumen4 halamanCase Controls Studies Lancet PDFAhira Susana Mendoza de RiveraBelum ada peringkat
- Epidemiology ReviewDokumen10 halamanEpidemiology ReviewSaurabhBelum ada peringkat
- The Patient 'S View On Rare Disease Trial Design - A Qualitative StudyDokumen9 halamanThe Patient 'S View On Rare Disease Trial Design - A Qualitative StudyAMNA KHAN FITNESSSBelum ada peringkat
- Dissertation Randomised Controlled TrialDokumen4 halamanDissertation Randomised Controlled TrialBuyAPaperOnlineUK100% (1)
- Lectre 3 Study DesignDokumen19 halamanLectre 3 Study DesignGourav ChauhanBelum ada peringkat
- Study DesignDokumen3 halamanStudy DesignSamuel AdefemiBelum ada peringkat
- 03-Case Control Study 2017Dokumen33 halaman03-Case Control Study 2017Whatever UseeBelum ada peringkat
- Literature Review On Awareness of Breast CancerDokumen7 halamanLiterature Review On Awareness of Breast Cancerea8dfysf100% (1)
- Cervical CA Proposal Jan152010Dokumen21 halamanCervical CA Proposal Jan152010redblade_88100% (2)
- Actualidades en AnticoncepciónDokumen87 halamanActualidades en AnticoncepciónDamián López RangelBelum ada peringkat
- Rothman Greenland 05 Types Epi StudiesDokumen12 halamanRothman Greenland 05 Types Epi StudiesÁdám MolnárBelum ada peringkat
- NIH Public Access: Author ManuscriptDokumen18 halamanNIH Public Access: Author ManuscriptYosua_123Belum ada peringkat
- Clinical Types of Epidemiological StudiesDokumen3 halamanClinical Types of Epidemiological StudiesEduardo Proaño100% (1)
- Prevalence, Indications, Risk Indicators, and Outcomes of Emergency Peripartum Hysterectomy WorldwideDokumen14 halamanPrevalence, Indications, Risk Indicators, and Outcomes of Emergency Peripartum Hysterectomy WorldwideSuci RahmayeniBelum ada peringkat
- Find and Record Outbreak CasesDokumen37 halamanFind and Record Outbreak CasesHussein Omar Ali 212-41-1419Belum ada peringkat
- Retrospective Studies and Chart Reviews: Dean R Hess PHD RRT FaarcDokumen4 halamanRetrospective Studies and Chart Reviews: Dean R Hess PHD RRT Faarcdoc_next_doorBelum ada peringkat
- Precision Medicine in Pediatric Oncology: ReviewDokumen8 halamanPrecision Medicine in Pediatric Oncology: ReviewCiocan AlexandraBelum ada peringkat
- Kader2018 Atypical Ductal Hyperplasia - Update On Diagnosis, Management, and Molecular LandscapeDokumen11 halamanKader2018 Atypical Ductal Hyperplasia - Update On Diagnosis, Management, and Molecular LandscapeLyka MahrBelum ada peringkat
- Passive Smoking and Cervical Cancer Risk: A Meta-Analysis Based On 3,230 Cases and 2,982 ControlsDokumen7 halamanPassive Smoking and Cervical Cancer Risk: A Meta-Analysis Based On 3,230 Cases and 2,982 ControlsarnalordBelum ada peringkat
- Case Control Studies - PubMedDokumen3 halamanCase Control Studies - PubMedrsaurabh396Belum ada peringkat
- Dissertation On Cervical Cancer ScreeningDokumen7 halamanDissertation On Cervical Cancer ScreeningSomeToWriteMyPaperUK100% (1)
- Individual Management of Cervical Cancer in Pregnancy (Jurnal Ana)Dokumen12 halamanIndividual Management of Cervical Cancer in Pregnancy (Jurnal Ana)Awilia Eka PutriBelum ada peringkat
- Cancer Immunology: Bench to Bedside Immunotherapy of CancersDari EverandCancer Immunology: Bench to Bedside Immunotherapy of CancersBelum ada peringkat
- Guidelines of Clinical & Public Health Management of Melioidosis in PahangDokumen55 halamanGuidelines of Clinical & Public Health Management of Melioidosis in PahangShamini ShanmugalingamBelum ada peringkat
- Plan Your Day To Lose WeightDokumen4 halamanPlan Your Day To Lose WeightShamini ShanmugalingamBelum ada peringkat
- Physiology of G (Complicated Version)Dokumen3 halamanPhysiology of G (Complicated Version)Shamini ShanmugalingamBelum ada peringkat
- Sikorski - TargetedfluidtherDokumen13 halamanSikorski - TargetedfluidtherShamini ShanmugalingamBelum ada peringkat
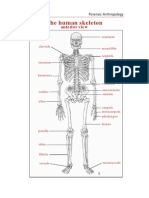
- The Human Skeleton: Anterior ViewDokumen0 halamanThe Human Skeleton: Anterior VieweduardoarcticBelum ada peringkat
- The Third Space Fact or FictionDokumen13 halamanThe Third Space Fact or FictionShamini ShanmugalingamBelum ada peringkat
- Sleep Apnea JournalDokumen4 halamanSleep Apnea JournalShamini ShanmugalingamBelum ada peringkat
- Power Point Presentation About Lecture 7 - Axial SkeletonDokumen54 halamanPower Point Presentation About Lecture 7 - Axial SkeletonShamini Shanmugalingam100% (1)
- Physical Examination: Orthopedics: Clinical Case Story 1 (Extremities)Dokumen0 halamanPhysical Examination: Orthopedics: Clinical Case Story 1 (Extremities)Shamini ShanmugalingamBelum ada peringkat
- Hemo-Dialysis Related JournalDokumen5 halamanHemo-Dialysis Related JournalShamini ShanmugalingamBelum ada peringkat
- Glyc o July 242009Dokumen2 halamanGlyc o July 242009Shamini ShanmugalingamBelum ada peringkat
- Biolog IDokumen90 halamanBiolog IShamini ShanmugalingamBelum ada peringkat
- Daniel Chappell, Matthias Jacob, Oliver Paul, Laurenz Mehringer, Walter Newman and Bernhard Friedrich BeckerDokumen2 halamanDaniel Chappell, Matthias Jacob, Oliver Paul, Laurenz Mehringer, Walter Newman and Bernhard Friedrich BeckerShamini ShanmugalingamBelum ada peringkat
- 42TOPROCJDokumen10 halaman42TOPROCJShamini ShanmugalingamBelum ada peringkat
- Fluid Therapy - The Basics, Reappraised: EditorialsDokumen3 halamanFluid Therapy - The Basics, Reappraised: EditorialsShamini ShanmugalingamBelum ada peringkat
- Fluid Management in Critically Ill Patients: The Role of Extravascular Lung Water, Abdominal Hypertension, Capillary Leak, and Fluid BalanceDokumen12 halamanFluid Management in Critically Ill Patients: The Role of Extravascular Lung Water, Abdominal Hypertension, Capillary Leak, and Fluid BalanceShamini ShanmugalingamBelum ada peringkat
- Fluid Management in Critical Ill Patient (Ehrenfried Schindler)Dokumen40 halamanFluid Management in Critical Ill Patient (Ehrenfried Schindler)Shamini ShanmugalingamBelum ada peringkat
- Tarbell ABEDokumen5 halamanTarbell ABEShamini ShanmugalingamBelum ada peringkat
- The Impact of Fluid Therapy On Microcirculation and Tissue Oxygenation in Hypovolemic Patients: A ReviewDokumen10 halamanThe Impact of Fluid Therapy On Microcirculation and Tissue Oxygenation in Hypovolemic Patients: A ReviewShamini ShanmugalingamBelum ada peringkat
- Revised Starling Equation and The Glycocalyx ModelDokumen11 halamanRevised Starling Equation and The Glycocalyx ModelShamini ShanmugalingamBelum ada peringkat
- Hematology 2012 Streiff 631 7Dokumen7 halamanHematology 2012 Streiff 631 7Shamini ShanmugalingamBelum ada peringkat
- Perioperative Fluid Therapy in Children: A Survey of Current Prescribing Practice, Br. J. Anaesth.-2006-Way-371-9Dokumen9 halamanPerioperative Fluid Therapy in Children: A Survey of Current Prescribing Practice, Br. J. Anaesth.-2006-Way-371-9Shamini ShanmugalingamBelum ada peringkat
- MothballsDokumen3 halamanMothballsShamini ShanmugalingamBelum ada peringkat
- 845 FullDokumen9 halaman845 FullShamini ShanmugalingamBelum ada peringkat
- Asj 1 75Dokumen5 halamanAsj 1 75Shamini ShanmugalingamBelum ada peringkat
- Achieve Greatly with Small Daily StepsDokumen21 halamanAchieve Greatly with Small Daily StepsShamini ShanmugalingamBelum ada peringkat
- Near-Wallm-PIV Reveals A Hydrodynamically Relevant Endothelial Surface Layer in Venules in VivoDokumen9 halamanNear-Wallm-PIV Reveals A Hydrodynamically Relevant Endothelial Surface Layer in Venules in VivoShamini ShanmugalingamBelum ada peringkat
- MothballsDokumen3 halamanMothballsShamini ShanmugalingamBelum ada peringkat
- COVER (Meningitis Bakterial)Dokumen1 halamanCOVER (Meningitis Bakterial)Shamini ShanmugalingamBelum ada peringkat
- A.2.3. Passive Transport Systems MCQsDokumen3 halamanA.2.3. Passive Transport Systems MCQsPalanisamy SelvamaniBelum ada peringkat
- The Life and Works of Jose RizalDokumen20 halamanThe Life and Works of Jose RizalBemtot Blanquig100% (1)
- Osora Nzeribe ResumeDokumen5 halamanOsora Nzeribe ResumeHARSHABelum ada peringkat
- Practical LPM-122Dokumen31 halamanPractical LPM-122anon_251667476Belum ada peringkat
- LLoyd's Register Marine - Global Marine Safety TrendsDokumen23 halamanLLoyd's Register Marine - Global Marine Safety Trendssuvabrata_das01100% (1)
- Philippine College of Northwestern Luzon Bachelor of Science in Business AdministrationDokumen7 halamanPhilippine College of Northwestern Luzon Bachelor of Science in Business Administrationzackwayne100% (1)
- T23 Field Weld Guidelines Rev 01Dokumen4 halamanT23 Field Weld Guidelines Rev 01tek_surinderBelum ada peringkat
- The Invisible Hero Final TNDokumen8 halamanThe Invisible Hero Final TNKatherine ShenBelum ada peringkat
- Chapter 9-10 (PPE) Reinzo GallegoDokumen48 halamanChapter 9-10 (PPE) Reinzo GallegoReinzo GallegoBelum ada peringkat
- AJK Newslet-1Dokumen28 halamanAJK Newslet-1Syed Raza Ali RazaBelum ada peringkat
- All MeterialsDokumen236 halamanAll MeterialsTamzid AhmedBelum ada peringkat
- AC7114-2 Rev N Delta 1Dokumen34 halamanAC7114-2 Rev N Delta 1Vijay YadavBelum ada peringkat
- Storytelling ScriptDokumen2 halamanStorytelling ScriptAnjalai Ganasan100% (1)
- STEM Spring 2023 SyllabusDokumen5 halamanSTEM Spring 2023 SyllabusRollins MAKUWABelum ada peringkat
- Chetan Bhagat's "Half GirlfriendDokumen4 halamanChetan Bhagat's "Half GirlfriendDR Sultan Ali AhmedBelum ada peringkat
- The Graduation Commencement Speech You Will Never HearDokumen4 halamanThe Graduation Commencement Speech You Will Never HearBernie Lutchman Jr.Belum ada peringkat
- 3 Steel Grating Catalogue 2010 - SERIES 1 PDFDokumen6 halaman3 Steel Grating Catalogue 2010 - SERIES 1 PDFPablo MatrakaBelum ada peringkat
- No.6 Role-Of-Child-Health-NurseDokumen8 halamanNo.6 Role-Of-Child-Health-NursePawan BatthBelum ada peringkat
- Legal Principles and The Limits of The Law Raz PDFDokumen33 halamanLegal Principles and The Limits of The Law Raz PDFlpakgpwj100% (2)
- The Polynesians: Task1: ReadingDokumen10 halamanThe Polynesians: Task1: ReadingHəşim MəmmədovBelum ada peringkat
- ArtigoPublicado ABR 14360Dokumen14 halamanArtigoPublicado ABR 14360Sultonmurod ZokhidovBelum ada peringkat
- Mythic Magazine 017Dokumen43 halamanMythic Magazine 017William Warren100% (1)
- Introduction To Streering Gear SystemDokumen1 halamanIntroduction To Streering Gear SystemNorman prattBelum ada peringkat
- ASD Manual and AISC LRFD Manual For Bolt Diameters Up To 6 Inches (150Dokumen1 halamanASD Manual and AISC LRFD Manual For Bolt Diameters Up To 6 Inches (150rabzihBelum ada peringkat
- Drypro832 PreInstallGude 0921YH220B 070627 FixDokumen23 halamanDrypro832 PreInstallGude 0921YH220B 070627 FixRicardoBelum ada peringkat
- Jesus - The Creator Unleashes Our Creative PotentialDokumen1 halamanJesus - The Creator Unleashes Our Creative PotentialKear Kyii WongBelum ada peringkat
- Fiery Training 1Dokumen346 halamanFiery Training 1shamilbasayevBelum ada peringkat
- A Woman's Talent Is To Listen, Says The Vatican - Advanced PDFDokumen6 halamanA Woman's Talent Is To Listen, Says The Vatican - Advanced PDFhahahapsuBelum ada peringkat
- WA Beretta M92FS Parts ListDokumen2 halamanWA Beretta M92FS Parts ListDenis Deki NehezBelum ada peringkat
- Believer - Imagine Dragons - CIFRA CLUBDokumen9 halamanBeliever - Imagine Dragons - CIFRA CLUBSilvio Augusto Comercial 01Belum ada peringkat