Anda mungkin juga menyukai
- MECATEAMDokumen4 halamanMECATEAMmarcfaleiroBelum ada peringkat
- UFLA2DDokumen3 halamanUFLA2DmarcfaleiroBelum ada peringkat
- WarthogDokumen6 halamanWarthogmarcfaleiroBelum ada peringkat
- Aula 18 - Girard IDokumen7 halamanAula 18 - Girard ImarcfaleiroBelum ada peringkat
- GPR2DDokumen4 halamanGPR2DmarcfaleiroBelum ada peringkat
- IBOTSDokumen4 halamanIBOTSmarcfaleiroBelum ada peringkat
- It AndroidsDokumen3 halamanIt AndroidsmarcfaleiroBelum ada peringkat
- Relações de Girard em Álgebra Nível 2Dokumen7 halamanRelações de Girard em Álgebra Nível 2marcfaleiroBelum ada peringkat
- Aula 12 - Funà à Es Implicitamente IIDokumen6 halamanAula 12 - Funà à Es Implicitamente IImarcfaleiroBelum ada peringkat
- Aula 14 - Revisà o IIDokumen7 halamanAula 14 - Revisà o IImarcfaleiroBelum ada peringkat
- Aula 16 - Complexos IDokumen7 halamanAula 16 - Complexos ImarcfaleiroBelum ada peringkat
- Aula 13 - Revisà o IDokumen6 halamanAula 13 - Revisà o ImarcfaleiroBelum ada peringkat
- Aula 11 - Funà à Es Implicitamente IDokumen8 halamanAula 11 - Funà à Es Implicitamente IMarcos VierBelum ada peringkat
- Aula 17 - Complexos IIDokumen6 halamanAula 17 - Complexos IImarcfaleiroBelum ada peringkat
- Aula 15 - ContinuidadeDokumen7 halamanAula 15 - ContinuidademarcfaleiroBelum ada peringkat
- Aula 10 - Máximos e Mà NimosDokumen7 halamanAula 10 - Máximos e Mà NimosmarcfaleiroBelum ada peringkat
- TDP Robok2DDokumen4 halamanTDP Robok2DmarcfaleiroBelum ada peringkat
- Relações de Girard em Álgebra Nível 2Dokumen7 halamanRelações de Girard em Álgebra Nível 2marcfaleiroBelum ada peringkat
- Aula 08 - Desigualdades IDokumen6 halamanAula 08 - Desigualdades ImarcfaleiroBelum ada peringkat
- Indução II - Exercícios ResolvidosDokumen9 halamanIndução II - Exercícios ResolvidosFabio CostaBelum ada peringkat
- Aula 16 - Complexos IDokumen7 halamanAula 16 - Complexos ImarcfaleiroBelum ada peringkat
- Produtos Notáveis e Problemas de ÁlgebraDokumen9 halamanProdutos Notáveis e Problemas de ÁlgebraMarcelo CostaBelum ada peringkat
- Aula 01 - Divisibilidade86Dokumen7 halamanAula 01 - Divisibilidade86Cris BarretoBelum ada peringkat
- Aula 09 - Desigualdades IIDokumen8 halamanAula 09 - Desigualdades IImarcfaleiroBelum ada peringkat
- Aula 06 - Inducao IDokumen6 halamanAula 06 - Inducao ImarcfaleiroBelum ada peringkat
- Relatorio BatimentosDokumen4 halamanRelatorio BatimentosmarcfaleiroBelum ada peringkat
- Aula 17 - Complexos IIDokumen6 halamanAula 17 - Complexos IImarcfaleiroBelum ada peringkat
- Aula 18 - Girard IDokumen7 halamanAula 18 - Girard ImarcfaleiroBelum ada peringkat
- 9divstokes PDFDokumen19 halaman9divstokes PDFThiago Lehr CompanhoniBelum ada peringkat
- Modelo de Proposta TécnicaDokumen3 halamanModelo de Proposta Técnicadumbledoreaaaa100% (1)
- Treinador Jacare - Peitoral InfernalDokumen7 halamanTreinador Jacare - Peitoral InfernalJose RibeiroBelum ada peringkat
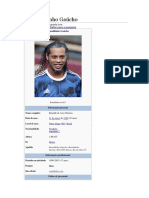
- Ronaldinho GaúchoDokumen24 halamanRonaldinho GaúchoThiago Brisolla100% (1)
- Plano treino completo GustavoDokumen3 halamanPlano treino completo GustavoLuis Gustavo CorreaBelum ada peringkat
- Resenha de Whiplash e relação treinador-atletaDokumen4 halamanResenha de Whiplash e relação treinador-atletaClaudson Cerqueira SantanaBelum ada peringkat
- SC Lista Atualizada de Iat CredenciadoDokumen32 halamanSC Lista Atualizada de Iat CredenciadoGranville Guedes de PaulaBelum ada peringkat
- Porque Indiana Joao, Primeiro CapituloDokumen21 halamanPorque Indiana Joao, Primeiro CapituloKaryoBelum ada peringkat
- RAT1702ADokumen12 halamanRAT1702ARogério FelixBelum ada peringkat
- QuintadolagobookDokumen23 halamanQuintadolagobookMarcelo MedeirosBelum ada peringkat
- Atividades 1Dokumen22 halamanAtividades 1Matheus GabrielBelum ada peringkat
- At Estado MedicoDokumen1 halamanAt Estado MedicointerlojasBelum ada peringkat
- COS - AryJose Rocco JR PDFDokumen281 halamanCOS - AryJose Rocco JR PDFLucas CamanhoBelum ada peringkat
- Introdução Historial Do Atletismo em Angola PDF Atletismo (Esporte) Esportes OlímpicosDokumen1 halamanIntrodução Historial Do Atletismo em Angola PDF Atletismo (Esporte) Esportes Olímpicosrogersilversilvestre100% (1)
- Uillian 2Dokumen54 halamanUillian 2uilliansmBelum ada peringkat
- Sistemas defensivos no andebolDokumen110 halamanSistemas defensivos no andebolFontapinhasBelum ada peringkat
- RF Canais FrequenciasDokumen1 halamanRF Canais FrequenciasFlávio RibeiroBelum ada peringkat
- 2010 - Volume 3 - Caderno Do Aluno - Ensino Médio - 1 Série - Educação FísicaDokumen4 halaman2010 - Volume 3 - Caderno Do Aluno - Ensino Médio - 1 Série - Educação FísicaAnderson Guarnier da SilvaBelum ada peringkat
- Segurança Publica Uff Tutora Distancia - Michel Lobo Toledo LimaDokumen8 halamanSegurança Publica Uff Tutora Distancia - Michel Lobo Toledo LimaMichel Lobo Toledo LimaBelum ada peringkat
- Injectors and fuel injector kitsDokumen35 halamanInjectors and fuel injector kitsmiguelBelum ada peringkat
- Técnicas defensivas do voleibolDokumen22 halamanTécnicas defensivas do voleibolMarcos CanutoBelum ada peringkat
- Simulação TVDEDokumen5 halamanSimulação TVDEAlex C RiveraBelum ada peringkat
- Marinha Resultado QT-2015Dokumen7 halamanMarinha Resultado QT-2015Emerson Cley OliveiraBelum ada peringkat
- Exercícios 4o ano revisão prét perfeitoDokumen5 halamanExercícios 4o ano revisão prét perfeitoCristina Marco BustamanteBelum ada peringkat
- Locais regulação via glicolíticaDokumen12 halamanLocais regulação via glicolíticaAlexandre DuqueBelum ada peringkat
- Candidatos Masculinos InscritosDokumen17 halamanCandidatos Masculinos InscritosJefferson SoaresBelum ada peringkat
- Beisebol: Regras e História do EsporteDokumen6 halamanBeisebol: Regras e História do EsporteIzabel GomesBelum ada peringkat
- Aprovados 1a Chamada SISU 2013.1 UFRBDokumen35 halamanAprovados 1a Chamada SISU 2013.1 UFRBRayner FreitasBelum ada peringkat
- ARTIGO - 11 Jogos Com Bolas para Brincar Com As Crianças - Pumpkin - PTDokumen16 halamanARTIGO - 11 Jogos Com Bolas para Brincar Com As Crianças - Pumpkin - PTMafalda RaposoBelum ada peringkat
- Plano de Aula Power MixDokumen3 halamanPlano de Aula Power MixMarcosRuizBelum ada peringkat
- 8ano EducacaofisicaDokumen106 halaman8ano EducacaofisicaBraulio AraujoBelum ada peringkat