Anda mungkin juga menyukai
- Geostatistics. Many Statistical Tools Are UsefulDokumen7 halamanGeostatistics. Many Statistical Tools Are UsefulJose RojasBelum ada peringkat
- Geographically Weighted Regression Modelling Spatial NonstationarityDokumen14 halamanGeographically Weighted Regression Modelling Spatial NonstationarityDanang AriyantoBelum ada peringkat
- Biostatistics and Computer-based Analysis of Health Data using RDari EverandBiostatistics and Computer-based Analysis of Health Data using RBelum ada peringkat
- An Introduction To Statistical Learning From A Reg PDFDokumen25 halamanAn Introduction To Statistical Learning From A Reg PDFJawadBelum ada peringkat
- Introducing The Linear ModelDokumen15 halamanIntroducing The Linear ModelThanh Mai PhamBelum ada peringkat
- Modified Ps Final 2023Dokumen124 halamanModified Ps Final 2023Erasmos AffulBelum ada peringkat
- GOVOROV M. (1), GIENKO G. (2) (1) Vancouver Island University, NANAIMO, CANADA (2) University of Alaska Anchorage, Anchorage, United StatesDokumen13 halamanGOVOROV M. (1), GIENKO G. (2) (1) Vancouver Island University, NANAIMO, CANADA (2) University of Alaska Anchorage, Anchorage, United StatesradocajdorijanBelum ada peringkat
- Geostatistical AnálisisDokumen105 halamanGeostatistical AnálisisPaloma PozoBelum ada peringkat
- Probability, Statistics, and Reality: Essay Concerning The Social Dimension of ScienceDokumen10 halamanProbability, Statistics, and Reality: Essay Concerning The Social Dimension of Scienceforscribd1981Belum ada peringkat
- Special Invited Paper: Multivariate Analysis by Data Depth: Descriptive Statistics, Graphics and InferenceDokumen76 halamanSpecial Invited Paper: Multivariate Analysis by Data Depth: Descriptive Statistics, Graphics and InferenceSilvia Septi Rosa SitohangBelum ada peringkat
- A Handbook of Small Data Sets D. J. Hand, F. Daly, A. D. Lunn, K. J. McConway A PDFDokumen470 halamanA Handbook of Small Data Sets D. J. Hand, F. Daly, A. D. Lunn, K. J. McConway A PDFRodrigo ChangBelum ada peringkat
- Quantitative Ii PartialDokumen106 halamanQuantitative Ii PartialWendy CevallosBelum ada peringkat
- Pca TutorialDokumen27 halamanPca TutorialGregory A Perdomo PBelum ada peringkat
- One of The feat-WPS OfficeDokumen12 halamanOne of The feat-WPS Officermconvidhya sri2015Belum ada peringkat
- Pt1 Simple Linear RegressionDokumen77 halamanPt1 Simple Linear RegressionradhicalBelum ada peringkat
- Research Paper Using Regression AnalysisDokumen8 halamanResearch Paper Using Regression Analysisefe8zf19100% (1)
- DWDM Unit-2Dokumen20 halamanDWDM Unit-2CS BCABelum ada peringkat
- Intro MateDokumen21 halamanIntro MateMohamad AizatBelum ada peringkat
- Chapter 12Dokumen19 halamanChapter 12JJBB33Belum ada peringkat
- Dwnload Full Statistics For The Behavioral Sciences 10th Edition Gravetter Solutions Manual PDFDokumen35 halamanDwnload Full Statistics For The Behavioral Sciences 10th Edition Gravetter Solutions Manual PDFmasonh7dswebb100% (12)
- State SpaceDokumen50 halamanState Spacegodwinshi32Belum ada peringkat
- Essentials of Statistics For The Behavioral Sciences 3rd Edition by Nolan Heinzen ISBN Solution ManualDokumen6 halamanEssentials of Statistics For The Behavioral Sciences 3rd Edition by Nolan Heinzen ISBN Solution Manualalison100% (26)
- Chapter 2 - Preparing To ModelDokumen16 halamanChapter 2 - Preparing To ModelAnkit MouryaBelum ada peringkat
- Solution Manual For Essentials of Statistics For The Behavioral Sciences 3Rd Edition by Nolan Heinzen Isbn 1464107777 978146410777 Full Chapter PDFDokumen27 halamanSolution Manual For Essentials of Statistics For The Behavioral Sciences 3Rd Edition by Nolan Heinzen Isbn 1464107777 978146410777 Full Chapter PDFpatrick.coutee753100% (12)
- Simple Metric Sedimentary Statistics Used To Recognize Different EnvironmentsDokumen21 halamanSimple Metric Sedimentary Statistics Used To Recognize Different EnvironmentsMarcia S. S. CarrilloBelum ada peringkat
- Descriptive StatisticsDokumen27 halamanDescriptive Statisticschan kyoBelum ada peringkat
- A 2020-Bej1171Dokumen32 halamanA 2020-Bej1171Meriem PearlBelum ada peringkat
- (Michael Greenacre) Biplots in PracticeDokumen207 halaman(Michael Greenacre) Biplots in Practicepoladores100% (1)
- Introduction To Modeling Spatial Processes Using Geostatistical AnalystDokumen27 halamanIntroduction To Modeling Spatial Processes Using Geostatistical AnalystDavid Huamani UrpeBelum ada peringkat
- Solutions To II Unit Exercises From KamberDokumen16 halamanSolutions To II Unit Exercises From Kamberjyothibellaryv83% (42)
- Assignment CartoDokumen26 halamanAssignment CartoAfiq Munchyz100% (1)
- Chapter Six - Processing, Analyzing and Interpretation of DataDokumen56 halamanChapter Six - Processing, Analyzing and Interpretation of DataSitra AbduBelum ada peringkat
- The Problem of Overfitting: PerspectiveDokumen12 halamanThe Problem of Overfitting: PerspectiveManoj SharmaBelum ada peringkat
- Cluster Cat VarsDokumen17 halamanCluster Cat Varsfab101Belum ada peringkat
- Anatomy Inverse ProblemsDokumen305 halamanAnatomy Inverse ProblemsseismBelum ada peringkat
- Descriptive Staticstics: College of Information and Computing SciencesDokumen28 halamanDescriptive Staticstics: College of Information and Computing SciencesArt IjbBelum ada peringkat
- PC A TutorialDokumen12 halamanPC A TutorialAtul AgnihotriBelum ada peringkat
- Introduction To Psychological Statistics (Foster Et Al.)Dokumen226 halamanIntroduction To Psychological Statistics (Foster Et Al.)ncarab15Belum ada peringkat
- Statistics and ProbabilityDokumen6 halamanStatistics and ProbabilityShirelyBelum ada peringkat
- Siu L. Chow Keywords: Associated Probability, Conditional Probability, Confidence-Interval EstimateDokumen20 halamanSiu L. Chow Keywords: Associated Probability, Conditional Probability, Confidence-Interval EstimateTammie Jo WalkerBelum ada peringkat
- Business Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test BankDokumen37 halamanBusiness Statistics For Contemporary Decision Making Canadian 2nd Edition Black Test Bankdanielmillerxaernfjmcg100% (13)
- PGDISM Assignments 05 06Dokumen12 halamanPGDISM Assignments 05 06ashishBelum ada peringkat
- Sizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangDokumen27 halamanSizer Analysis For The Comparison of Regression Curves: Cheolwoo Park and Kee-Hoon KangjofrajodiBelum ada peringkat
- Multivariate Analysis Homework SolutionsDokumen7 halamanMultivariate Analysis Homework Solutionsg3re2c7y100% (1)
- Graphical Displays For Meta-AnalysisDokumen15 halamanGraphical Displays For Meta-Analysisdinh son myBelum ada peringkat
- CH 08Dokumen20 halamanCH 08replyjoe4Belum ada peringkat
- Data Screening ChecklistDokumen57 halamanData Screening ChecklistSugan PragasamBelum ada peringkat
- Journal of Statistical Software: Factominer: An R Package For Multivariate AnalysisDokumen18 halamanJournal of Statistical Software: Factominer: An R Package For Multivariate AnalysisLuis PragmahBelum ada peringkat
- Am (101-120) Analisis MultinivelDokumen20 halamanAm (101-120) Analisis Multinivelmaximal25Belum ada peringkat
- Education - Post 12th Standard - CSVDokumen11 halamanEducation - Post 12th Standard - CSVZohaib Imam88% (16)
- The Multivariate Social ScientistDokumen14 halamanThe Multivariate Social ScientistTeuku RazyBelum ada peringkat
- Guiang Mamow Paper 1 Statistical TermsDokumen5 halamanGuiang Mamow Paper 1 Statistical TermsGhianne Mae Anareta GuiangBelum ada peringkat
- Statistics For 9th GradeDokumen15 halamanStatistics For 9th GradeMiftahBelum ada peringkat
- Education - Post 12th Standard - CSVDokumen11 halamanEducation - Post 12th Standard - CSVRuhee's KitchenBelum ada peringkat
- Bayesian Methods For Empirical Macroeconomics With Big DataDokumen22 halamanBayesian Methods For Empirical Macroeconomics With Big DataStevensBelum ada peringkat
- Data ComputingDokumen23 halamanData ComputingSam PunjabiBelum ada peringkat
- Application of PLS-DA in Multivariate Image AnalysisDokumen9 halamanApplication of PLS-DA in Multivariate Image AnalysisIvan TrifkovićBelum ada peringkat
- Analysis of VarianceDokumen7 halamanAnalysis of VarianceAYU SARASWATIBelum ada peringkat
- BizznetmaniaDokumen2 halamanBizznetmaniazzzaBelum ada peringkat
- Pembahasan Utbk SBMPTN, CPNS, Ujian Mandiri, DLL.: Scanned by CamscannerDokumen16 halamanPembahasan Utbk SBMPTN, CPNS, Ujian Mandiri, DLL.: Scanned by CamscannerzzzaBelum ada peringkat
- MSH F NotificationOfAppointmentOfRMAsEMDokumen1 halamanMSH F NotificationOfAppointmentOfRMAsEMzzzaBelum ada peringkat
- VariogramsDokumen20 halamanVariogramsBuiNgocHieu92% (13)
- Book 1Dokumen3 halamanBook 1zzzaBelum ada peringkat
- Coallog Recommended Logging Sheets Data Entry Template v1.1Dokumen10 halamanCoallog Recommended Logging Sheets Data Entry Template v1.1zzzaBelum ada peringkat
- Jumah Ketukan Bagian Container Container + Wet Soil Container + Dry Soil W Water W Dry W (%) W Rata-Rata (%) 10 56 25Dokumen6 halamanJumah Ketukan Bagian Container Container + Wet Soil Container + Dry Soil W Water W Dry W (%) W Rata-Rata (%) 10 56 25zzzaBelum ada peringkat
- Object: 1 (12) Trisolation: 1 (1) : Validated FalseDokumen1 halamanObject: 1 (12) Trisolation: 1 (1) : Validated FalsezzzaBelum ada peringkat
- Object: 1 (12) Trisolation: 1 (1) : Validated FalseDokumen1 halamanObject: 1 (12) Trisolation: 1 (1) : Validated FalsezzzaBelum ada peringkat
- Prototype ManualDokumen1 halamanPrototype ManualzzzaBelum ada peringkat
- NotedDokumen3 halamanNotedzzzaBelum ada peringkat
- Konversi Satuan, Sipil, Analisis Satuan, Mpa Ke kg/cm2Dokumen1 halamanKonversi Satuan, Sipil, Analisis Satuan, Mpa Ke kg/cm2Muhammad Reza Umari75% (4)
- Object: 1 (12) Trisolation: 1 (1) : Validated FalseDokumen1 halamanObject: 1 (12) Trisolation: 1 (1) : Validated FalsezzzaBelum ada peringkat
- Herzberg Motivation DiagramDokumen1 halamanHerzberg Motivation DiagramzzzaBelum ada peringkat
- Laporan Slug-TestDokumen2 halamanLaporan Slug-TestzzzaBelum ada peringkat
- Asli V The Estimation of in Situ ResourcesDokumen2 halamanAsli V The Estimation of in Situ ResourceszzzaBelum ada peringkat
- V The Estimation of in Situ ResourcesDokumen3 halamanV The Estimation of in Situ ResourceszzzaBelum ada peringkat
- Size Weight (GR) Weight (Percentage) Cumulative Percentage Retained Cumulative Percentage PassDokumen1 halamanSize Weight (GR) Weight (Percentage) Cumulative Percentage Retained Cumulative Percentage PasszzzaBelum ada peringkat
- TSS2013 Students Application FormDokumen6 halamanTSS2013 Students Application FormirnakarinBelum ada peringkat
- Total Recrut Process enDokumen1 halamanTotal Recrut Process enOonk BaeBelum ada peringkat
- PemetaanDokumen2 halamanPemetaanzzzaBelum ada peringkat
- Romana Slope Mass Rating PDFDokumen45 halamanRomana Slope Mass Rating PDFzzza100% (5)
- Model A-10 - Epithermal Gold - (Silver-Base Metals)Dokumen3 halamanModel A-10 - Epithermal Gold - (Silver-Base Metals)zzzaBelum ada peringkat
- Table GeomorfologiDokumen4 halamanTable GeomorfologiEdwinYudhaNugrahaBelum ada peringkat
- Model A 11 - Calc Alkaline Porphyry Cu Mo Au WDokumen3 halamanModel A 11 - Calc Alkaline Porphyry Cu Mo Au WzzzaBelum ada peringkat
- Model A-10 - Epithermal Gold - (Silver-Base Metals)Dokumen3 halamanModel A-10 - Epithermal Gold - (Silver-Base Metals)zzzaBelum ada peringkat
- Model A-10 - Epithermal Gold - (Silver-Base Metals)Dokumen3 halamanModel A-10 - Epithermal Gold - (Silver-Base Metals)zzzaBelum ada peringkat
- Pet5PhaseD OutlineDokumen6 halamanPet5PhaseD OutlinezzzaBelum ada peringkat
- Model A-10 - Epithermal Gold - (Silver-Base Metals)Dokumen3 halamanModel A-10 - Epithermal Gold - (Silver-Base Metals)zzzaBelum ada peringkat
- Unit No 1Dokumen64 halamanUnit No 1Aadil VahoraBelum ada peringkat
- DWL-3200AP B1 Manual v2.40 PDFDokumen83 halamanDWL-3200AP B1 Manual v2.40 PDFFrank Erick Soto HuillcaBelum ada peringkat
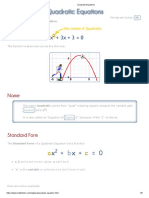
- Quadratic Equation - MATH IS FUNDokumen8 halamanQuadratic Equation - MATH IS FUNChanchan LebumfacilBelum ada peringkat
- Question Report - 11Dokumen17 halamanQuestion Report - 11Suryakant AgrawalBelum ada peringkat
- Mechanics of Solids by Crandall, Dahl, Lardner, 2nd ChapterDokumen118 halamanMechanics of Solids by Crandall, Dahl, Lardner, 2nd Chapterpurijatin100% (2)
- MS Excel FunctionsDokumen3 halamanMS Excel FunctionsRocket4Belum ada peringkat
- ThinkSmart Hub SpecDokumen5 halamanThinkSmart Hub SpecJose LopezBelum ada peringkat
- Anchor Lliberty Mpa ManDokumen8 halamanAnchor Lliberty Mpa ManIgnacio Barriga NúñezBelum ada peringkat
- Ash Content PDFDokumen4 halamanAsh Content PDFsunniBelum ada peringkat
- CHE504 - Lab Report On Gas Absorption L8 PDFDokumen23 halamanCHE504 - Lab Report On Gas Absorption L8 PDFRakesh KumarBelum ada peringkat
- Ijtmsr201919 PDFDokumen5 halamanIjtmsr201919 PDFPrakash InturiBelum ada peringkat
- NTSE Stage - 1 Mock Test - 3Dokumen16 halamanNTSE Stage - 1 Mock Test - 3Apex Institute100% (1)
- Example 6 1 Rectangular Water Tank DesignDokumen7 halamanExample 6 1 Rectangular Water Tank DesignMesfin Derbew88% (104)
- SMD TR60-1.0mm With 12mm Bar (Office Floor 3.64m Span) PDFDokumen2 halamanSMD TR60-1.0mm With 12mm Bar (Office Floor 3.64m Span) PDFabhijitkolheBelum ada peringkat
- Coding Bobol ExcelDokumen4 halamanCoding Bobol ExcelMuhammad IsmunandarsyahBelum ada peringkat
- Basics, Maintenance, and Diagnostics 19Dokumen1 halamanBasics, Maintenance, and Diagnostics 19imcoolmailme2Belum ada peringkat
- Irjet V4i10201 PDFDokumen8 halamanIrjet V4i10201 PDFBesmir IsmailiBelum ada peringkat
- Periodic Sequences With Optimal Properties For Channel Estimation and Fast Start-Up EqualizationDokumen6 halamanPeriodic Sequences With Optimal Properties For Channel Estimation and Fast Start-Up Equalizationbavar88Belum ada peringkat
- Functions Equations Question BankDokumen101 halamanFunctions Equations Question BankParth DesaiBelum ada peringkat
- Beckman Coulter GenomeLab TroubleshootDokumen56 halamanBeckman Coulter GenomeLab TroubleshootChrisBelum ada peringkat
- PCS-9881 Ethernet Switch Instruction Manual: NR Electric Co., LTDDokumen41 halamanPCS-9881 Ethernet Switch Instruction Manual: NR Electric Co., LTDRicchie Gotama SihiteBelum ada peringkat
- Pick and Place Robotic Arm Controlled by Computer - TJ211.42.M52 2007 - Mohamed Naufal B. OmarDokumen26 halamanPick and Place Robotic Arm Controlled by Computer - TJ211.42.M52 2007 - Mohamed Naufal B. OmarSAMBelum ada peringkat
- AristotleDokumen126 halamanAristotlenda_naumBelum ada peringkat
- Research MethodsDokumen10 halamanResearch MethodsAhimbisibwe BenyaBelum ada peringkat
- Operational Information Bearing MaterialsDokumen2 halamanOperational Information Bearing MaterialsHim SatiBelum ada peringkat
- Experiment 1Dokumen6 halamanExperiment 1srinathlalBelum ada peringkat
- EEMDokumen17 halamanEEMSandaruwan සුජීවBelum ada peringkat
- Phase Diagrams: By: Cherides P. MarianoDokumen25 halamanPhase Diagrams: By: Cherides P. MarianoWild RiftBelum ada peringkat
- Introduction To Software TestingDokumen42 halamanIntroduction To Software TestingRoxanaBelum ada peringkat
- For Bookbind Final April 2019 PDFDokumen151 halamanFor Bookbind Final April 2019 PDFNeo VeloriaBelum ada peringkat
- FreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsDari EverandFreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsPenilaian: 5 dari 5 bintang5/5 (1)
- Autodesk Inventor 2020: A Power Guide for Beginners and Intermediate UsersDari EverandAutodesk Inventor 2020: A Power Guide for Beginners and Intermediate UsersBelum ada peringkat
- CATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchDari EverandCATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchPenilaian: 4 dari 5 bintang4/5 (10)
- Beginning AutoCAD® 2020 Exercise WorkbookDari EverandBeginning AutoCAD® 2020 Exercise WorkbookPenilaian: 2.5 dari 5 bintang2.5/5 (3)
- SketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyDari EverandSketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyPenilaian: 1.5 dari 5 bintang1.5/5 (2)
- Product Manufacturing and Cost Estimating using CAD/CAE: The Computer Aided Engineering Design SeriesDari EverandProduct Manufacturing and Cost Estimating using CAD/CAE: The Computer Aided Engineering Design SeriesPenilaian: 4 dari 5 bintang4/5 (4)
- Autodesk Fusion 360: A Power Guide for Beginners and Intermediate Users (3rd Edition)Dari EverandAutodesk Fusion 360: A Power Guide for Beginners and Intermediate Users (3rd Edition)Penilaian: 5 dari 5 bintang5/5 (2)
- Certified Solidworks Professional Advanced Weldments Exam PreparationDari EverandCertified Solidworks Professional Advanced Weldments Exam PreparationPenilaian: 5 dari 5 bintang5/5 (1)
- Beginning AutoCAD® 2022 Exercise Workbook: For Windows®Dari EverandBeginning AutoCAD® 2022 Exercise Workbook: For Windows®Belum ada peringkat
- Certified Solidworks Professional Advanced Surface Modeling Exam PreparationDari EverandCertified Solidworks Professional Advanced Surface Modeling Exam PreparationPenilaian: 5 dari 5 bintang5/5 (1)
- 2024 – 2025 Newbies Guide to UI/UX Design Using FigmaDari Everand2024 – 2025 Newbies Guide to UI/UX Design Using FigmaBelum ada peringkat
- Up and Running with AutoCAD 2020: 2D Drafting and DesignDari EverandUp and Running with AutoCAD 2020: 2D Drafting and DesignBelum ada peringkat
- FreeCAD | Design Projects: Design advanced CAD models step by stepDari EverandFreeCAD | Design Projects: Design advanced CAD models step by stepPenilaian: 5 dari 5 bintang5/5 (1)
- Contactless Vital Signs MonitoringDari EverandContactless Vital Signs MonitoringWenjin WangBelum ada peringkat