Anda mungkin juga menyukai
- Game Developer 201012Dokumen52 halamanGame Developer 201012Shrikanth Malarouth100% (1)
- Management of Personal Finances of SHS at Sta. Teresa College Basis For Finance Management PlanDokumen16 halamanManagement of Personal Finances of SHS at Sta. Teresa College Basis For Finance Management PlanAllyza Princess Peradilla Magpantay100% (1)
- For The Sidereal Zodiac - Kenneth BowserDokumen3 halamanFor The Sidereal Zodiac - Kenneth BowserGuilherme Alves PereiraBelum ada peringkat
- VP Supply Chain in Columbus OH Resume Belinda SalsbureyDokumen2 halamanVP Supply Chain in Columbus OH Resume Belinda SalsbureyBelinda Salsburey100% (1)
- Happy Startup EbookDokumen72 halamanHappy Startup EbookLucca CinquarolliBelum ada peringkat
- Sample Size Determination PDFDokumen28 halamanSample Size Determination PDFVedanti Gandhi100% (1)
- Stats Project FinalDokumen10 halamanStats Project Finalapi-316977780Belum ada peringkat
- Skittles Project 5-02Dokumen8 halamanSkittles Project 5-02api-354040698Belum ada peringkat
- Skittles ProjectDokumen6 halamanSkittles Projectapi-319345408Belum ada peringkat
- Comprehensive Skittles Project Math 1040Dokumen7 halamanComprehensive Skittles Project Math 1040api-316732019Belum ada peringkat
- The Skittles Project FinalDokumen8 halamanThe Skittles Project Finalapi-316760667Belum ada peringkat
- Math 1040 Skittles Term ProjectDokumen9 halamanMath 1040 Skittles Term Projectapi-319881085Belum ada peringkat
- Math 1040 Skittles Term Project EportfolioDokumen7 halamanMath 1040 Skittles Term Project Eportfolioapi-260817278Belum ada peringkat
- SkittlesdataclassprojectDokumen8 halamanSkittlesdataclassprojectapi-399586872Belum ada peringkat
- Term Project ReportDokumen9 halamanTerm Project Reportapi-238585685Belum ada peringkat
- Skittles Project With ReflectionDokumen7 halamanSkittles Project With Reflectionapi-234712126100% (1)
- Skittles Term ProjectDokumen10 halamanSkittles Term Projectapi-273060240Belum ada peringkat
- Skittles Project Group Final WordDokumen6 halamanSkittles Project Group Final Wordapi-316239273Belum ada peringkat
- Math 1040 Statistics Term Project: Blake FreemanDokumen10 halamanMath 1040 Statistics Term Project: Blake Freemanapi-252919218Belum ada peringkat
- Skittles AssignmentDokumen8 halamanSkittles Assignmentapi-291800396Belum ada peringkat
- Math 1040 Skittles Term ProjectDokumen10 halamanMath 1040 Skittles Term Projectapi-310671451Belum ada peringkat
- Skittles Term Project 11 9 14Dokumen5 halamanSkittles Term Project 11 9 14api-192489685Belum ada peringkat
- TP 2 StatsDokumen5 halamanTP 2 Statsapi-240850453Belum ada peringkat
- Stats StuffDokumen7 halamanStats Stuffapi-242298926Belum ada peringkat
- Math Skittles ProjectDokumen4 halamanMath Skittles Projectapi-495044344Belum ada peringkat
- Skittles Project Part 5Dokumen16 halamanSkittles Project Part 5api-246855746Belum ada peringkat
- Statistics Project 17Dokumen13 halamanStatistics Project 17api-271978152Belum ada peringkat
- Final ProjectDokumen9 halamanFinal Projectapi-262329757Belum ada peringkat
- Skittles Project 1Dokumen7 halamanSkittles Project 1api-299868669100% (2)
- Emily Gregorio Skittles Project FinalDokumen3 halamanEmily Gregorio Skittles Project Finalapi-288933258Belum ada peringkat
- Skittles ProjectDokumen9 halamanSkittles Projectapi-242873849Belum ada peringkat
- Skittles ProjectDokumen5 halamanSkittles Projectapi-271444168Belum ada peringkat
- 1.pocket Money (Lesson Plan)Dokumen3 halaman1.pocket Money (Lesson Plan)Malou AredamBelum ada peringkat
- Skittles ProjectDokumen9 halamanSkittles Projectapi-252747849Belum ada peringkat
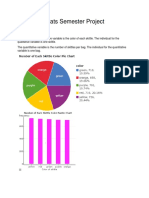
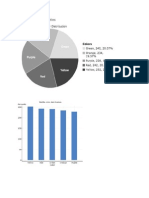
- Stats Semester ProjectDokumen11 halamanStats Semester Projectapi-276989071Belum ada peringkat
- Stats ProjectDokumen14 halamanStats Projectapi-302666758Belum ada peringkat
- Skittles Project Stats 1040Dokumen8 halamanSkittles Project Stats 1040api-301336765Belum ada peringkat
- Skittles Project Math 1040Dokumen8 halamanSkittles Project Math 1040api-495044194Belum ada peringkat
- EportfolioDokumen8 halamanEportfolioapi-242211470Belum ada peringkat
- Term Project - EportfolioDokumen7 halamanTerm Project - Eportfolioapi-251981709Belum ada peringkat
- Skittle Pareto ChartDokumen7 halamanSkittle Pareto Chartapi-272391081Belum ada peringkat
- Skittles Term Project - Kai Galbiso Stat1040Dokumen6 halamanSkittles Term Project - Kai Galbiso Stat1040api-316758771Belum ada peringkat
- Final Math ProjectDokumen7 halamanFinal Math Projectapi-316775963Belum ada peringkat
- Math 1040Dokumen3 halamanMath 1040api-219553415Belum ada peringkat
- Statistics Term Project E-Portfolio ReflectionDokumen8 halamanStatistics Term Project E-Portfolio Reflectionapi-258147701Belum ada peringkat
- Skittles ProjectDokumen6 halamanSkittles Projectapi-495018964Belum ada peringkat
- Sample SizeDokumen28 halamanSample SizeDelshad BotaniBelum ada peringkat
- 07 - Chapter 2 PDFDokumen28 halaman07 - Chapter 2 PDFBrhane TeklayBelum ada peringkat
- Kassem Hajj: Math 1040 Skittles Term ProjectDokumen10 halamanKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Belum ada peringkat
- Reflection and EportfolioDokumen8 halamanReflection and Eportfolioapi-252747849Belum ada peringkat
- Full Skittles ProjectDokumen13 halamanFull Skittles Projectapi-537189505Belum ada peringkat
- Skittles FinalDokumen12 halamanSkittles Finalapi-241861434Belum ada peringkat
- Group Project #1 - SkittlesDokumen9 halamanGroup Project #1 - Skittlesapi-245266056Belum ada peringkat
- Quiz 1 Review Questions-1Dokumen3 halamanQuiz 1 Review Questions-1Steven NguyenBelum ada peringkat
- Skittles 2 FinalDokumen12 halamanSkittles 2 Finalapi-242194552Belum ada peringkat
- Sanela Sakic 4/18/19: Total: 2,584 Candies (Sample Size)Dokumen7 halamanSanela Sakic 4/18/19: Total: 2,584 Candies (Sample Size)api-340495387Belum ada peringkat
- Topic 18 Identifying The Appropriate Test Statistics Involving Population MeanDokumen6 halamanTopic 18 Identifying The Appropriate Test Statistics Involving Population MeanPrincess VernieceBelum ada peringkat
- The Rainbow ReportDokumen11 halamanThe Rainbow Reportapi-316991888Belum ada peringkat
- Question.1. A Small Accounting Firm Pays Each of Its FiveDokumen6 halamanQuestion.1. A Small Accounting Firm Pays Each of Its Fivenitikush7419Belum ada peringkat
- Hypothesis Testing of Single Samples Based on FormulasDokumen6 halamanHypothesis Testing of Single Samples Based on FormulasBarbaros RosBelum ada peringkat
- X2gtefc4o2 Coy2 (RZDokumen14 halamanX2gtefc4o2 Coy2 (RZAlexa LeeBelum ada peringkat
- Final Stats ProjectDokumen8 halamanFinal Stats Projectapi-238717717100% (2)
- College ResumeDokumen2 halamanCollege Resumeapi-252859182Belum ada peringkat
- CivicDokumen3 halamanCivicapi-252859182Belum ada peringkat
- Bio LabDokumen3 halamanBio Labapi-252859182Belum ada peringkat
- Kali Hansen Chemistry May 5, 2015Dokumen5 halamanKali Hansen Chemistry May 5, 2015api-252859182Belum ada peringkat
- 53 Ways To Increase JoyDokumen1 halaman53 Ways To Increase Joyapi-252859182Belum ada peringkat
- History PaperDokumen16 halamanHistory Paperapi-252859182Belum ada peringkat
- Term ConnectionsDokumen3 halamanTerm Connectionsapi-252859182Belum ada peringkat
- Connection StructureDokumen6 halamanConnection Structureapi-252859182Belum ada peringkat
- Interview PlanDokumen8 halamanInterview Planapi-252859182Belum ada peringkat
- Lion King 2Dokumen7 halamanLion King 2api-252859182Belum ada peringkat
- Kwashiorkor 2Dokumen5 halamanKwashiorkor 2api-252859182Belum ada peringkat
- Historian Among Anthropologists: Excavating Boundaries Between DisciplinesDokumen34 halamanHistorian Among Anthropologists: Excavating Boundaries Between DisciplinesTanya Singh0% (1)
- PT 2 Pracba1Dokumen2 halamanPT 2 Pracba1LORNA GUIWANBelum ada peringkat
- BPO CampaignsDokumen2 halamanBPO CampaignsKiran Nair RBelum ada peringkat
- TQM MCQ'S FOR SECOND MID-TERMDokumen4 halamanTQM MCQ'S FOR SECOND MID-TERM17-550 Priyanka MaraboinaBelum ada peringkat
- Dbms FileDokumen25 halamanDbms FileKanika JawlaBelum ada peringkat
- Education: University/School NameDokumen2 halamanEducation: University/School NameCatherine AbabonBelum ada peringkat
- Why We Learn English Essay, English Composition Writing On Why We Learn English, Sample and Example EssaysDokumen10 halamanWhy We Learn English Essay, English Composition Writing On Why We Learn English, Sample and Example EssaysGeena TingBelum ada peringkat
- Bevel Gear DRAWING PDFDokumen1 halamanBevel Gear DRAWING PDFADITYA MOTLABelum ada peringkat
- Maharashtra National Law University Project Analyzes Rise and Impact of BRICS AllianceDokumen6 halamanMaharashtra National Law University Project Analyzes Rise and Impact of BRICS AllianceMithlesh ChoudharyBelum ada peringkat
- ABE SEASON II Quiz Bee FinaleDokumen8 halamanABE SEASON II Quiz Bee FinaleENFORCEMENT PENRO-APAYAOBelum ada peringkat
- MT6797 Android ScatterDokumen11 halamanMT6797 Android ScatterFaronBelum ada peringkat
- BS09 0875 882Dokumen8 halamanBS09 0875 882Atanas StoykovBelum ada peringkat
- Wormhole: Topological SpacetimeDokumen14 halamanWormhole: Topological SpacetimeHimanshu GiriBelum ada peringkat
- Seventh Grade Language Arts Letter of Introduction Frissora WillisDokumen4 halamanSeventh Grade Language Arts Letter of Introduction Frissora Willisapi-188248147Belum ada peringkat
- Lampiran Heat Stress Dan ThiDokumen2 halamanLampiran Heat Stress Dan ThiRaviBelum ada peringkat
- Nihilism's Challenge to Meaning and ValuesDokumen2 halamanNihilism's Challenge to Meaning and ValuesancorsaBelum ada peringkat
- 6 Bền cơ học ISO 2006-1-2009Dokumen18 halaman6 Bền cơ học ISO 2006-1-2009HIEU HOANG DINHBelum ada peringkat
- Aral2019 Program PortraitDokumen8 halamanAral2019 Program PortraitAldrich OBelum ada peringkat
- Marketing Theory and PracticeDokumen18 halamanMarketing Theory and PracticeRohit SahniBelum ada peringkat
- Nilsen J Top 4000 Vocabulary Test For ThaiDokumen9 halamanNilsen J Top 4000 Vocabulary Test For ThaiplopBelum ada peringkat
- The Pipelined RiSC-16 ComputerDokumen9 halamanThe Pipelined RiSC-16 Computerkb_lu232Belum ada peringkat
- How to Summarize in 9 StepsDokumen4 halamanHow to Summarize in 9 StepsSaad TariqBelum ada peringkat
- AltimeterDokumen8 halamanAltimeterwolffoxxxBelum ada peringkat
- Aep Lesson Plan 3 ClassmateDokumen7 halamanAep Lesson Plan 3 Classmateapi-453997044Belum ada peringkat
- Exchange 2013 High Availability and Site ResilienceDokumen4 halamanExchange 2013 High Availability and Site ResilienceKhodor AkoumBelum ada peringkat