Anda mungkin juga menyukai
- Soltech Computer Academy PC Know-How: (Networking)Dokumen43 halamanSoltech Computer Academy PC Know-How: (Networking)owen-agboje-79850% (1)
- MCQS WITH KEY ANSWERSDokumen33 halamanMCQS WITH KEY ANSWERSlalith100% (1)
- Ge SSB HBDokumen234 halamanGe SSB HBwpettit_2Belum ada peringkat
- LTE Solution Strategy Overview & Proposal v1.3Dokumen27 halamanLTE Solution Strategy Overview & Proposal v1.3Syukri Muhammad JBelum ada peringkat
- 6WIND-Intel White Paper - Optimized Data Plane Processing Solutions Using The Intel® DPDK v2Dokumen8 halaman6WIND-Intel White Paper - Optimized Data Plane Processing Solutions Using The Intel® DPDK v2ramanj123Belum ada peringkat
- EasymacroDokumen65 halamanEasymacroRZBelum ada peringkat
- Air 3246 B66Dokumen4 halamanAir 3246 B66Noel FelicianoBelum ada peringkat
- Cisco Data Center Spine-And-Leaf Architecture - Design Overview White Paper - CiscoDokumen32 halamanCisco Data Center Spine-And-Leaf Architecture - Design Overview White Paper - CiscoSalman AlfarisiBelum ada peringkat
- Google NetworkDokumen15 halamanGoogle Networkanthony saddingtonBelum ada peringkat
- DSP-1 (Intro) (S)Dokumen77 halamanDSP-1 (Intro) (S)karthik0433Belum ada peringkat
- An Introduction to SDN Intent Based NetworkingDari EverandAn Introduction to SDN Intent Based NetworkingPenilaian: 5 dari 5 bintang5/5 (1)
- 8600 Smart Routers SR5.0 Service Pack 2 Embedded Software Release NotesDokumen48 halaman8600 Smart Routers SR5.0 Service Pack 2 Embedded Software Release NotesMauro GuañoBelum ada peringkat
- Cisco Overlay TechnologyDokumen19 halamanCisco Overlay TechnologyRajatBelum ada peringkat
- 3GPP TS 27.007 V14.4.0Dokumen347 halaman3GPP TS 27.007 V14.4.0Nguyên PhongBelum ada peringkat
- Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google's Datacenter NetworkDokumen10 halamanJupiter Rising: A Decade of Clos Topologies and Centralized Control in Google's Datacenter Networkthsilva85Belum ada peringkat
- Idc Ethernet Fabric WPDokumen10 halamanIdc Ethernet Fabric WPthatseasy123Belum ada peringkat
- ccr05 4dDokumen12 halamanccr05 4djanuarclBelum ada peringkat
- Data Center NetworkingDokumen5 halamanData Center NetworkingIvan CappilloBelum ada peringkat
- Comparison of Caching Strategies in Modern Cellular Backhaul NetworksDokumen14 halamanComparison of Caching Strategies in Modern Cellular Backhaul Networkskostas_ntougias5453Belum ada peringkat
- Resource Literature ReviewDokumen5 halamanResource Literature ReviewpriyaBelum ada peringkat
- Functional Enhancements of Cooperative Session Control For "Minimum Core" ArchitectureDokumen9 halamanFunctional Enhancements of Cooperative Session Control For "Minimum Core" ArchitectureKaan Avşar AsanBelum ada peringkat
- Data Center Switching Solutions White PaperDokumen15 halamanData Center Switching Solutions White PaperBon Tran HongBelum ada peringkat
- Software Defined Network For Data Center Using Open Flow ProtocolDokumen5 halamanSoftware Defined Network For Data Center Using Open Flow ProtocolInnovative Research PublicationsBelum ada peringkat
- Open Core System WhitepaperDokumen12 halamanOpen Core System Whitepapersubin4bslBelum ada peringkat
- VIKASYS Java Proj With Abstract 2011Dokumen12 halamanVIKASYS Java Proj With Abstract 2011vijayabaskar1Belum ada peringkat
- Hakir I 2014Dokumen31 halamanHakir I 2014Eduar MartínezBelum ada peringkat
- Scalable and Cost-Effective Interconnection of Data-Center Servers Using Dual Server PortsDokumen13 halamanScalable and Cost-Effective Interconnection of Data-Center Servers Using Dual Server PortsnvadadaBelum ada peringkat
- Latency Minimization GlobecomDokumen6 halamanLatency Minimization GlobecomWESLEY GERALDO SAMPAIO DA NOBREGABelum ada peringkat
- Cluster Computing: DATE: 28 November 2013Dokumen32 halamanCluster Computing: DATE: 28 November 2013Hasan BadirBelum ada peringkat
- Dynamic Load Balancing Assisted Optimized Access ControlDokumen15 halamanDynamic Load Balancing Assisted Optimized Access Controlmelazem rymBelum ada peringkat
- White Paper - Link AggregationDokumen22 halamanWhite Paper - Link Aggregationschumi12Belum ada peringkat
- RoutingArchitecture WPDokumen9 halamanRoutingArchitecture WPMozn Nader AhmedBelum ada peringkat
- FYP ReportDokumen27 halamanFYP ReportHassan ShakoorBelum ada peringkat
- A Metering Infrastructure For Heterogenous Mobile NetworksDokumen8 halamanA Metering Infrastructure For Heterogenous Mobile NetworksLuisa CatalinaBelum ada peringkat
- Cloud Computing and VirtualizationDokumen14 halamanCloud Computing and Virtualizationmanmeet singh tutejaBelum ada peringkat
- On Routing Schemes For Switch-Based In-Vehicle Networks: Shuhui Yang, Wei Li, and Wei ZhaoDokumen15 halamanOn Routing Schemes For Switch-Based In-Vehicle Networks: Shuhui Yang, Wei Li, and Wei ZhaoAlex ParampampamBelum ada peringkat
- Survey of Game Theory and Future Trends For Applications in Emerging Wireless Data Communication Networks PDFDokumen50 halamanSurvey of Game Theory and Future Trends For Applications in Emerging Wireless Data Communication Networks PDFmayukhwebBelum ada peringkat
- Research Paper On LanDokumen6 halamanResearch Paper On Lanc9kb0esz100% (1)
- C096 Data Center High-Speed Migration WP110615 May 17Dokumen8 halamanC096 Data Center High-Speed Migration WP110615 May 17Jesús OdilonBelum ada peringkat
- Root FiletypeDokumen18 halamanRoot Filetypejtsk2Belum ada peringkat
- A Comparative Analysis of Packet Scheduling Schemes For Multimedia Services in LTE NetworksDokumen6 halamanA Comparative Analysis of Packet Scheduling Schemes For Multimedia Services in LTE NetworksEliteSchool MonastirBelum ada peringkat
- DesktopDokumen23 halamanDesktopchel mingajoBelum ada peringkat
- High Performence SDWLANDokumen21 halamanHigh Performence SDWLANadroidtivi178Belum ada peringkat
- Unit - 1: Cloud Architecture and ModelDokumen9 halamanUnit - 1: Cloud Architecture and ModelRitu SrivastavaBelum ada peringkat
- Software Defined Networking Basics: 1 Motivation For SDNDokumen9 halamanSoftware Defined Networking Basics: 1 Motivation For SDNNguyễn Hữu DuyBelum ada peringkat
- ACG - Economic Benefits of Automating Capacity Optimization in IP Networks QxfR0IVDokumen12 halamanACG - Economic Benefits of Automating Capacity Optimization in IP Networks QxfR0IVkoteshbabuBelum ada peringkat
- Written by Jun Ho Bahn (Jbahn@uci - Edu) : Overview of Network-on-ChipDokumen5 halamanWritten by Jun Ho Bahn (Jbahn@uci - Edu) : Overview of Network-on-ChipMitali DixitBelum ada peringkat
- Exercise 1 LAN DesignDokumen5 halamanExercise 1 LAN Designmysticman0628Belum ada peringkat
- Grid Computing 1Dokumen11 halamanGrid Computing 1DannyBelum ada peringkat
- Traffic Isolation and Network Resource Sharing For Performance Control in GridsDokumen6 halamanTraffic Isolation and Network Resource Sharing For Performance Control in Gridsmax37Belum ada peringkat
- DC Caves 20210Dokumen7 halamanDC Caves 20210aluranaBelum ada peringkat
- A Clean Slate 4D Approach To Network Control and ManagementDokumen12 halamanA Clean Slate 4D Approach To Network Control and ManagementFaheem UllahBelum ada peringkat
- CCNA3 Study GuideDokumen42 halamanCCNA3 Study Guidesoma45100% (1)
- Networking QandADokumen24 halamanNetworking QandAeng_seng_lim3436Belum ada peringkat
- Davids Ieee Hldvt02Dokumen6 halamanDavids Ieee Hldvt02sujeto_1Belum ada peringkat
- AST 0085351 Wan Optimization WhitepaperDokumen8 halamanAST 0085351 Wan Optimization WhitepaperJohn SarlangaBelum ada peringkat
- Abstracted Network For IotDokumen32 halamanAbstracted Network For Iotangelperez25Belum ada peringkat
- LTE Wireless Virtualization and Spectrum Management: Yasir Zaki, Liang Zhao, Carmelita Goerg and Andreas Timm-GielDokumen6 halamanLTE Wireless Virtualization and Spectrum Management: Yasir Zaki, Liang Zhao, Carmelita Goerg and Andreas Timm-GielselfscorpionBelum ada peringkat
- Grid ComputingDokumen12 halamanGrid ComputingMohammad IrfanBelum ada peringkat
- WP2018 5G Transport TelemetryDokumen5 halamanWP2018 5G Transport TelemetryMuhammad UsmanBelum ada peringkat
- Multiple Layer Design For Mass Data Transmission Against Channel Congestion in IotDokumen21 halamanMultiple Layer Design For Mass Data Transmission Against Channel Congestion in IotLal SinghBelum ada peringkat
- Peer-to-Peer File Sharing Over Wireless Mesh NetworksDokumen6 halamanPeer-to-Peer File Sharing Over Wireless Mesh NetworksAmine KSBelum ada peringkat
- NXT Generation CellularDokumen17 halamanNXT Generation Cellularreynaldo12Belum ada peringkat
- Elysium Technologies Private Limited: Churn-Resilient Protocol For Massive Data Dissemination in P2P NetworksDokumen35 halamanElysium Technologies Private Limited: Churn-Resilient Protocol For Massive Data Dissemination in P2P Networkssunda_passBelum ada peringkat
- WhitepaperDokumen27 halamanWhitepaperJeremiah Ogonna JohnBelum ada peringkat
- Paper Lte SCTP Fast PathDokumen7 halamanPaper Lte SCTP Fast Pathهيثم الشرجبيBelum ada peringkat
- Network TransformationDokumen6 halamanNetwork TransformationMumtaz AhmadBelum ada peringkat
- Dell/EMC SAN Configurations: Designing and OptimizingDokumen5 halamanDell/EMC SAN Configurations: Designing and OptimizingTaraka Ramarao MBelum ada peringkat
- Intro To XtremIO ArrayDokumen0 halamanIntro To XtremIO ArrayTaraka Ramarao MBelum ada peringkat
- FC Vs EthernetDokumen1 halamanFC Vs EthernetTaraka Ramarao MBelum ada peringkat
- DevfsadmDokumen3 halamanDevfsadmTaraka Ramarao MBelum ada peringkat
- AIX-ODM-Delete Hdisk From ODMDokumen5 halamanAIX-ODM-Delete Hdisk From ODMTaraka Ramarao MBelum ada peringkat
- AIX EfixDokumen6 halamanAIX EfixTaraka Ramarao MBelum ada peringkat
- Windows XP Short KeysDokumen4 halamanWindows XP Short KeysmaheshrvrBelum ada peringkat
- HACMP Installation PrerequisitesDokumen2 halamanHACMP Installation PrerequisitesTaraka Ramarao MBelum ada peringkat
- AIX-ODM-Delete Hdisk From ODMDokumen5 halamanAIX-ODM-Delete Hdisk From ODMTaraka Ramarao MBelum ada peringkat
- SM G928V Tshoo 7 1 PDFDokumen120 halamanSM G928V Tshoo 7 1 PDFRafael Ardila DazaBelum ada peringkat
- VHF/UHF TV Modulator Elektor January 1985: The LayoutDokumen4 halamanVHF/UHF TV Modulator Elektor January 1985: The LayoutingaderlinBelum ada peringkat
- UMTS RAN Dimensioning Guidelines - Nokia - v1.5Dokumen31 halamanUMTS RAN Dimensioning Guidelines - Nokia - v1.5SABER1980Belum ada peringkat
- A Gateway For Managing Traffic of Bare-Metal IoT HoneypotDokumen12 halamanA Gateway For Managing Traffic of Bare-Metal IoT HoneypotCoder CoderBelum ada peringkat
- 04 GSM Power Control ISSUE1.0Dokumen59 halaman04 GSM Power Control ISSUE1.0mespinoza676Belum ada peringkat
- Canais 1Dokumen12 halamanCanais 1Otavio LacerdaBelum ada peringkat
- Mirici E1t1 2.0 MNDokumen108 halamanMirici E1t1 2.0 MNalexf rodBelum ada peringkat
- Wardriving, A Target Rich Tool: Paul E Manning Cpre 537: Wireless Security Spring 2013 DistanceDokumen23 halamanWardriving, A Target Rich Tool: Paul E Manning Cpre 537: Wireless Security Spring 2013 DistanceBob ChanBelum ada peringkat
- Quanta Zd1 Re SchematicsDokumen38 halamanQuanta Zd1 Re SchematicsPREVISTOBelum ada peringkat
- Silver Peak Deployment Diagrams Visio AfDokumen20 halamanSilver Peak Deployment Diagrams Visio AfThien An PhanBelum ada peringkat
- UC Software 4 1 0 Administrators GuideDokumen621 halamanUC Software 4 1 0 Administrators GuideDavid ZambranoBelum ada peringkat
- MCWC GTU Study Material Presentations Unit-1 25072021030749PMDokumen70 halamanMCWC GTU Study Material Presentations Unit-1 25072021030749PMjigneshBelum ada peringkat
- HTTP WWW - Microwaves101.com Encyclopedia Receivers SuperhetDokumen10 halamanHTTP WWW - Microwaves101.com Encyclopedia Receivers SuperhetheadupBelum ada peringkat
- Programming Meridian SL1 PBXDokumen8 halamanProgramming Meridian SL1 PBXNikola StojanoskiBelum ada peringkat
- PRINT - Service Manuals - Service Manual MC Kinley Eu GD 13 06 2019Dokumen73 halamanPRINT - Service Manuals - Service Manual MC Kinley Eu GD 13 06 2019Sebastian PettersBelum ada peringkat
- RAN Feature Documentation RAN20.1 - 05 20190118145943Dokumen62 halamanRAN Feature Documentation RAN20.1 - 05 20190118145943Aleksandar PanicBelum ada peringkat
- 1-4 TCP-IP ModelDokumen4 halaman1-4 TCP-IP ModelDragan StančevBelum ada peringkat
- Computer Network Lesson Plan - UpdatedDokumen2 halamanComputer Network Lesson Plan - UpdatedAmit Prakash SenBelum ada peringkat
- Hydrology: Ott HydrosystemsDokumen4 halamanHydrology: Ott HydrosystemsCesc MezaBelum ada peringkat
- ACKNOWLEDGEMENTDokumen23 halamanACKNOWLEDGEMENTbhupinsharma3186Belum ada peringkat
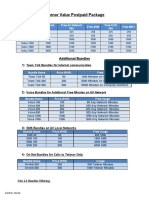
- Telenor Value Postpaid PackageDokumen3 halamanTelenor Value Postpaid PackageImeNBelum ada peringkat
- CSS G10 Q1 - Wk4 - Creating Ethernet CableDokumen11 halamanCSS G10 Q1 - Wk4 - Creating Ethernet CableBryce PandaanBelum ada peringkat