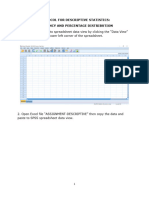
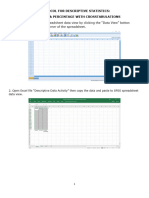
Anda mungkin juga menyukai
- Statistics For Computing II COM 216 PDFDokumen27 halamanStatistics For Computing II COM 216 PDFAdesanya Olatunbosun83% (6)
- SPSSNotesDokumen9 halamanSPSSNotesshahid Ali100% (1)
- Spss and Statistics GuideDokumen28 halamanSpss and Statistics GuideFethim Munshi100% (1)
- Learn How To: 1. Enter Data: Basics of SPSSDokumen13 halamanLearn How To: 1. Enter Data: Basics of SPSSDimas Apri SaputraBelum ada peringkat
- Sta I06 Lecture NoteDokumen29 halamanSta I06 Lecture NoteperfectNjaBelum ada peringkat
- 1333355396testing For Normality Using SPSSDokumen19 halaman1333355396testing For Normality Using SPSSm_ridwan_aBelum ada peringkat
- Biostatistics (HS167) Lab Manual: # Variable Name Variable Label Codes and Parameters (Dots Represent Missing Data)Dokumen15 halamanBiostatistics (HS167) Lab Manual: # Variable Name Variable Label Codes and Parameters (Dots Represent Missing Data)Raj Kumar SoniBelum ada peringkat
- Laboratory Activity 1: Basic Concepts in BiostatisticsDokumen86 halamanLaboratory Activity 1: Basic Concepts in BiostatisticsAngelica Camille B. AbaoBelum ada peringkat
- Computer Assignment PGP 2013 15Dokumen2 halamanComputer Assignment PGP 2013 15Abhilash Mulakala100% (1)
- 2010 - User Guide CSPRO Data Entry and Analysis For Implementers of USAID Poverty Assessment Tools - UNAIDS PDFDokumen25 halaman2010 - User Guide CSPRO Data Entry and Analysis For Implementers of USAID Poverty Assessment Tools - UNAIDS PDFArnoldo FurtadoBelum ada peringkat
- Statistical Analysis in ExcelDokumen51 halamanStatistical Analysis in ExcelLeo Zeren LucasBelum ada peringkat
- Tutorial #5: Analyzing Ranking Data: Bank Segmentation ExampleDokumen19 halamanTutorial #5: Analyzing Ranking Data: Bank Segmentation ExamplejanineBelum ada peringkat
- Guide For SPSS For Windows: I. Using The Data EditorDokumen16 halamanGuide For SPSS For Windows: I. Using The Data EditorFabio Luis BusseBelum ada peringkat
- Research Methadology Lab FileDokumen78 halamanResearch Methadology Lab FileSyed HassanBelum ada peringkat
- Spss NotesDokumen16 halamanSpss NotesAnushya JayendranBelum ada peringkat
- SPSS: Descriptive and Inferential Statistics: For WindowsDokumen34 halamanSPSS: Descriptive and Inferential Statistics: For Windowslekha1997Belum ada peringkat
- Sociology 357-SPSS Survey Analysis InstructionsDokumen7 halamanSociology 357-SPSS Survey Analysis InstructionsarunkushvahaBelum ada peringkat
- Prepared By: Kutoya Kusse GemedeDokumen13 halamanPrepared By: Kutoya Kusse GemedekutoyaBelum ada peringkat
- SPSS Course Session II: Describing DataDokumen12 halamanSPSS Course Session II: Describing DataaltleoBelum ada peringkat
- Thesistools Excel SpssDokumen5 halamanThesistools Excel Spsselizabethsnyderdesmoines100% (2)
- How To Use A Statistical Package: Appendix EDokumen17 halamanHow To Use A Statistical Package: Appendix EAnantha NagBelum ada peringkat
- Abhinn - Spss Lab FileDokumen67 halamanAbhinn - Spss Lab FilevikrambediBelum ada peringkat
- Assiment 2Dokumen4 halamanAssiment 2rjjat2111Belum ada peringkat
- Statistical Package For Social Science: What Are Statistics?Dokumen22 halamanStatistical Package For Social Science: What Are Statistics?suba pBelum ada peringkat
- Introduction To Ihstat Software: (Required For Assignment 3)Dokumen15 halamanIntroduction To Ihstat Software: (Required For Assignment 3)André Santos100% (1)
- Tutorial 4Dokumen6 halamanTutorial 4RR886Belum ada peringkat
- Psychology 250 - Homework 2 - Page 1Dokumen2 halamanPsychology 250 - Homework 2 - Page 1Xandre Dmitri ClementsmithBelum ada peringkat
- Descriptives Frequency Percentage ProtocolDokumen11 halamanDescriptives Frequency Percentage ProtocolHazel PacisBelum ada peringkat
- Spss Notes by AsprabhuDokumen38 halamanSpss Notes by AsprabhuRemya Nair100% (1)
- Module 2 Introduction To SPSS - WordDokumen17 halamanModule 2 Introduction To SPSS - WordJordine UmayamBelum ada peringkat
- Basic ExcelDokumen14 halamanBasic Excelzuhaibmaher04Belum ada peringkat
- Research Methodology Lab FileDokumen77 halamanResearch Methodology Lab FileSyed HassanBelum ada peringkat
- SPSS Basics ManualDokumen25 halamanSPSS Basics ManualAlfredBakChoiBelum ada peringkat
- Spss ExercisesDokumen13 halamanSpss ExercisesEbenezerBelum ada peringkat
- Lesson 3Dokumen22 halamanLesson 3camilleescote562Belum ada peringkat
- Testing For Normality Using SPSSDokumen12 halamanTesting For Normality Using SPSSGazal GuptaBelum ada peringkat
- Testing For Normality Using SPSS PDFDokumen12 halamanTesting For Normality Using SPSS PDFΧρήστος Ντάνης100% (1)
- RM Lab File Harpreet Kaur CombinedDokumen124 halamanRM Lab File Harpreet Kaur CombinedSaurav SharmaBelum ada peringkat
- SPSS - GuidelinesDokumen62 halamanSPSS - GuidelinesShiny VincentBelum ada peringkat
- Note - SPSS For Customer AnalysisDokumen18 halamanNote - SPSS For Customer Analysisصالح الشبحيBelum ada peringkat
- SPSS ExtractDokumen5 halamanSPSS ExtractakinBelum ada peringkat
- Chap2 SPSSDokumen6 halamanChap2 SPSSPallavi PatelBelum ada peringkat
- Psychology 311 - Introduction To Statistics Lab Manual: Diane Lane Washington State University VancouverDokumen34 halamanPsychology 311 - Introduction To Statistics Lab Manual: Diane Lane Washington State University VancouverdodgersgayBelum ada peringkat
- Buku SPSS CompleteDokumen72 halamanBuku SPSS Completeb6788Belum ada peringkat
- Application of SPSS in Research WritingDokumen77 halamanApplication of SPSS in Research WritingKaren Joy SabladaBelum ada peringkat
- Lectures On Spss 2010Dokumen94 halamanLectures On Spss 2010Superstar_13Belum ada peringkat
- KoboToolbox Excel Data Analyser - User Guide v01 140925small - DistDokumen9 halamanKoboToolbox Excel Data Analyser - User Guide v01 140925small - Distmaratus sholikahBelum ada peringkat
- How To Analyze Frequency Distribution, Cross-Tabulation and T-Test (One Sample, Paired Sample and Independent Sample) by Using SPSS?Dokumen4 halamanHow To Analyze Frequency Distribution, Cross-Tabulation and T-Test (One Sample, Paired Sample and Independent Sample) by Using SPSS?Many_Maryy22Belum ada peringkat
- Descriptives - Frequency Percentage With Crosstabs ProtocolDokumen8 halamanDescriptives - Frequency Percentage With Crosstabs ProtocolHazel PacisBelum ada peringkat
- SPSS TrainingDokumen22 halamanSPSS TrainingDesiree D.V. AgcaoiliBelum ada peringkat
- Note - SPSS For Customer Analysis 2018Dokumen22 halamanNote - SPSS For Customer Analysis 2018Avinash KumarBelum ada peringkat
- CHAPTER 4: Descriptive Statistics - Data Presentation: ObjectivesDokumen14 halamanCHAPTER 4: Descriptive Statistics - Data Presentation: ObjectivesSteffany RoqueBelum ada peringkat
- Sample RM File PDFDokumen39 halamanSample RM File PDFbf9wk4bvswBelum ada peringkat
- Practical FileDokumen57 halamanPractical FileISHANJALI MADAAN 219005Belum ada peringkat
- Using Excel For Analysing Survey DataDokumen28 halamanUsing Excel For Analysing Survey DatacristiBelum ada peringkat
- IBM SPSS Statistics 23 Part 1 - Descriptive StatisticsDokumen18 halamanIBM SPSS Statistics 23 Part 1 - Descriptive StatisticsRitesh SrivastavaBelum ada peringkat
- RM FileDokumen40 halamanRM FileAniket SinghBelum ada peringkat
- SPSS AppendixDokumen17 halamanSPSS AppendixFeven SiumBelum ada peringkat
- Cluster Synchronization With CsyncDokumen10 halamanCluster Synchronization With CsyncOleksiy Kovyrin100% (2)
- BOOX NovaAir User Manual (2021126)Dokumen181 halamanBOOX NovaAir User Manual (2021126)Bek Zhe Hao Lucas (Nhps)Belum ada peringkat
- MDVR Player ManualDokumen18 halamanMDVR Player ManualMinh Pham NgocBelum ada peringkat
- S2&S11 Software UpgradeDokumen55 halamanS2&S11 Software UpgradeEliezer0% (1)
- Timebox ManualDokumen42 halamanTimebox ManualFasian Al'fasir Fharrad FarrerBelum ada peringkat
- New Features Dba9i PDFDokumen400 halamanNew Features Dba9i PDFbenben08Belum ada peringkat
- Genymotion 2.6.0 User GuideDokumen62 halamanGenymotion 2.6.0 User GuideRahim KamilBelum ada peringkat
- Mike 21 Flow Model FMDokumen144 halamanMike 21 Flow Model FMAlvaro LemosBelum ada peringkat
- How To Delete Old Backups From The Offline Device - v1.1Dokumen7 halamanHow To Delete Old Backups From The Offline Device - v1.1David ŽabakBelum ada peringkat
- OpenShift Container Platform-4.6-Installing On OpenStack-en-USDokumen178 halamanOpenShift Container Platform-4.6-Installing On OpenStack-en-USChinni MunniBelum ada peringkat
- Sitecore Interview Questions PDFDokumen8 halamanSitecore Interview Questions PDFneotheerrorBelum ada peringkat
- Oracle HCM Cloud Whats New For R8Dokumen195 halamanOracle HCM Cloud Whats New For R8KishorKongaraBelum ada peringkat
- 02 Linux History PDFDokumen25 halaman02 Linux History PDFJamesBelum ada peringkat
- (13-74) Galaxy Note3 Unlocking For Reactivation Lock Guide Rev 5 0Dokumen5 halaman(13-74) Galaxy Note3 Unlocking For Reactivation Lock Guide Rev 5 0Dhari PissettiBelum ada peringkat
- Spo QS PDFDokumen6 halamanSpo QS PDFEric HamisiBelum ada peringkat
- ManualTruTopsCalculate V8.4.0 EngDokumen194 halamanManualTruTopsCalculate V8.4.0 EngveraBelum ada peringkat
- Electricity Bill Automation (ICT) Problem StatementDokumen11 halamanElectricity Bill Automation (ICT) Problem StatementDulam TatajiBelum ada peringkat
- Flux2018 NewFeatures PDFDokumen110 halamanFlux2018 NewFeatures PDFrupalchopade5163Belum ada peringkat
- InstallGuide 4.5Dokumen4 halamanInstallGuide 4.5Ashraf Gomah Mohamed ElshamandyBelum ada peringkat
- BSC (H) Sem 3 Guidelines July 2012Dokumen17 halamanBSC (H) Sem 3 Guidelines July 2012Priyanka D SinghBelum ada peringkat
- Backbase Deployment GuideDokumen16 halamanBackbase Deployment GuidedondarwinBelum ada peringkat
- SPSS Smart Viewer Evaluation Copy Step-by-Step Evaluation GuideDokumen4 halamanSPSS Smart Viewer Evaluation Copy Step-by-Step Evaluation GuideRoxy RoxaBelum ada peringkat
- SLD Migration and GW - Acl - Mode - SAP BlogsDokumen18 halamanSLD Migration and GW - Acl - Mode - SAP BlogsJagadish BabuBelum ada peringkat
- MAGNET Field v1.0 - Help Manual Rev. A 1000411-01-2Dokumen338 halamanMAGNET Field v1.0 - Help Manual Rev. A 1000411-01-2Andika MaliekBelum ada peringkat
- Ac 500Dokumen188 halamanAc 500max_ingBelum ada peringkat
- Grade 10 q2 Tle-Cssncii LasDokumen75 halamanGrade 10 q2 Tle-Cssncii Lasmichelle divinaBelum ada peringkat
- Mengetik 10 JariDokumen9 halamanMengetik 10 JariFaisal LuzanBelum ada peringkat
- When Good Disks Go BadDokumen33 halamanWhen Good Disks Go BadBob2345Belum ada peringkat
- A-Tools Help ENDokumen32 halamanA-Tools Help ENDelaya Ningsi LohoBelum ada peringkat
- 4.2.7 Lab - Getting Familiar With The Linux ShellDokumen8 halaman4.2.7 Lab - Getting Familiar With The Linux ShellTran Truong Giang (K16HCM)Belum ada peringkat