Anda mungkin juga menyukai
- Performance Comparison of Sorting Algorithms Based on ComplexityDokumen5 halamanPerformance Comparison of Sorting Algorithms Based on ComplexityanvinderBelum ada peringkat
- 2669 Maximal Margin Labeling For Multi Topic Text CategorizationDokumen8 halaman2669 Maximal Margin Labeling For Multi Topic Text CategorizationAnurag SharmaBelum ada peringkat
- Daa SDokumen6 halamanDaa Skolasandeep555Belum ada peringkat
- DSA Lecture 1 Intro Algorithms Week Feb 18-22Dokumen11 halamanDSA Lecture 1 Intro Algorithms Week Feb 18-22M8R-ya0sm5Belum ada peringkat
- 6th Sem Algorithm (c-14) AnswerDokumen15 halaman6th Sem Algorithm (c-14) Answerrituprajna2004Belum ada peringkat
- Lecture Notes On Hash Tables: 15-122: Principles of Imperative Computation Frank Pfenning, Rob Simmons February 28, 2013Dokumen7 halamanLecture Notes On Hash Tables: 15-122: Principles of Imperative Computation Frank Pfenning, Rob Simmons February 28, 2013Munavalli Matt K SBelum ada peringkat
- Thresholded Tabulation in A Fuzzy Logic SettingDokumen16 halamanThresholded Tabulation in A Fuzzy Logic SettingIt's RohanBelum ada peringkat
- Genetic Algorithm Tutorial Covers Canonical Form and VariantsDokumen41 halamanGenetic Algorithm Tutorial Covers Canonical Form and VariantsPrempal TomarBelum ada peringkat
- CAB301 Levitin Ch2 PDFDokumen57 halamanCAB301 Levitin Ch2 PDFAki Su'aBelum ada peringkat
- Notes On Domain Theory by MisloveDokumen33 halamanNotes On Domain Theory by MislovefturingBelum ada peringkat
- Daa Q&aDokumen8 halamanDaa Q&aAryan PrasadBelum ada peringkat
- Lec 5Dokumen6 halamanLec 5Abraham woldeBelum ada peringkat
- Computer Science Notes: Algorithms and Data StructuresDokumen21 halamanComputer Science Notes: Algorithms and Data StructuresMuhammedBelum ada peringkat
- UntitledDokumen177 halamanUntitledSimon RaphaelBelum ada peringkat
- Jim DSA QuestionsDokumen26 halamanJim DSA QuestionsTudor CiotloșBelum ada peringkat
- A Genetic Algorithm TutorialDokumen37 halamanA Genetic Algorithm TutorialGabriel HumpireBelum ada peringkat
- Programming in The Lambda-Calculus: From Church To Scott and BackDokumen14 halamanProgramming in The Lambda-Calculus: From Church To Scott and BackAndrés OrtegaBelum ada peringkat
- 1 Preliminaries: Data Structures and AlgorithmsDokumen21 halaman1 Preliminaries: Data Structures and AlgorithmsPavan RsBelum ada peringkat
- AA0103C0102Dokumen97 halamanAA0103C0102Jose Daniel Amador SalasBelum ada peringkat
- Unit 4Dokumen18 halamanUnit 4Priya KumariBelum ada peringkat
- How algorithms solve problems efficientlyDokumen6 halamanHow algorithms solve problems efficientlyabdullah Mamun KhanBelum ada peringkat
- What is an algorithm and why is it neededDokumen6 halamanWhat is an algorithm and why is it neededabdullah Mamun KhanBelum ada peringkat
- Merge Sort: Divide and ConquerDokumen18 halamanMerge Sort: Divide and ConquervinithBelum ada peringkat
- TNT - A Statistical Part-Of-Speech Tagger: T I I 1 I 2 I I T+1 TDokumen8 halamanTNT - A Statistical Part-Of-Speech Tagger: T I I 1 I 2 I I T+1 Ttejshahi1Belum ada peringkat
- Lect 0825Dokumen5 halamanLect 0825blabla9999999Belum ada peringkat
- Integer Programming and Cryptography BrokenDokumen6 halamanInteger Programming and Cryptography Brokenanitadas19Belum ada peringkat
- The Riemann Zeta-FunctionDokumen11 halamanThe Riemann Zeta-FunctionJuan Pastor RamosBelum ada peringkat
- Data Structures and Algorithms Sheet #4 Linked List: ProblemsDokumen2 halamanData Structures and Algorithms Sheet #4 Linked List: Problemsmahmoud emadBelum ada peringkat
- An Algorithmic Approach to Nonlinear Analysis and OptimizationDari EverandAn Algorithmic Approach to Nonlinear Analysis and OptimizationBelum ada peringkat
- Algo Syllabus NewDokumen2 halamanAlgo Syllabus NewRaj EinsteinBelum ada peringkat
- 1 Linear Search: Algorithm Input: Output: While and Do If Then Return Else ReturnDokumen5 halaman1 Linear Search: Algorithm Input: Output: While and Do If Then Return Else ReturnbayentapasBelum ada peringkat
- Queueing Systems Olume I Theory: J SonsDokumen17 halamanQueueing Systems Olume I Theory: J SonsAjay TripathiBelum ada peringkat
- Analysis of Algorithms, A Case Study: Determinants of Matrices With Polynomial EntriesDokumen10 halamanAnalysis of Algorithms, A Case Study: Determinants of Matrices With Polynomial EntriesNiltonJuniorBelum ada peringkat
- Space and Time Trade OffDokumen8 halamanSpace and Time Trade OffSheshnath HadbeBelum ada peringkat
- FMTbook Chapter3Dokumen106 halamanFMTbook Chapter3S A M CBelum ada peringkat
- DAA NOTES: DATA, ALGORITHMS, GREEDY METHODSDokumen9 halamanDAA NOTES: DATA, ALGORITHMS, GREEDY METHODSswatiBelum ada peringkat
- Lab 1Dokumen11 halamanLab 1RanaAshBelum ada peringkat
- Modeling and Simulation, 5FY095, Fall 2009 Lecture Notes For Ordinary Differential Equations First Revision: 2009/09/8Dokumen42 halamanModeling and Simulation, 5FY095, Fall 2009 Lecture Notes For Ordinary Differential Equations First Revision: 2009/09/8Chernet TugeBelum ada peringkat
- Lecture 1: Problems, Models, and ResourcesDokumen9 halamanLecture 1: Problems, Models, and ResourcesAlphaBelum ada peringkat
- Sorting Algorithms With Python3 PDFDokumen37 halamanSorting Algorithms With Python3 PDFmarkBelum ada peringkat
- Sorting Algorithms With Python3122Dokumen37 halamanSorting Algorithms With Python3122markBelum ada peringkat
- Sorting Algorithms With Python3 PDFDokumen37 halamanSorting Algorithms With Python3 PDFmarkBelum ada peringkat
- Sorting Algorithms With Python3 PDFDokumen37 halamanSorting Algorithms With Python3 PDFmarkBelum ada peringkat
- Rosen - Elementary Number Theory and Its Applications - 1stDokumen462 halamanRosen - Elementary Number Theory and Its Applications - 1stHunter PattonBelum ada peringkat
- Finding Frequent Items in Data StreamsDokumen11 halamanFinding Frequent Items in Data StreamsIndira PokhrelBelum ada peringkat
- Computational Tractability: The View From Mars: The Problem of Systematically Coping With Computational IntractabilityDokumen25 halamanComputational Tractability: The View From Mars: The Problem of Systematically Coping With Computational IntractabilityssfofoBelum ada peringkat
- SOLUTION MANUAL TITLEDokumen57 halamanSOLUTION MANUAL TITLENapster100% (1)
- Counting Combinations with BijectionsDokumen167 halamanCounting Combinations with Bijectionscaknill1698100% (1)
- IJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchDokumen5 halamanIJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchInternational Journal of computational Engineering research (IJCER)Belum ada peringkat
- Computational Geometry Methods and Applications - ChenDokumen227 halamanComputational Geometry Methods and Applications - ChenAlejandro JimenezBelum ada peringkat
- Lecture NotesDokumen30 halamanLecture NotesDeepak SinghBelum ada peringkat
- Science of Computer Programming: Roland Backhouse, João F. FerreiraDokumen21 halamanScience of Computer Programming: Roland Backhouse, João F. FerreiraELOK YULIA FAIKOHBelum ada peringkat
- Signals and Systems-Chen PDFDokumen417 halamanSignals and Systems-Chen PDFMrdemagallanes100% (1)
- DAA Interview Questions and Answers GuideDokumen9 halamanDAA Interview Questions and Answers GuidePranjal KumarBelum ada peringkat
- Data Structures & Algorithms GuideDokumen61 halamanData Structures & Algorithms GuideMaria Canete100% (1)
- What Are Stacks and QueuesDokumen13 halamanWhat Are Stacks and QueuesrizawanshaikhBelum ada peringkat
- Lovasz Discrete and ContinuousDokumen23 halamanLovasz Discrete and ContinuousVasiliki VelonaBelum ada peringkat
- Lecture 10-Fffcomplexity of AlgorithmsDokumen19 halamanLecture 10-Fffcomplexity of AlgorithmsFrankChenBelum ada peringkat
- Fast MATLAB Optimization GuideDokumen22 halamanFast MATLAB Optimization GuideJandfor Tansfg ErrottBelum ada peringkat
- 8.3.1 CPM SignalsDokumen7 halaman8.3.1 CPM SignalsAli KashiBelum ada peringkat
- Reed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003Dokumen20 halamanReed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003jayant5253100% (1)
- Study Spread Spectrum in Matlab: Wang XiaoyingDokumen4 halamanStudy Spread Spectrum in Matlab: Wang XiaoyingAli KashiBelum ada peringkat
- 3 1 75 JiscDokumen4 halaman3 1 75 JiscAli KashiBelum ada peringkat
- The Applications and Simulation of Adaptive Filter in Speech EnhancementDokumen7 halamanThe Applications and Simulation of Adaptive Filter in Speech EnhancementAli KashiBelum ada peringkat
- Discrete Time PrimerDokumen5 halamanDiscrete Time PrimerarafatasgharBelum ada peringkat
- Introduction To Spread Spectrum CommunicationDokumen7 halamanIntroduction To Spread Spectrum CommunicationAli KashiBelum ada peringkat
- Researchpaper Safe Geo Graphic Location Privacy Scheme in The VANETs Survey Methods and Its LimitationDokumen5 halamanResearchpaper Safe Geo Graphic Location Privacy Scheme in The VANETs Survey Methods and Its LimitationAli KashiBelum ada peringkat
- Study Spread Spectrum in Matlab: Wang XiaoyingDokumen4 halamanStudy Spread Spectrum in Matlab: Wang XiaoyingAli KashiBelum ada peringkat
- An Introduction To Spread-Spectrum CommunicationsDokumen12 halamanAn Introduction To Spread-Spectrum CommunicationsAli KashiBelum ada peringkat
- N5615 1Dokumen31 halamanN5615 1Ali KashiBelum ada peringkat
- Handoff Schemes For Vehicular Ad-Hoc Networks:: A SurveyDokumen6 halamanHandoff Schemes For Vehicular Ad-Hoc Networks:: A SurveyAli KashiBelum ada peringkat
- Day2 03Dokumen31 halamanDay2 03Ali KashiBelum ada peringkat
- Day2 03Dokumen31 halamanDay2 03Ali KashiBelum ada peringkat
- Supp Mat L Absolvo P TimDokumen4 halamanSupp Mat L Absolvo P TimAli KashiBelum ada peringkat
- Direct-write Process 3D Transistors Without LithographyDokumen1 halamanDirect-write Process 3D Transistors Without LithographyAli KashiBelum ada peringkat
- Build A Custom-Printed Circuit Board: Pcbs Aren'T So Hard To Make and Needn'T Break The BankDokumen2 halamanBuild A Custom-Printed Circuit Board: Pcbs Aren'T So Hard To Make and Needn'T Break The BankAli KashiBelum ada peringkat
- 2013-Graph-Based Metrics For Insider Attack Detection in VANET Multihop Data Dissemination Protocols PDFDokumen14 halaman2013-Graph-Based Metrics For Insider Attack Detection in VANET Multihop Data Dissemination Protocols PDFAli KashiBelum ada peringkat
- Reed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003Dokumen20 halamanReed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003jayant5253100% (1)
- Shannon Coding Extensions PDFDokumen139 halamanShannon Coding Extensions PDFAli KashiBelum ada peringkat
- Coding Theory A First CourseDokumen198 halamanCoding Theory A First CourseAilenei RamonaBelum ada peringkat
- Robin PDFDokumen13 halamanRobin PDFAli KashiBelum ada peringkat
- A MATLAB Tutorial: Ed Overman Department of Mathematics The Ohio State UniversityDokumen182 halamanA MATLAB Tutorial: Ed Overman Department of Mathematics The Ohio State UniversityAli KashiBelum ada peringkat
- Reed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003Dokumen20 halamanReed-Muller Codes: Sebastian Raaphorst Carleton University May 9, 2003jayant5253100% (1)
- Reed MulerDokumen6 halamanReed MulerPankaj GoyalBelum ada peringkat
- Shannon Coding Extensions PDFDokumen139 halamanShannon Coding Extensions PDFAli KashiBelum ada peringkat
- DC Motor ModellingDokumen8 halamanDC Motor ModellingAbubakar MannBelum ada peringkat
- Build A Custom-Printed Circuit Board: Pcbs Aren'T So Hard To Make and Needn'T Break The BankDokumen2 halamanBuild A Custom-Printed Circuit Board: Pcbs Aren'T So Hard To Make and Needn'T Break The BankAli KashiBelum ada peringkat
- Virgil AeneidDokumen367 halamanVirgil Aeneidlastoic100% (1)
- Aguerra - Resume 2021 1Dokumen1 halamanAguerra - Resume 2021 1api-547475674Belum ada peringkat
- Past Simple - Present PerfectDokumen5 halamanPast Simple - Present PerfectAnonymous MCobwixBelum ada peringkat
- Case 3:09 CV 01494 MODokumen13 halamanCase 3:09 CV 01494 MOAnonymous HiNeTxLMBelum ada peringkat
- God's Refining Process Removes Character DefectsDokumen5 halamanGod's Refining Process Removes Character DefectsPercen7Belum ada peringkat
- 2021 GSFR General ChecklistDokumen12 halaman2021 GSFR General Checklistapi-584007256Belum ada peringkat
- Thematic Language-Stimulation TherapyDokumen19 halamanThematic Language-Stimulation TherapyPipa Yau100% (1)
- ME8513 & Metrology and Measurements LaboratoryDokumen3 halamanME8513 & Metrology and Measurements LaboratorySakthivel KarunakaranBelum ada peringkat
- Internship ReportDokumen24 halamanInternship ReportFaiz KhanBelum ada peringkat
- Fluid Flow and Kinetics Adam PowellDokumen26 halamanFluid Flow and Kinetics Adam PowellSanki KurliBelum ada peringkat
- Olanzapine Drug StudyDokumen1 halamanOlanzapine Drug StudyJeyser T. Gamutia100% (1)
- Reviewer Constitutional LawDokumen6 halamanReviewer Constitutional LawMoireeGBelum ada peringkat
- Aspen FLARENET Getting StartedDokumen62 halamanAspen FLARENET Getting StartedAde Nurisman100% (7)
- LOGIC - Key Concepts of Propositions, Arguments, Deductive & Inductive ReasoningDokumen83 halamanLOGIC - Key Concepts of Propositions, Arguments, Deductive & Inductive ReasoningMajho Oaggab100% (2)
- Determinants of Cash HoldingsDokumen26 halamanDeterminants of Cash Holdingspoushal100% (1)
- DR Raudhah Ahmadi KNS1633 Engineering Mechanics Civil Engineering, UNIMASDokumen32 halamanDR Raudhah Ahmadi KNS1633 Engineering Mechanics Civil Engineering, UNIMASAriff JasniBelum ada peringkat
- Pathology PLE SamplexDokumen5 halamanPathology PLE SamplexAileen Castillo100% (1)
- As Work: Self Perceptions and Perceptions of Group Climate Predictors of Individual Innovation atDokumen17 halamanAs Work: Self Perceptions and Perceptions of Group Climate Predictors of Individual Innovation atMuqadas KhanBelum ada peringkat
- Page - 1Dokumen18 halamanPage - 1Julian Adam Pagal75% (4)
- Political Science Most Important Questions Part 1 PDFDokumen2 halamanPolitical Science Most Important Questions Part 1 PDFJayateerth KulkarniBelum ada peringkat
- Papal InfallibilityDokumen6 halamanPapal InfallibilityFrancis AkalazuBelum ada peringkat
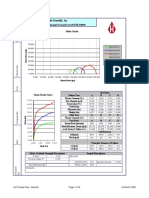
- Humboldt Scientific, Inc.: Normal Stress (Psi)Dokumen9 halamanHumboldt Scientific, Inc.: Normal Stress (Psi)Dilson Loaiza CruzBelum ada peringkat
- Group Project Assignment Imc407Dokumen4 halamanGroup Project Assignment Imc407Anonymous nyN7IVBMBelum ada peringkat
- (Penguin Classics) Chrétien de Troyes, William W. Kibler, Carleton W. Carroll (Transl.) - Arthurian Romances-Penguin Books (1991) PDFDokumen532 halaman(Penguin Classics) Chrétien de Troyes, William W. Kibler, Carleton W. Carroll (Transl.) - Arthurian Romances-Penguin Books (1991) PDFEric S. Giunta100% (6)
- Set-2 Answer? Std10 EnglishDokumen13 halamanSet-2 Answer? Std10 EnglishSaiyam JainBelum ada peringkat
- English Language (1122)Dokumen26 halamanEnglish Language (1122)TD X Mzinda100% (1)
- Shukr Thankfulness To Allah Grade 12Dokumen21 halamanShukr Thankfulness To Allah Grade 12Salman Mohammed AbdullahBelum ada peringkat
- Daß Ich Erkenne, Was Die Welt Im Innersten Zusammenhält (Lines 382-83) So That I Know What Holds The Innermost World TogetherDokumen2 halamanDaß Ich Erkenne, Was Die Welt Im Innersten Zusammenhält (Lines 382-83) So That I Know What Holds The Innermost World TogetherEmanuel MoşmanuBelum ada peringkat
- Comparative Summary of 5 Learning TheoriesDokumen2 halamanComparative Summary of 5 Learning TheoriesMonique Gabrielle Nacianceno AalaBelum ada peringkat