Anda mungkin juga menyukai
- WWW Inia CLDokumen30 halamanWWW Inia CLCristhian Paul Espino CuadrosBelum ada peringkat
- R E - EneroDokumen6 halamanR E - EneroCristhian Paul Espino CuadrosBelum ada peringkat
- METODOLOGIA RRHHDokumen5 halamanMETODOLOGIA RRHHCristhian Paul Espino CuadrosBelum ada peringkat
- AnthonyDokumen12 halamanAnthonyCristhian Paul Espino CuadrosBelum ada peringkat
- Intradevco IndustrialDokumen14 halamanIntradevco IndustrialCristhian Paul Espino CuadrosBelum ada peringkat
- Aplicacion BPM IIDokumen52 halamanAplicacion BPM IICristhian Paul Espino Cuadros100% (1)
- Tesis EspinoDokumen23 halamanTesis EspinoCristhian Paul Espino Cuadros100% (1)
- Vision EstrategicaDokumen2 halamanVision EstrategicaCristhian Paul Espino CuadrosBelum ada peringkat
- BPMN - JaredDokumen4 halamanBPMN - JaredCristhian Paul Espino CuadrosBelum ada peringkat
- Entregable 3 FinalDokumen34 halamanEntregable 3 FinalCristhian Paul Espino CuadrosBelum ada peringkat
- PP Pi 2017 I Formato de Perfil de Proyecto 1Dokumen25 halamanPP Pi 2017 I Formato de Perfil de Proyecto 1Nick Renzo Barzola YauceBelum ada peringkat
- Procesos de RefinacionDokumen24 halamanProcesos de RefinacionBrandon Gonzalez100% (1)
- Ane Grupo1 Investiga3Dokumen12 halamanAne Grupo1 Investiga3Cristhian Paul Espino CuadrosBelum ada peringkat
- Aplicacion BPM IIDokumen52 halamanAplicacion BPM IICristhian Paul Espino Cuadros100% (1)
- Nectar de TunaDokumen41 halamanNectar de TunaCristhian Paul Espino Cuadros0% (1)
- AnthonyDokumen12 halamanAnthonyCristhian Paul Espino CuadrosBelum ada peringkat
- Objetiv OsDokumen1 halamanObjetiv OsCristhian Paul Espino CuadrosBelum ada peringkat
- PP Pi 2017 I Formato de Perfil de Proyecto 1Dokumen24 halamanPP Pi 2017 I Formato de Perfil de Proyecto 1Cristhian Paul Espino CuadrosBelum ada peringkat
- Balotario Parcial Teoria de Decisiones Prof Bruno Puccio Ciclo 2013 01Dokumen28 halamanBalotario Parcial Teoria de Decisiones Prof Bruno Puccio Ciclo 2013 01Alan JavierBelum ada peringkat
- Papers TopicosDokumen15 halamanPapers TopicosCristhian Paul Espino CuadrosBelum ada peringkat
- Plan - 13771 - Manual de Organizacion y Funciones (Parte2) - 2009 PDFDokumen42 halamanPlan - 13771 - Manual de Organizacion y Funciones (Parte2) - 2009 PDFCecilia CoaguilaBelum ada peringkat
- Plan 13038 Mof 2010Dokumen23 halamanPlan 13038 Mof 2010Antonio AntonioBelum ada peringkat
- Ana CurriculumDokumen1 halamanAna CurriculumCristhian Paul Espino CuadrosBelum ada peringkat
- Diagnostico FuncionalDokumen7 halamanDiagnostico FuncionalCristhian Paul Espino CuadrosBelum ada peringkat
- Trabajo para 3PCDokumen1 halamanTrabajo para 3PCCristhian Paul Espino CuadrosBelum ada peringkat
- Objetiv OsDokumen1 halamanObjetiv OsCristhian Paul Espino CuadrosBelum ada peringkat
- MofDokumen86 halamanMofPatricia Ramirez100% (1)
- CELIMADokumen26 halamanCELIMACristhian Paul Espino CuadrosBelum ada peringkat
- Papers TopicosDokumen15 halamanPapers TopicosCristhian Paul Espino CuadrosBelum ada peringkat
- ALINEAMIENTODokumen4 halamanALINEAMIENTOCristhian Paul Espino CuadrosBelum ada peringkat
- Practicas Laboratotio Simulador Redes CISCO PACKET TRACERDokumen29 halamanPracticas Laboratotio Simulador Redes CISCO PACKET TRACERMatthew James BrownBelum ada peringkat
- Es El Diseño o Conjunto de Relaciones Entre Las Partes Que Constituyen Un SistemaDokumen4 halamanEs El Diseño o Conjunto de Relaciones Entre Las Partes Que Constituyen Un Sistemadarien riveraBelum ada peringkat
- Procesador IA-32 - Modo ProtegidoDokumen199 halamanProcesador IA-32 - Modo ProtegidoYer Ko100% (1)
- ABC de Código de BarrasDokumen10 halamanABC de Código de BarrasMaría Del Pilar Urviola FernándezBelum ada peringkat
- Tutorial para Streaming de Video y TelevisionDokumen9 halamanTutorial para Streaming de Video y TelevisionRenne EmmanuelBelum ada peringkat
- Informe Arquitectura DnaDokumen6 halamanInforme Arquitectura DnaErika GyvBelum ada peringkat
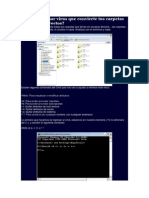
- Como Eliminar Virus Que Convierte Tus Carpetas en Accesos DirectosDokumen4 halamanComo Eliminar Virus Que Convierte Tus Carpetas en Accesos DirectosVickthor VcktBelum ada peringkat
- IngeniumDokumen29 halamanIngeniumseomagoBelum ada peringkat
- Diez Trucos para Acelerar Tu PC DrásticamenteDokumen12 halamanDiez Trucos para Acelerar Tu PC DrásticamenteAmbrosio Nava GuadarramaBelum ada peringkat
- A Modulo 1 CompletoDokumen207 halamanA Modulo 1 CompletoAldo Octavio Rodriguez VeraBelum ada peringkat
- Servidores y Sus CaracteristicasDokumen8 halamanServidores y Sus CaracteristicasAlejandro Martinez TecBelum ada peringkat
- Instalación de Redes Telefónicas ConvergentesDokumen2 halamanInstalación de Redes Telefónicas ConvergentesEmerson Emerson AemersonBelum ada peringkat
- Demanda Segunda EntregaDokumen502 halamanDemanda Segunda EntregaNorberto Florez RamosBelum ada peringkat
- Investigacion AccesDokumen6 halamanInvestigacion AccesAlexis R. CamargoBelum ada peringkat
- Beini VirtualboxDokumen7 halamanBeini VirtualboxIsrael Nava RodríguezBelum ada peringkat
- Configuración Modem Huawei ABA CANTVDokumen7 halamanConfiguración Modem Huawei ABA CANTVErwin Roman Almarza ColinaBelum ada peringkat
- LibreElec en Amlogic BoxDokumen15 halamanLibreElec en Amlogic BoxRicBelum ada peringkat
- Exposición PuertosDokumen18 halamanExposición PuertosElmer Hdez TorresBelum ada peringkat
- Manual de DomóticaDokumen4 halamanManual de DomóticaCreaciones Copyright SL20% (5)
- Módulo 2 PortafolioDokumen8 halamanMódulo 2 PortafoliogabrielBelum ada peringkat
- Framerelay Atm AdslDokumen3 halamanFramerelay Atm AdslNayshaBelum ada peringkat
- Proforma de Camaras Motorizadas Mini PTZDokumen5 halamanProforma de Camaras Motorizadas Mini PTZvictor manuel urquiaga gomezBelum ada peringkat
- Lab Nº4Dokumen11 halamanLab Nº4carlos sanchezBelum ada peringkat
- Método en cascada: ventajas, desventajas y conclusiónDokumen7 halamanMétodo en cascada: ventajas, desventajas y conclusiónJulio RikrdzBelum ada peringkat
- Versiones de ExcelDokumen2 halamanVersiones de ExcelSamuel Isaías López CanulBelum ada peringkat
- Curso FCP Master cableado estructuradoDokumen2 halamanCurso FCP Master cableado estructuradoedgarBelum ada peringkat
- Lab 2Dokumen7 halamanLab 2Miguel SerranoBelum ada peringkat
- Indice Del Manual de Usuario Del Modulo PIC12F508 PDFDokumen16 halamanIndice Del Manual de Usuario Del Modulo PIC12F508 PDFCarlos ArangurenBelum ada peringkat
- Sistema Multiusuario Aspectos Tecnicos U170Dokumen5 halamanSistema Multiusuario Aspectos Tecnicos U170David BrachoBelum ada peringkat
- Autorización Completa API SOAPDokumen39 halamanAutorización Completa API SOAPJonathan Edson LaraBelum ada peringkat