Anda mungkin juga menyukai
- Cheat SheetDokumen2 halamanCheat SheetVarun NagpalBelum ada peringkat
- FormulaDokumen7 halamanFormulaMàddìRèxxShìrshírBelum ada peringkat
- MFE NotesDokumen10 halamanMFE NotesRohit SharmaBelum ada peringkat
- DF (T) DT XDokumen12 halamanDF (T) DT XKevin YuBelum ada peringkat
- CS2 Booklet 7 (Mortality Projection) 2019 FINALDokumen38 halamanCS2 Booklet 7 (Mortality Projection) 2019 FINALAnsh ParmarBelum ada peringkat
- Slides PDFDokumen418 halamanSlides PDFvikasBelum ada peringkat
- Extreme Event Statistics Coursework 1 2013-14Dokumen4 halamanExtreme Event Statistics Coursework 1 2013-14yous123Belum ada peringkat
- Statistics and Probability-Lesson 1Dokumen109 halamanStatistics and Probability-Lesson 1Airene CastañosBelum ada peringkat
- Geometricbrownian PDFDokumen15 halamanGeometricbrownian PDFYeti KapitanBelum ada peringkat
- MFE FormulasDokumen7 halamanMFE FormulasahpohyBelum ada peringkat
- 835618Dokumen298 halaman835618kamil_muhammad88Belum ada peringkat
- CourseWork1 20122013 SolutionsDokumen10 halamanCourseWork1 20122013 Solutionsyous123Belum ada peringkat
- MFE Study GuideDokumen17 halamanMFE Study Guideahpohy100% (1)
- CS2 Booklet 8 (Time Series) 2019 FINALDokumen168 halamanCS2 Booklet 8 (Time Series) 2019 FINALAnsh ParmarBelum ada peringkat
- CM1 Flashcards Sample - Chapter 14Dokumen56 halamanCM1 Flashcards Sample - Chapter 14Bakari HamisiBelum ada peringkat
- AM1 - Tutorial 1Dokumen12 halamanAM1 - Tutorial 1Nguyễn Quang Trường100% (1)
- MLC Sample SolutionDokumen169 halamanMLC Sample SolutionLoh Hui YinBelum ada peringkat
- Edu Spring Ltam QuesDokumen245 halamanEdu Spring Ltam QuesEricBelum ada peringkat
- Regression Modelling With Actuarial and Financial Applications - Key NotesDokumen3 halamanRegression Modelling With Actuarial and Financial Applications - Key NotesMitchell NathanielBelum ada peringkat
- CK1 Booklet 1 PDFDokumen52 halamanCK1 Booklet 1 PDFAndersonBelum ada peringkat
- Final CT8 Summary Notes PDFDokumen110 halamanFinal CT8 Summary Notes PDFMihai MirceaBelum ada peringkat
- Non-Life Insurance Mathematics (Sumary)Dokumen99 halamanNon-Life Insurance Mathematics (Sumary)chechoBelum ada peringkat
- Ch2 SlidesDokumen80 halamanCh2 SlidesYiLinLiBelum ada peringkat
- CT5 PXS 11Dokumen88 halamanCT5 PXS 11Yash Tiwari0% (1)
- General Linear Model (GLM)Dokumen58 halamanGeneral Linear Model (GLM)Imran ShahrilBelum ada peringkat
- 15 GIT All ExercisesDokumen162 halaman15 GIT All Exerciseskenny013100% (1)
- Essential Reading: Choice Under UncertaintyDokumen28 halamanEssential Reading: Choice Under UncertaintyDương DươngBelum ada peringkat
- Formulas For The MFE ExamDokumen17 halamanFormulas For The MFE ExamrortianBelum ada peringkat
- Caa Student Actuarial Analyst Handbooknov14Dokumen62 halamanCaa Student Actuarial Analyst Handbooknov14SiphoKhosaBelum ada peringkat
- 2014 Mahler Sample M FeDokumen237 halaman2014 Mahler Sample M Fenight_98036100% (1)
- Generalized Linear ModelsDokumen5 halamanGeneralized Linear Modelsplfs1974Belum ada peringkat
- R14 Topics in Demand and Supply Analysis Slides PDFDokumen33 halamanR14 Topics in Demand and Supply Analysis Slides PDFSonu RoseBelum ada peringkat
- Sample Chapter From Yufeng Guo's Study GuideDokumen22 halamanSample Chapter From Yufeng Guo's Study Guide赤铁炎Belum ada peringkat
- Exam P Practice Exam by Jared NakamuraDokumen63 halamanExam P Practice Exam by Jared NakamuratomBelum ada peringkat
- Probability of RuinDokumen84 halamanProbability of RuinDaniel QuinnBelum ada peringkat
- Homework 5 Solve For The Midterm Test .Dokumen3 halamanHomework 5 Solve For The Midterm Test .Sawsan AbiibBelum ada peringkat
- Ruin TheoryDokumen29 halamanRuin TheoryAnonymous M8Bvu4FExBelum ada peringkat
- IC 14 Regulations PDFDokumen320 halamanIC 14 Regulations PDFanjana CrBelum ada peringkat
- CK1 Booklet 1 PDFDokumen130 halamanCK1 Booklet 1 PDFAndersonBelum ada peringkat
- An Introductory Guide in The Construction of Actuarial Models: A Preparation For The Actuarial Exam C/4Dokumen350 halamanAn Introductory Guide in The Construction of Actuarial Models: A Preparation For The Actuarial Exam C/4Kalev Maricq100% (1)
- Probability Distributions Summary - Exam PDokumen1 halamanProbability Distributions Summary - Exam Proy_gettyBelum ada peringkat
- Ruin Probability On Premium Pricing Using Pareto Distributed Claims On Policies With Benefit LimitDokumen49 halamanRuin Probability On Premium Pricing Using Pareto Distributed Claims On Policies With Benefit Limitonly_AyrnandBelum ada peringkat
- Exam P: You Have What It Takes To PassDokumen4 halamanExam P: You Have What It Takes To PassEllen HutagaolBelum ada peringkat
- CS2 B Chapter 2 - Markov Chains - SolutionsDokumen15 halamanCS2 B Chapter 2 - Markov Chains - SolutionsSwapnil SinghBelum ada peringkat
- Exam P Formula Sheet PDFDokumen9 halamanExam P Formula Sheet PDFtutuBelum ada peringkat
- CDS Quality+Measures Codes 20oct11 FINALDokumen278 halamanCDS Quality+Measures Codes 20oct11 FINALbetzyvazquezBelum ada peringkat
- Actuarial SocietyDokumen35 halamanActuarial Societysachdev_researchBelum ada peringkat
- Actuarial Mathematics Ii: AboutDokumen107 halamanActuarial Mathematics Ii: AboutClerry SamuelBelum ada peringkat
- CT1Dokumen204 halamanCT1Akhil Garg0% (1)
- Formula SheetDokumen31 halamanFormula Sheetkarthik Ravichandiran100% (1)
- Damien Lamberton, Bernard Lapeyre, Nicolas Rabeau, Francois Mantion Introduction To Stochastic Calculus Applied To Finance 1996Dokumen99 halamanDamien Lamberton, Bernard Lapeyre, Nicolas Rabeau, Francois Mantion Introduction To Stochastic Calculus Applied To Finance 1996Nijat MutallimovBelum ada peringkat
- Deeper Understanding, Faster Calculation - Exam P Insights & Shortcuts 20th EditionDokumen28 halamanDeeper Understanding, Faster Calculation - Exam P Insights & Shortcuts 20th EditionJose Ramon VillatuyaBelum ada peringkat
- Surplus Process and Ruin Theory and Ruin TheoryDokumen12 halamanSurplus Process and Ruin Theory and Ruin TheoryLindy ElliottBelum ada peringkat
- Probability Formula SheetDokumen11 halamanProbability Formula SheetJake RoosenbloomBelum ada peringkat
- Maths Model Paper 2Dokumen7 halamanMaths Model Paper 2ravibiriBelum ada peringkat
- Estimation Theory PresentationDokumen66 halamanEstimation Theory PresentationBengi Mutlu Dülek100% (1)
- Chapter 2Dokumen25 halamanChapter 2McNemarBelum ada peringkat
- Qm Summary Final: h μ x σ σ s s σ s ρ δ dDokumen13 halamanQm Summary Final: h μ x σ σ s s σ s ρ δ dJan BorowskiBelum ada peringkat
- Lecture 09Dokumen15 halamanLecture 09nandish mehtaBelum ada peringkat
- Chapter 06-2 Rotational DynamicsDokumen5 halamanChapter 06-2 Rotational DynamicsalvinhimBelum ada peringkat
- Chapter 05-1 Simple Harmonic MotionDokumen7 halamanChapter 05-1 Simple Harmonic MotionalvinhimBelum ada peringkat
- Chapter 05-2 Energy in SHMDokumen6 halamanChapter 05-2 Energy in SHMalvinhimBelum ada peringkat
- Chapter 06-1 Moments of ForceDokumen5 halamanChapter 06-1 Moments of ForcealvinhimBelum ada peringkat
- Chapter 03 Circular MotionDokumen4 halamanChapter 03 Circular MotionalvinhimBelum ada peringkat
- Chapter 04 GravitationDokumen8 halamanChapter 04 GravitationalvinhimBelum ada peringkat
- Chapter 01-3 Relative VelocityDokumen2 halamanChapter 01-3 Relative VelocityalvinhimBelum ada peringkat
- Chapter 02-2 Work, Energy and Linear MomentumDokumen5 halamanChapter 02-2 Work, Energy and Linear MomentumalvinhimBelum ada peringkat
- Chapter 02-2 Work, Energy and Linear MomentumDokumen5 halamanChapter 02-2 Work, Energy and Linear MomentumalvinhimBelum ada peringkat
- Chapter 02-1 Newton's LawDokumen5 halamanChapter 02-1 Newton's LawalvinhimBelum ada peringkat
- Chapter 01-2 2dmotionDokumen3 halamanChapter 01-2 2dmotionalvinhimBelum ada peringkat
- Example CVDokumen1 halamanExample CValvinhimBelum ada peringkat
- Chapter 01-1 1dmotionDokumen6 halamanChapter 01-1 1dmotionalvinhimBelum ada peringkat
- Ray Diagram of An Astronomical Telescope: June 07. 2013 11:14 PMDokumen1 halamanRay Diagram of An Astronomical Telescope: June 07. 2013 11:14 PMalvinhimBelum ada peringkat
- Maths ProofsDokumen3 halamanMaths ProofsalvinhimBelum ada peringkat
- Kcet - Mathematics - 2019: Version Code: B-2Dokumen7 halamanKcet - Mathematics - 2019: Version Code: B-2Ganesh BhandaryBelum ada peringkat
- Genetics & Plant Breeding - 20191128023407Dokumen23 halamanGenetics & Plant Breeding - 20191128023407Pravin100% (1)
- On State Variables and POMDP-sDokumen49 halamanOn State Variables and POMDP-sRiddho Ridwanul HaqueBelum ada peringkat
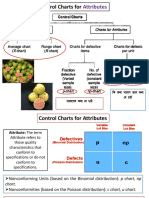
- 3 Control Charts P NP C UDokumen28 halaman3 Control Charts P NP C UFerdous SalehinBelum ada peringkat
- Unit 1 - 03Dokumen10 halamanUnit 1 - 03Raja RamachandranBelum ada peringkat
- CTA - 09 Simulation VBA.16Dokumen34 halamanCTA - 09 Simulation VBA.16david AbotsitseBelum ada peringkat
- Cool Memories: Notes On The Ligeti Viola Sonata John Stulz (2012)Dokumen29 halamanCool Memories: Notes On The Ligeti Viola Sonata John Stulz (2012)Florian WesselBelum ada peringkat
- Scott Cunningham - Causal Inference - The Mixtape-Draft Version v. 1.8 (2021)Dokumen324 halamanScott Cunningham - Causal Inference - The Mixtape-Draft Version v. 1.8 (2021)PaulaAndreaMorenoBelum ada peringkat
- Sample Space.: How Many Different Equally Likely Possibilities Are There?Dokumen12 halamanSample Space.: How Many Different Equally Likely Possibilities Are There?islamBelum ada peringkat
- Morgenstern Probabilistic Slope Stability Analysis For PracticeDokumen19 halamanMorgenstern Probabilistic Slope Stability Analysis For PracticeburlandBelum ada peringkat
- Methods of Soil AnalysisDokumen1.711 halamanMethods of Soil Analysiskiura_escalanteBelum ada peringkat
- Chapter 1Dokumen13 halamanChapter 1Allen DelaCruz LeonsandaBelum ada peringkat
- Soalan Klon Set A Pelajar SM025Dokumen6 halamanSoalan Klon Set A Pelajar SM025NUR FAHIRA ELIANA BINTI MOHD ZULKIFLI KM-PelajarBelum ada peringkat
- Normal Distribution WorksheetDokumen5 halamanNormal Distribution Worksheetapi-534996578Belum ada peringkat
- Mtech Comp CsDokumen78 halamanMtech Comp CsArunima S KumarBelum ada peringkat
- 統計學 Midterm Exam 2018/11/30 系級: - - - - - - - - - - - - 學號: - - - - - - - - - - - - 姓名: - - - - - - - - - - - - -Dokumen6 halaman統計學 Midterm Exam 2018/11/30 系級: - - - - - - - - - - - - 學號: - - - - - - - - - - - - 姓名: - - - - - - - - - - - - -Jane LuBelum ada peringkat
- I. ObjectivesDokumen3 halamanI. ObjectivesFRECY MARZANBelum ada peringkat
- Econometrics IIDokumen101 halamanEconometrics IIDENEKEW LESEMI100% (1)
- Module 6 Common Continuous Probability DistributionDokumen45 halamanModule 6 Common Continuous Probability DistributionKejeindrranBelum ada peringkat
- Rec 12A - Sampling Distribution-2-1 Rev 20220404Dokumen5 halamanRec 12A - Sampling Distribution-2-1 Rev 20220404Skylar HsuBelum ada peringkat
- Statistics 1 Discrete Random Variables Past ExaminationDokumen24 halamanStatistics 1 Discrete Random Variables Past ExaminationAbid FareedBelum ada peringkat
- Uniform Distribution: Function Is Given byDokumen2 halamanUniform Distribution: Function Is Given byFabricio GZ100% (1)
- Agronomy MCQsDokumen198 halamanAgronomy MCQsAtif KhanBelum ada peringkat
- DBA MathsDokumen98 halamanDBA Mathsvictor chisengaBelum ada peringkat
- Kertas 1 SPM Matematik Tambahan 2004-2010Dokumen25 halamanKertas 1 SPM Matematik Tambahan 2004-2010Cikgu Mohamad Esmandi HapniBelum ada peringkat
- Efecto Flash-LagDokumen6 halamanEfecto Flash-LagDiegoBelum ada peringkat
- Ebook PDF Statistics Principles and Methods 8th Edition PDFDokumen41 halamanEbook PDF Statistics Principles and Methods 8th Edition PDFjoseph.corey248100% (33)
- NJC Sampling Lecture NotesDokumen24 halamanNJC Sampling Lecture NotesbhimabiBelum ada peringkat
- Ch15 TextbookDokumen38 halamanCh15 TextbookMuhammad GhayoorBelum ada peringkat
- 9709 s14 QP 72 PDFDokumen4 halaman9709 s14 QP 72 PDFhhvjyuiBelum ada peringkat