Anda mungkin juga menyukai
- PsicoDokumen5 halamanPsicoAsamblea Cristiana LinaresBelum ada peringkat
- El Objetivo de Este CapítuloDokumen1 halamanEl Objetivo de Este CapítuloAsamblea Cristiana LinaresBelum ada peringkat
- FormatoDokumen1 halamanFormatoAsamblea Cristiana LinaresBelum ada peringkat
- REQUISITOSDokumen1 halamanREQUISITOSAsamblea Cristiana LinaresBelum ada peringkat
- Asimismo Texto 3Dokumen1 halamanAsimismo Texto 3Asamblea Cristiana LinaresBelum ada peringkat
- Tacna - Ladrón Capturado Por Vecinos Fue Amarrado A Un Poste Con Un Cartel Que Decía "Soy Ratero"Dokumen2 halamanTacna - Ladrón Capturado Por Vecinos Fue Amarrado A Un Poste Con Un Cartel Que Decía "Soy Ratero"Asamblea Cristiana LinaresBelum ada peringkat
- Texto 4Dokumen1 halamanTexto 4Asamblea Cristiana LinaresBelum ada peringkat
- Gestión de ResultadosDokumen1 halamanGestión de ResultadosAsamblea Cristiana LinaresBelum ada peringkat
- Borrar ArchivosDokumen1 halamanBorrar ArchivosAsamblea Cristiana LinaresBelum ada peringkat
- Tacna - Ladrón Capturado Por Vecinos Fue Amarrado A Un Poste Con Un Cartel Que Decía "Soy Ratero"Dokumen2 halamanTacna - Ladrón Capturado Por Vecinos Fue Amarrado A Un Poste Con Un Cartel Que Decía "Soy Ratero"Asamblea Cristiana LinaresBelum ada peringkat
- En Cuanto A La Concepción de Ser HumanoDokumen1 halamanEn Cuanto A La Concepción de Ser HumanoAsamblea Cristiana LinaresBelum ada peringkat
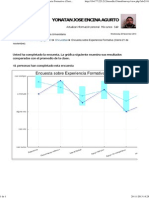
- DIPLOMADO A 2013 Encuesta GuardadaDokumen1 halamanDIPLOMADO A 2013 Encuesta GuardadaAsamblea Cristiana LinaresBelum ada peringkat
- Ejemplo 2 Etnografía Escuela y RitualesDokumen10 halamanEjemplo 2 Etnografía Escuela y RitualesAsamblea Cristiana LinaresBelum ada peringkat
- DIPLOMADO A 2013 Encuesta GuardadaDokumen1 halamanDIPLOMADO A 2013 Encuesta GuardadaAsamblea Cristiana LinaresBelum ada peringkat
- 0gestión Educativa y Calidad de VidaDokumen21 halaman0gestión Educativa y Calidad de VidaTakesy Delgado RomeroBelum ada peringkat
- Glitter AnimalesDokumen1 halamanGlitter AnimalesAsamblea Cristiana LinaresBelum ada peringkat
- DIPLOMADO - A - 2013 - Encuesta Sobre Experiencia Formativa (Cierre 21 de Noviembre)Dokumen1 halamanDIPLOMADO - A - 2013 - Encuesta Sobre Experiencia Formativa (Cierre 21 de Noviembre)Asamblea Cristiana LinaresBelum ada peringkat
- FormatomonografiasDokumen5 halamanFormatomonografiasAsamblea Cristiana LinaresBelum ada peringkat
- Paul Ricoeur Quc3a9 Es Un TextoDokumen15 halamanPaul Ricoeur Quc3a9 Es Un TextoYamilirún IrúnBelum ada peringkat
- InstruccionesDokumen1 halamanInstruccionesAsamblea Cristiana LinaresBelum ada peringkat
- 0027 FDokumen10 halaman0027 FAsamblea Cristiana LinaresBelum ada peringkat
- Glitter AnimalesDokumen1 halamanGlitter AnimalesAsamblea Cristiana LinaresBelum ada peringkat
- Actividades de Motricidad Fina para Niños PreescolaresDokumen2 halamanActividades de Motricidad Fina para Niños PreescolaresAsamblea Cristiana LinaresBelum ada peringkat
- Actividades para Tomar El LápizDokumen2 halamanActividades para Tomar El LápizAsamblea Cristiana Linares100% (1)
- Glitter AnimalesDokumen1 halamanGlitter AnimalesAsamblea Cristiana LinaresBelum ada peringkat
- Crisis IdentidadDokumen1 halamanCrisis IdentidadAsamblea Cristiana LinaresBelum ada peringkat
- Actividades Grupales TALLERESDokumen3 halamanActividades Grupales TALLERESAsamblea Cristiana LinaresBelum ada peringkat
- Crisis Identidad SocialDokumen1 halamanCrisis Identidad SocialAsamblea Cristiana LinaresBelum ada peringkat
- Psicología Social AplicadaDokumen1 halamanPsicología Social AplicadaAsamblea Cristiana LinaresBelum ada peringkat
- Examen Estadistica-PrimerParcial-ESPOLDokumen4 halamanExamen Estadistica-PrimerParcial-ESPOLDeivid Moran67% (3)
- M17S3 CalculandoDokumen5 halamanM17S3 CalculandoFrank Galicia50% (2)
- Practica 3Dokumen4 halamanPractica 3SebastiánHoracioCepeda100% (1)
- Gases T. Autonomo 39645Dokumen2 halamanGases T. Autonomo 39645Carlos ManuelBelum ada peringkat
- 14.prueba de Independencia EstadisticaDokumen25 halaman14.prueba de Independencia EstadisticaSabrinaRojasC.100% (1)
- Arima y SarimaDokumen6 halamanArima y SarimaJeniffer Párraga100% (1)
- 01 - Guia de Ejercicios 1 Estadistica DescriptivaDokumen5 halaman01 - Guia de Ejercicios 1 Estadistica DescriptivaFrancisco PinochetBelum ada peringkat
- Correlación cruzada y estacionariedad en series temporalesDokumen1 halamanCorrelación cruzada y estacionariedad en series temporalesCM MundoBelum ada peringkat
- Matriz TesisDokumen3 halamanMatriz TesisRaul Ronald Tito FigueredoBelum ada peringkat
- 1.-EST HIDROLOGICO - HIDRAULICO v02Dokumen30 halaman1.-EST HIDROLOGICO - HIDRAULICO v02Anonymous 3EfmPPLSBelum ada peringkat
- Act 5 - QuizDokumen7 halamanAct 5 - QuizJean Paul RossiBelum ada peringkat
- Diseños Factoriales ResueltosDokumen17 halamanDiseños Factoriales ResueltosJean Carlo Villanueva GoyzuetaBelum ada peringkat
- Cala - Callisaya - Carmen TesisDokumen96 halamanCala - Callisaya - Carmen TesiscutipazBelum ada peringkat
- Muestra IntencionadaDokumen11 halamanMuestra IntencionadarexsitoBelum ada peringkat
- DendrometriaDokumen312 halamanDendrometriaChio Garcia Romero100% (1)
- 193 - PDFsam - (PD) Documentos - Evaluacion de Los Proyectos de InversionDokumen3 halaman193 - PDFsam - (PD) Documentos - Evaluacion de Los Proyectos de InversionJhon RyderBelum ada peringkat
- Energía eólica TuquerresDokumen4 halamanEnergía eólica TuquerresJorge MateusBelum ada peringkat
- Trabjo de EstadisticaDokumen32 halamanTrabjo de EstadisticaEvelyn Stefania71% (24)
- Guía Estadística Mates 8°B Colegio Providencia TemucoDokumen2 halamanGuía Estadística Mates 8°B Colegio Providencia TemucoMaria Soledad Rasse HernandezBelum ada peringkat
- Aplicacion de Distribucion ExponencialDokumen8 halamanAplicacion de Distribucion ExponencialDavid Rodriguez0% (1)
- Ejercicioscapitulo6estadistica Respuestas 141225215647 Conversion Gate02Dokumen15 halamanEjercicioscapitulo6estadistica Respuestas 141225215647 Conversion Gate02Edita BenitezBelum ada peringkat
- La influencia del inconsciente colectivo en la percepción de las marcasDokumen19 halamanLa influencia del inconsciente colectivo en la percepción de las marcasAlonso DriftBelum ada peringkat
- Determinación de La Precipitación Media Mediante El Software Hydraccess-Cuenca Vilcanota-PisacDokumen11 halamanDeterminación de La Precipitación Media Mediante El Software Hydraccess-Cuenca Vilcanota-PisacGUIDO CAÑARI QUISPE100% (1)
- Estudio Hidrologia y Drenaje v2 VFDokumen40 halamanEstudio Hidrologia y Drenaje v2 VFMARTIN UBILLUS LIMO100% (1)
- Distribución de BernoulliDokumen22 halamanDistribución de BernoulliHENRY ISAAC GONZALEZ CRUZBelum ada peringkat
- Estudio_poblacion_colegio_Alipio_Ponce_VasquezDokumen7 halamanEstudio_poblacion_colegio_Alipio_Ponce_VasquezFrank Ludwind Camposano BerrospiBelum ada peringkat
- Esta Di SticaDokumen6 halamanEsta Di SticaRuiz RuizBelum ada peringkat
- Quiz 1 Apoyo 2 PDFDokumen4 halamanQuiz 1 Apoyo 2 PDFYalile Gamboa PardoBelum ada peringkat
- Intervalo de Confianza para La Pendiente Del ModeloDokumen3 halamanIntervalo de Confianza para La Pendiente Del ModeloJosue Daniel100% (1)