Anda mungkin juga menyukai
- Project Group 3-ReportDokumen44 halamanProject Group 3-ReportTomi OlinBelum ada peringkat
- GuesstimatesDokumen5 halamanGuesstimatesHritik LalBelum ada peringkat
- Cars Coursework StatisticsDokumen6 halamanCars Coursework Statisticsf5da9eqt100% (2)
- Practice Operation RIsetDokumen3 halamanPractice Operation RIsetHenry KurniawanBelum ada peringkat
- StatisticsDokumen8 halamanStatisticsIg100% (1)
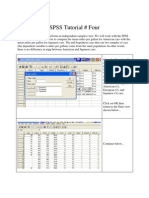
- SPSS TutorialDokumen5 halamanSPSS TutorialPhan Minh TrungBelum ada peringkat
- Great Learning SMDM ProjectDokumen16 halamanGreat Learning SMDM Projectrameshj16708Belum ada peringkat
- Introduction to Statistics: Basic Definitions and ConceptsDokumen4 halamanIntroduction to Statistics: Basic Definitions and ConceptsChester ArenasBelum ada peringkat
- Chi SquaredDokumen15 halamanChi SquaredArlenie Manog MadeloBelum ada peringkat
- Statistics Car CourseworkDokumen6 halamanStatistics Car Courseworkf5ddpge2100% (2)
- Used Cars CourseworkDokumen4 halamanUsed Cars Courseworkafjzdonobiowee100% (1)
- Gcse Statistics Coursework Car PricesDokumen4 halamanGcse Statistics Coursework Car Pricespkznbbifg100% (2)
- Course Title: Business Statistics: Solutions Assignment #1: What Is Statistics?Dokumen4 halamanCourse Title: Business Statistics: Solutions Assignment #1: What Is Statistics?Rania GoujaBelum ada peringkat
- Math ProjectDokumen6 halamanMath Projectapi-711119679Belum ada peringkat
- Descriptive Use Charts Graphs Tables and Numerical MeasuresDokumen11 halamanDescriptive Use Charts Graphs Tables and Numerical Measuresaoi03Belum ada peringkat
- Assignment SI Dr. Javed Iqbal Fall 21 NewDokumen7 halamanAssignment SI Dr. Javed Iqbal Fall 21 Newح ی د رBelum ada peringkat
- FewdvjcklnmDokumen14 halamanFewdvjcklnmLiz PaigeBelum ada peringkat
- Course Title: Business Statistics and Probability I: Assignment #1: What Is Statistics?Dokumen3 halamanCourse Title: Business Statistics and Probability I: Assignment #1: What Is Statistics?Mariem JabberiBelum ada peringkat
- CH 01Dokumen45 halamanCH 01Mohamed FarahBelum ada peringkat
- Statistics Coursework CarsDokumen8 halamanStatistics Coursework Carsafazbsaxi100% (2)
- Comm291 Practice MidtermDokumen70 halamanComm291 Practice Midtermal3ungBelum ada peringkat
- Chi-Square Analysis in MarketingDokumen6 halamanChi-Square Analysis in MarketingNutukurthi Venkat RamjiBelum ada peringkat
- Used Cars Statistics CourseworkDokumen6 halamanUsed Cars Statistics Courseworkf5dq3ch5100% (2)
- A Kerl of Market For LemonsDokumen15 halamanA Kerl of Market For LemonsManuel Lleonart AnguixBelum ada peringkat
- Probability Sampling Methods ExplainedDokumen9 halamanProbability Sampling Methods ExplainedEng Mohammed100% (1)
- TLMT601 Transportation EconomicsDokumen5 halamanTLMT601 Transportation EconomicsG JhaBelum ada peringkat
- Ppa 696: SamplingDokumen8 halamanPpa 696: SamplingNo PersonBelum ada peringkat
- Business Report Pradeep Chauhan 11june'23Dokumen25 halamanBusiness Report Pradeep Chauhan 11june'23Pradeep ChauhanBelum ada peringkat
- Anova and The Design of Experiments: Welcome To Powerpoint Slides ForDokumen22 halamanAnova and The Design of Experiments: Welcome To Powerpoint Slides ForParth Rajesh ShethBelum ada peringkat
- Chi-Square Independence Test ProblemsDokumen13 halamanChi-Square Independence Test ProblemsJaspreet KaurBelum ada peringkat
- Simulation NotesDokumen6 halamanSimulation NotesGeeBelum ada peringkat
- Minitab ExercisesDokumen17 halamanMinitab ExercisessadiqusBelum ada peringkat
- Business Statistics: PGDM (2017-19) Term-II (Sep-Dec, 2017)Dokumen56 halamanBusiness Statistics: PGDM (2017-19) Term-II (Sep-Dec, 2017)Kanav GuptaBelum ada peringkat
- Trident University Ph.D. program class explores statistical analysisDokumen5 halamanTrident University Ph.D. program class explores statistical analysisanhntran4850Belum ada peringkat
- CasesDokumen7 halamanCasesSahil BhatiaBelum ada peringkat
- Case Study 6 Tut 01 Group 04Dokumen23 halamanCase Study 6 Tut 01 Group 042004040009Belum ada peringkat
- Sampling Design Guide for Business ResearchDokumen21 halamanSampling Design Guide for Business ResearchSahil BansalBelum ada peringkat
- IME602 Notes 01Dokumen65 halamanIME602 Notes 01Tanmay KulshresthaBelum ada peringkat
- Cluster AnalysisDokumen9 halamanCluster AnalysisLede DelgadoBelum ada peringkat
- Monte Carlo Simulation in ExcelDokumen9 halamanMonte Carlo Simulation in ExcelAkshata GodseBelum ada peringkat
- Buku SPSS CompleteDokumen72 halamanBuku SPSS Completeb6788Belum ada peringkat
- Maths Statistics Coursework CarsDokumen7 halamanMaths Statistics Coursework Carsbd9gjpsn100% (2)
- Pricing Howtoplay ScriptDokumen2 halamanPricing Howtoplay ScriptRamiro Costa0% (1)
- Stratified Sampling: What Is Non-Probability Sampling?Dokumen5 halamanStratified Sampling: What Is Non-Probability Sampling?Shairon palmaBelum ada peringkat
- Pes1ug22cs841 Sudeep G Lab1Dokumen37 halamanPes1ug22cs841 Sudeep G Lab1nishkarshBelum ada peringkat
- Deriving Insights From DataDokumen8 halamanDeriving Insights From DatagetgauravsbestBelum ada peringkat
- 3rd Assignment Research SolutionDokumen109 halaman3rd Assignment Research SolutionAsfawosen DingamaBelum ada peringkat
- Lift Chart (Analysis Services - Data Mining)Dokumen5 halamanLift Chart (Analysis Services - Data Mining)vlaresearchBelum ada peringkat
- Descriptive Analytics CourseworkDokumen22 halamanDescriptive Analytics CourseworkHassaan HaiderBelum ada peringkat
- CH 01Dokumen49 halamanCH 01m m c channelBelum ada peringkat
- Quantitative TechniquesDokumen11 halamanQuantitative TechniquessanjayifmBelum ada peringkat
- Conjoint Analysis PDFDokumen15 halamanConjoint Analysis PDFSumit Kumar Awkash100% (1)
- Case StudyDokumen11 halamanCase StudyKester NdabaiBelum ada peringkat
- Business StatisticsDokumen201 halamanBusiness StatisticsDerickMwansa100% (8)
- HW 5Dokumen3 halamanHW 5Mansi JainBelum ada peringkat
- Carl Drott CompletoDokumen9 halamanCarl Drott CompletoadrianahollosBelum ada peringkat
- Top 20 MS Excel VBA Simulations, VBA to Model Risk, Investments, Growth, Gambling, and Monte Carlo AnalysisDari EverandTop 20 MS Excel VBA Simulations, VBA to Model Risk, Investments, Growth, Gambling, and Monte Carlo AnalysisPenilaian: 2.5 dari 5 bintang2.5/5 (2)
- Ecriture Fraction 1Dokumen1 halamanEcriture Fraction 1ahmed22gouda22Belum ada peringkat
- Medical Devices by FacilityDokumen60 halamanMedical Devices by FacilityjwalitBelum ada peringkat
- Efficient Optimal Surface Detection in Medical ImagesDokumen8 halamanEfficient Optimal Surface Detection in Medical Imagesahmed22gouda22Belum ada peringkat
- Equipment, meals, coffee breaks and set menusDokumen13 halamanEquipment, meals, coffee breaks and set menusahmed22gouda22Belum ada peringkat
- North TutorialDokumen10 halamanNorth Tutorialahmed22gouda22Belum ada peringkat
- Golden Selling Skills Rules 1Dokumen56 halamanGolden Selling Skills Rules 1ahmed22gouda22Belum ada peringkat
- OpenAir Calculating Utilization Services CompanyDokumen8 halamanOpenAir Calculating Utilization Services Companyahmed22gouda22Belum ada peringkat
- American Statistical Association, Taylor & Francis, Ltd. Journal of The American Statistical AssociationDokumen2 halamanAmerican Statistical Association, Taylor & Francis, Ltd. Journal of The American Statistical Associationahmed22gouda22Belum ada peringkat
- Markov Algorithms Circumvent Curse of Dimensionality in Stochastic GamesDokumen22 halamanMarkov Algorithms Circumvent Curse of Dimensionality in Stochastic Gamesahmed22gouda22Belum ada peringkat
- Ten YearDokumen14 halamanTen Yearahmed22gouda22Belum ada peringkat
- 08Dokumen4 halaman08ahmed22gouda22Belum ada peringkat
- 11 Chapter Xi: Multi-Objective ProgrammingDokumen23 halaman11 Chapter Xi: Multi-Objective Programmingahmed22gouda22Belum ada peringkat
- Selling Skill TrainingDokumen32 halamanSelling Skill Trainingahmed22gouda22Belum ada peringkat
- Selling Skills Module FinalDokumen11 halamanSelling Skills Module Finalahmed22gouda22Belum ada peringkat
- Pharmaceutical Representatives: An Evidence-Based Review With Suggested Guidelines For ClerkshipsDokumen5 halamanPharmaceutical Representatives: An Evidence-Based Review With Suggested Guidelines For Clerkshipsahmed22gouda22Belum ada peringkat
- Handbook of Market SegmentationDokumen252 halamanHandbook of Market Segmentationahmed22gouda22100% (4)
- The Nine Basic Human NeedsDokumen12 halamanThe Nine Basic Human NeedsAhmed GoudaBelum ada peringkat
- BrightTALK - Measuring Marketing EffectivenessDokumen24 halamanBrightTALK - Measuring Marketing Effectivenessahmed22gouda22Belum ada peringkat
- Communication Affect and LearningDokumen267 halamanCommunication Affect and LearningMohd Redzuan Mohd NorBelum ada peringkat
- DK-The British Medical Association-Complete Family Health GuideDokumen992 halamanDK-The British Medical Association-Complete Family Health Guidedangnghia211290% (10)
- Pharmaceutical Representatives: An Evidence-Based Review With Suggested Guidelines For ClerkshipsDokumen5 halamanPharmaceutical Representatives: An Evidence-Based Review With Suggested Guidelines For Clerkshipsahmed22gouda22Belum ada peringkat
- Kit Ron 2010Dokumen25 halamanKit Ron 2010ahmed22gouda22Belum ada peringkat
- 08Dokumen4 halaman08ahmed22gouda22Belum ada peringkat
- Creative Commons Attribution-Noncommercial-Sharealike LicenseDokumen50 halamanCreative Commons Attribution-Noncommercial-Sharealike Licenseahmed22gouda22Belum ada peringkat
- Session Five: Random SamplingDokumen7 halamanSession Five: Random Samplingahmed22gouda22Belum ada peringkat
- Using The Simplex Method To Solve LinearDokumen28 halamanUsing The Simplex Method To Solve LinearmbuyiselwaBelum ada peringkat
- The Philosophy Behind Sampling in Educational Research: ReviewDokumen5 halamanThe Philosophy Behind Sampling in Educational Research: Reviewahmed22gouda22Belum ada peringkat
- No 9Dokumen32 halamanNo 9ahmed22gouda22Belum ada peringkat
- Creative Commons Attribution-Noncommercial-Sharealike LicenseDokumen50 halamanCreative Commons Attribution-Noncommercial-Sharealike Licenseahmed22gouda22Belum ada peringkat