Anda mungkin juga menyukai
- SMDM ProjectDokumen19 halamanSMDM Projectnishant100% (1)
- A-level Maths Revision: Cheeky Revision ShortcutsDari EverandA-level Maths Revision: Cheeky Revision ShortcutsPenilaian: 3.5 dari 5 bintang3.5/5 (8)
- Standard-Slope Integration: A New Approach to Numerical IntegrationDari EverandStandard-Slope Integration: A New Approach to Numerical IntegrationBelum ada peringkat
- Cost Volume Profit (CVP) AnalysisDokumen40 halamanCost Volume Profit (CVP) AnalysisAnne PrestosaBelum ada peringkat
- Logistic RegressionDokumen49 halamanLogistic RegressionpankajBelum ada peringkat
- Surveying Review NotesDokumen7 halamanSurveying Review Notessadon100% (1)
- FEM Modeling of PVD and EmbankmentsDokumen68 halamanFEM Modeling of PVD and EmbankmentsKen LiewBelum ada peringkat
- cs229 Notes EnsembleDokumen7 halamancs229 Notes EnsemblebobBelum ada peringkat
- Unit - 5Dokumen111 halamanUnit - 5Bhavya DedhiaBelum ada peringkat
- Regression Analysis - STAT510Dokumen34 halamanRegression Analysis - STAT510Vivian TranBelum ada peringkat
- Logistic RegressionDokumen49 halamanLogistic Regressiontamim habybyBelum ada peringkat
- 5-LR Doc - R Sqared-Bias-Variance-Ridg-LassoDokumen26 halaman5-LR Doc - R Sqared-Bias-Variance-Ridg-LassoMonis KhanBelum ada peringkat
- Gauss Markov TheoremDokumen16 halamanGauss Markov TheoremNidhiBelum ada peringkat
- Logistic RegressionDokumen49 halamanLogistic RegressionAkash M KBelum ada peringkat
- Solutions Chapter6Dokumen19 halamanSolutions Chapter6Zodwa MngometuluBelum ada peringkat
- EconometricsDokumen6 halamanEconometricsTiberiu TincaBelum ada peringkat
- Solutions Chapter6Dokumen19 halamanSolutions Chapter6yitagesu eshetuBelum ada peringkat
- Second Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions ManualDokumen11 halamanSecond Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions Manualdulcitetutsanz9u100% (18)
- Regression 2006-03-01Dokumen53 halamanRegression 2006-03-01Rafi DawarBelum ada peringkat
- Statistics QuizDokumen20 halamanStatistics QuizMohan KoppulaBelum ada peringkat
- Multiple Linear Regression: Chapter 12Dokumen49 halamanMultiple Linear Regression: Chapter 12Ayushi MauryaBelum ada peringkat
- 3.2 Power Point 2Dokumen35 halaman3.2 Power Point 2krothrocBelum ada peringkat
- 06 Simple ModelingDokumen16 halaman06 Simple Modelingdéborah_rosalesBelum ada peringkat
- Tibs Jrssb96Dokumen23 halamanTibs Jrssb96sunbenBelum ada peringkat
- WNvanWieringen HDDA Lecture234 RidgeRegression 20182019 PDFDokumen132 halamanWNvanWieringen HDDA Lecture234 RidgeRegression 20182019 PDFprinceBelum ada peringkat
- Regression Shrinkage and Selection Via The LassoDokumen22 halamanRegression Shrinkage and Selection Via The LassopedropietrafesaBelum ada peringkat
- Statistics 500: Midterm 1 NameDokumen6 halamanStatistics 500: Midterm 1 NameSouleymane CoulibalyBelum ada peringkat
- Running Head: Problem Solving AssignmentDokumen11 halamanRunning Head: Problem Solving AssignmentKashémBelum ada peringkat
- ReportDokumen12 halamanReportJoaquinBelum ada peringkat
- Calibration: Constructing A Calibration CurveDokumen10 halamanCalibration: Constructing A Calibration Curvedéborah_rosalesBelum ada peringkat
- Chapter 3 Solutions: For More PracticeDokumen10 halamanChapter 3 Solutions: For More PracticeOmar HayatBelum ada peringkat
- Regression Analysis: Basic Concepts: 1 The Simple Linear ModelDokumen4 halamanRegression Analysis: Basic Concepts: 1 The Simple Linear ModelAlex CacerosBelum ada peringkat
- Logistic Regression: 30 March 2016Dokumen49 halamanLogistic Regression: 30 March 2016Mayur ChaudhariBelum ada peringkat
- Multiple Linear Regression Ver1.1Dokumen61 halamanMultiple Linear Regression Ver1.1jstadlasBelum ada peringkat
- SpssDokumen26 halamanSpssMaham Durrani100% (1)
- Corr RevisedDokumen11 halamanCorr RevisedMarcy LumiwesBelum ada peringkat
- Chapter 2: Ordinary Least SquaresDokumen11 halamanChapter 2: Ordinary Least SquaresOnur YuceBelum ada peringkat
- Module07 - Model Selection and RegularizationDokumen46 halamanModule07 - Model Selection and RegularizationkritiBelum ada peringkat
- 03 Chap03 ReviewOfLinearRegressionDokumen31 halaman03 Chap03 ReviewOfLinearRegressionamelBelum ada peringkat
- MultipleRegressionREview PDFDokumen32 halamanMultipleRegressionREview PDFAaron KWBelum ada peringkat
- Deepu FinalDokumen9 halamanDeepu FinalSneha BhaipBelum ada peringkat
- CP 2Dokumen2 halamanCP 2Ankita MishraBelum ada peringkat
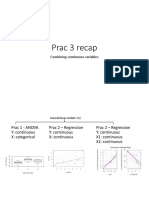
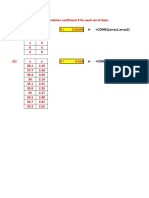
- Prac 3 Recap: Combining Continuous VariablesDokumen16 halamanPrac 3 Recap: Combining Continuous VariablesjessicaBelum ada peringkat
- Biasing Approximate Dynamic Programming With A Lower Discount FactorDokumen8 halamanBiasing Approximate Dynamic Programming With A Lower Discount FactorAfshin SamiaBelum ada peringkat
- QuasilikelihoodDokumen14 halamanQuasilikelihoodK6 LyonBelum ada peringkat
- Normal Distribution CollectionDokumen40 halamanNormal Distribution CollectionVivek ParulekarBelum ada peringkat
- Logistic RegressionDokumen49 halamanLogistic Regressionwilda anabiaBelum ada peringkat
- Tutorial SAM6Dokumen4 halamanTutorial SAM6Ditta Ria AriniBelum ada peringkat
- Midterm Fall19 Solutions StatisticsDokumen13 halamanMidterm Fall19 Solutions StatisticsPratyush ParasharBelum ada peringkat
- 5.linear RegressionDokumen39 halaman5.linear RegressionLUV ARORABelum ada peringkat
- STAT2201 - Ch. 14 Excel Files - UpdatedDokumen41 halamanSTAT2201 - Ch. 14 Excel Files - UpdatedGurjot SinghBelum ada peringkat
- Regression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inDokumen16 halamanRegression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inPavan PearliBelum ada peringkat
- Multiple Regression Analysis: y + X + X + - . - X + UDokumen26 halamanMultiple Regression Analysis: y + X + X + - . - X + Unavs05Belum ada peringkat
- Final DD VS SPDokumen7 halamanFinal DD VS SPAlazar JemberuBelum ada peringkat
- Analisis JalurDokumen30 halamanAnalisis JaluradityanugrahassBelum ada peringkat
- Econometrics Assignment Week 4Dokumen6 halamanEconometrics Assignment Week 4jantien De GrootBelum ada peringkat
- Lecture Notes On Measurement ErrorDokumen15 halamanLecture Notes On Measurement ErrorkeyyongparkBelum ada peringkat
- Chapter 5 - The Cointegrated VAR ModelDokumen41 halamanChapter 5 - The Cointegrated VAR ModelGerman GaldamezBelum ada peringkat
- LinearRegression - 2022Dokumen38 halamanLinearRegression - 2022Miguel Sacristán de FrutosBelum ada peringkat
- Simple Linear Regression AnalysisDokumen21 halamanSimple Linear Regression AnalysisEngr.bilalBelum ada peringkat
- Decision ScienceDokumen8 halamanDecision ScienceHimanshi YadavBelum ada peringkat
- 05 Class RegressionCorrelationDokumen57 halaman05 Class RegressionCorrelationJipeeZedBelum ada peringkat
- Python - 1Dokumen86 halamanPython - 1Muhammad FarooqBelum ada peringkat
- Chapter 29 (Markov Chains) PDFDokumen23 halamanChapter 29 (Markov Chains) PDFWesam WesamBelum ada peringkat
- Sergei Fedotov: 20912 - Introduction To Financial MathematicsDokumen27 halamanSergei Fedotov: 20912 - Introduction To Financial MathematicsaqszaqszBelum ada peringkat
- Modeling Bio ElectricalDokumen332 halamanModeling Bio ElectricalEduardo HidalgoBelum ada peringkat
- Finite Mixture Modelling Model Specification, Estimation & ApplicationDokumen11 halamanFinite Mixture Modelling Model Specification, Estimation & ApplicationPepe Garcia EstebezBelum ada peringkat
- Method of SubstittutionDokumen4 halamanMethod of Substittutionpalash khannaBelum ada peringkat
- C2 Practice Paper A2Dokumen5 halamanC2 Practice Paper A2Brianna AmechiBelum ada peringkat
- CH5100 Peristaltic FlowDokumen21 halamanCH5100 Peristaltic FlowashuiskeshavBelum ada peringkat
- AWS90 Ch05 ModalDokumen24 halamanAWS90 Ch05 ModalCinitha ABelum ada peringkat
- Finance at NSUDokumen31 halamanFinance at NSUDuDuWarBelum ada peringkat
- Correct Answer: 3Dokumen11 halamanCorrect Answer: 3Neha VermaBelum ada peringkat
- Ring Programming Language Book - Part 56 of 84Dokumen10 halamanRing Programming Language Book - Part 56 of 84Mahmoud Samir FayedBelum ada peringkat
- Heat of Fusion of WaterDokumen6 halamanHeat of Fusion of WaterAishaBelum ada peringkat
- Theoretical Evaluation On Effects of Opening On Ultimate Load-Carrying Capacity of Square SlabsDokumen8 halamanTheoretical Evaluation On Effects of Opening On Ultimate Load-Carrying Capacity of Square Slabsfoush bashaBelum ada peringkat
- Problems and Exercises Assigned For ELEC4502 - Week 0Dokumen7 halamanProblems and Exercises Assigned For ELEC4502 - Week 0voonmingchooBelum ada peringkat
- Vector Calculus QuestionsDokumen3 halamanVector Calculus Questionsrachitzan10Belum ada peringkat
- Design and Comparison of Axial-Flux Permanent Magnet Motors For In-Wheel Electric Vehicles by 3DFEMDokumen6 halamanDesign and Comparison of Axial-Flux Permanent Magnet Motors For In-Wheel Electric Vehicles by 3DFEMSeksan KhamkaewBelum ada peringkat
- SMR PYQs 7-9Dokumen6 halamanSMR PYQs 7-9TRY UP GamingBelum ada peringkat
- Scrapbook Info GGGGDokumen5 halamanScrapbook Info GGGGDanstan Ferrolino Genova IIBelum ada peringkat
- Stiffness Versus Strength PDFDokumen4 halamanStiffness Versus Strength PDFHyunkyoun JinBelum ada peringkat
- Fast Hardware Computation of X Mod Z: J. T. Butler T. SasaoDokumen5 halamanFast Hardware Computation of X Mod Z: J. T. Butler T. Sasaoshashank guptaBelum ada peringkat
- Lesson PlanDokumen5 halamanLesson PlanAnn Francis SalonBelum ada peringkat
- OFDM Matlab CodeDokumen5 halamanOFDM Matlab CodeKool Rakesh100% (1)
- 03 Chapter 3 - Statistical EstimationDokumen17 halaman03 Chapter 3 - Statistical EstimationYohanna SisayBelum ada peringkat
- Top Expected Reasoning Questions For Bank Mains Exams PDFDokumen119 halamanTop Expected Reasoning Questions For Bank Mains Exams PDFAdarshKumarBelum ada peringkat