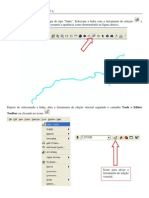
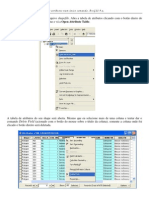
Anda mungkin juga menyukai
- Apostila Topografia Selma AbrahãoDokumen98 halamanApostila Topografia Selma AbrahãoRaphael MoreiraBelum ada peringkat
- Estatística Descritiva EDITADODokumen148 halamanEstatística Descritiva EDITADOMário Augusto GarciaBelum ada peringkat
- Lista de Engenharia de SoftwareDokumen4 halamanLista de Engenharia de SoftwareTatiana SilvaBelum ada peringkat
- Apostila 2 - MAT236Dokumen82 halamanApostila 2 - MAT236Léo Sales100% (1)
- ECONOMETRIA - 2018 - 2 02 Econometria Com R - RStudio PDFDokumen31 halamanECONOMETRIA - 2018 - 2 02 Econometria Com R - RStudio PDFAsafe Emanuel100% (1)
- Tutorial GeoDa PDFDokumen20 halamanTutorial GeoDa PDFDiego PalmiereBelum ada peringkat
- Análise Exploratória de Dados Usando o RDokumen92 halamanAnálise Exploratória de Dados Usando o RArmandoCamaraNinoBelum ada peringkat
- Análise Espacial de Dados GeográficosDokumen189 halamanAnálise Espacial de Dados GeográficosLeonardo Santa RitaBelum ada peringkat
- Analise Espacial de Dados GeográficosDokumen16 halamanAnalise Espacial de Dados GeográficosdematosbrBelum ada peringkat
- Ensaio de Permeabilidade em Solos - 4 Ed - Ano 2013Dokumen80 halamanEnsaio de Permeabilidade em Solos - 4 Ed - Ano 2013Pro solo SondagensBelum ada peringkat
- IntrodSIG QGIS IBGE PDFDokumen144 halamanIntrodSIG QGIS IBGE PDFRicardo Vilar NevesBelum ada peringkat
- Usando R e GEE Book T1Dokumen49 halamanUsando R e GEE Book T1Monteiro FerreiraBelum ada peringkat
- Sistema de Informação de Apoio A Detecção de Perdas de Energia Eléctrica - o Caso Da ElectraDokumen140 halamanSistema de Informação de Apoio A Detecção de Perdas de Energia Eléctrica - o Caso Da ElectraAnonymous a6U4EnBelum ada peringkat
- Da Climatologia Geográfica À Geografia Do ClimaDokumen22 halamanDa Climatologia Geográfica À Geografia Do ClimaPauloCesarPassosBelum ada peringkat
- Processos Estocasticos 1 Slide PGDokumen51 halamanProcessos Estocasticos 1 Slide PGceuzinBelum ada peringkat
- Aula 02Dokumen29 halamanAula 02Ze Nilto Pereira100% (1)
- Multivariada Com o RDokumen131 halamanMultivariada Com o RJoelmir MazonBelum ada peringkat
- CIVIL 3D - CorredoresDokumen47 halamanCIVIL 3D - CorredoresJose SantosBelum ada peringkat
- Qgis218 Desenhar Poligonal Por Azimute e Distancia PDFDokumen21 halamanQgis218 Desenhar Poligonal Por Azimute e Distancia PDFsobadBelum ada peringkat
- HiPer V PortuguesDokumen122 halamanHiPer V PortuguesThiago PaimBelum ada peringkat
- GEOMATLABDokumen17 halamanGEOMATLABEdilbertoLópezBelum ada peringkat
- Apostila Arcgis10.1 PDFDokumen25 halamanApostila Arcgis10.1 PDFKayrone MarvilaBelum ada peringkat
- Trabalhando Com Dados de Terreno No Global Mapper 20-01-15Dokumen53 halamanTrabalhando Com Dados de Terreno No Global Mapper 20-01-15barboseraBelum ada peringkat
- Apostila Estat Sitca 2 Semestre 2011Dokumen117 halamanApostila Estat Sitca 2 Semestre 2011César MadeiraBelum ada peringkat
- Volume - TopographDokumen17 halamanVolume - TopographJohny MouraBelum ada peringkat
- Apostila Topografia I 2014Dokumen79 halamanApostila Topografia I 2014Daniel OcBelum ada peringkat
- Praticas Idrisi TaigaDokumen57 halamanPraticas Idrisi TaigaCaio Dafico100% (1)
- Segredos Da Estatistica Com 100 Exercc3adcios Resolvidos 9 Julho 2014 D PDFDokumen131 halamanSegredos Da Estatistica Com 100 Exercc3adcios Resolvidos 9 Julho 2014 D PDFTiagoBenzinha100% (1)
- Manual GPS GarminDokumen54 halamanManual GPS GarminVDFBelum ada peringkat
- Apostila JavaScript Fundamentos 01Dokumen78 halamanApostila JavaScript Fundamentos 01rebmsBelum ada peringkat
- Apostilade CRP192 Iniciacaoa EstatisticaDokumen151 halamanApostilade CRP192 Iniciacaoa EstatisticaThays Dos Santos CardosoBelum ada peringkat
- Statistica 6 Capitulo1a7Dokumen133 halamanStatistica 6 Capitulo1a7Carlos BarbosaBelum ada peringkat
- Apostila Do Software Past para Ecologia PDFDokumen22 halamanApostila Do Software Past para Ecologia PDFGabrielle Abreu NunesBelum ada peringkat
- Exercícios de ModelagemDokumen12 halamanExercícios de Modelagemcharlesfp1Belum ada peringkat
- Quebrar Linha Manualmente No ArcGIS "Ferramenta SPLT"Dokumen2 halamanQuebrar Linha Manualmente No ArcGIS "Ferramenta SPLT"Luis Henrique LopesBelum ada peringkat
- Analise Exploratoria de Dados (Franzé Costa)Dokumen74 halamanAnalise Exploratoria de Dados (Franzé Costa)VitorAmorimBelum ada peringkat
- MiniCurso - Introd Econometria Espacial PDFDokumen77 halamanMiniCurso - Introd Econometria Espacial PDFMarcoJulioKolinskyBelum ada peringkat
- Controle e AutomaçãoDokumen4 halamanControle e AutomaçãoBruna AlcântaraBelum ada peringkat
- Construção Do Variograma em SurferDokumen9 halamanConstrução Do Variograma em SurferverdaoleaoBelum ada peringkat
- Delete Varias Colunas Na Tabela de Aributos Num Clique No ArcGISDokumen2 halamanDelete Varias Colunas Na Tabela de Aributos Num Clique No ArcGISLuis Henrique LopesBelum ada peringkat
- Gps Topcon Hiper Lite Plus-Simeao 02Dokumen16 halamanGps Topcon Hiper Lite Plus-Simeao 02juniorvilalbaBelum ada peringkat
- Análise de ResíduosDokumen2 halamanAnálise de ResíduosEdson_victor21Belum ada peringkat
- 01 - ESTAT - Estatística DescritivaDokumen52 halaman01 - ESTAT - Estatística DescritivaLuis SousaBelum ada peringkat
- AutoCAD Civil 3D 2011 - Treinamento Hands-OnDokumen128 halamanAutoCAD Civil 3D 2011 - Treinamento Hands-OnericfgBelum ada peringkat
- Iot Para Medir Dinamômetro Com Esp32 Programado Em ArduinoDari EverandIot Para Medir Dinamômetro Com Esp32 Programado Em ArduinoBelum ada peringkat
- Geoinformação E Análises SocioambientaisDari EverandGeoinformação E Análises SocioambientaisBelum ada peringkat
- Procedimentos Para Automatizar O Cálculo De Áreas TopográficasDari EverandProcedimentos Para Automatizar O Cálculo De Áreas TopográficasBelum ada peringkat
- Sensoriamento remoto: Princípios e aplicaçõesDari EverandSensoriamento remoto: Princípios e aplicaçõesBelum ada peringkat
- Análises Ecológicas No RDari EverandAnálises Ecológicas No RBelum ada peringkat
- Técnicas Multivariadas Exploratórias: Teorias e Aplicações no Software Statistica©Dari EverandTécnicas Multivariadas Exploratórias: Teorias e Aplicações no Software Statistica©Belum ada peringkat
- UNISUL DL - Unidade 1Dokumen32 halamanUNISUL DL - Unidade 1QueilaBelum ada peringkat
- Va3 Relatório Angelo Cruz Fonseca Da SilvaDokumen9 halamanVa3 Relatório Angelo Cruz Fonseca Da SilvaDanilo CruzBelum ada peringkat
- MODULO I - Analise Estatistica de Dados e SPSS 2021Dokumen3 halamanMODULO I - Analise Estatistica de Dados e SPSS 2021Fopenze NhacafulaBelum ada peringkat
- Slides SPSSDokumen122 halamanSlides SPSSClaudia MendesBelum ada peringkat
- Analise de Dados Utilizando Graficos BoxDokumen9 halamanAnalise de Dados Utilizando Graficos Box597930Belum ada peringkat
- Guia Pratico de SPSS (Mestre Osvaldo Borges) - AcetatosDokumen41 halamanGuia Pratico de SPSS (Mestre Osvaldo Borges) - AcetatosManuel António Pereira SemedoBelum ada peringkat
- AQD - Plano de Ensino 2023-1Dokumen5 halamanAQD - Plano de Ensino 2023-1Leonardo GontijoBelum ada peringkat
- Utilizacao Da Base de Dados Do Instituto Brasileiro de GeografiaDokumen20 halamanUtilizacao Da Base de Dados Do Instituto Brasileiro de GeografiaBeatriz AssiateBelum ada peringkat
- Estudo Da Viabilidade Do Uso Do Software Geogebra No Ensino de EstatisticaDokumen9 halamanEstudo Da Viabilidade Do Uso Do Software Geogebra No Ensino de Estatisticasapoha testandoBelum ada peringkat
- A Relação Campo-Cidade e Suas Leituras No Espaço PDFDokumen9 halamanA Relação Campo-Cidade e Suas Leituras No Espaço PDFGustavo CostaBelum ada peringkat
- O Ensino Da Geografia Nas Instituições de Ensino Superior em AngolaDokumen15 halamanO Ensino Da Geografia Nas Instituições de Ensino Superior em Angolaisaac simão santoBelum ada peringkat
- Estudo Do Texto A Geografia Como CiênciaDokumen2 halamanEstudo Do Texto A Geografia Como CiênciaKlebson RamonBelum ada peringkat
- Conteúdos Objetos de Conhecimento Habilidades BNCCDokumen3 halamanConteúdos Objetos de Conhecimento Habilidades BNCCLeandro Martins100% (1)
- Castro Alves Poesia e História Da CidadeDokumen15 halamanCastro Alves Poesia e História Da CidadePaulo HenriqueBelum ada peringkat
- 27130-Texto Do Artigo-102187-1-10-20211216Dokumen25 halaman27130-Texto Do Artigo-102187-1-10-20211216Geoman BahiaBelum ada peringkat
- Dorem Massay - Imaginando A GlobalizaçãoDokumen14 halamanDorem Massay - Imaginando A GlobalizaçãoCláudio SmalleyBelum ada peringkat
- Placas TectonicasDokumen4 halamanPlacas TectonicasKelly RiguesBelum ada peringkat
- Da Ecologia À Arquitetura Da Paisagem PDFDokumen137 halamanDa Ecologia À Arquitetura Da Paisagem PDFAline GonçalvesBelum ada peringkat
- Fundep Gestao de Concursos 2019 Prefeitura de Lagoa Santa MG Analista Administrativo ProvaDokumen14 halamanFundep Gestao de Concursos 2019 Prefeitura de Lagoa Santa MG Analista Administrativo ProvaDiegoBelum ada peringkat
- Kit de PascoaDokumen29 halamanKit de PascoaJane SantosBelum ada peringkat
- Questionário Geografia Bíblica 1 - 09-04-181Dokumen1 halamanQuestionário Geografia Bíblica 1 - 09-04-181GILBERTO VALIMBelum ada peringkat
- Bizurometro de GeografiaDokumen25 halamanBizurometro de GeografiaK WBelum ada peringkat
- Introdução A Fontes de InformaçãoDokumen30 halamanIntrodução A Fontes de InformaçãoÉden RodriguesBelum ada peringkat
- Afforest - Método Miyawaki CompletoDokumen11 halamanAfforest - Método Miyawaki CompletoAbsentia BelliBelum ada peringkat
- Fundamentos Da Ciência PolíticaDokumen182 halamanFundamentos Da Ciência Políticasouza900Belum ada peringkat
- 2º Simulado Geografia ModificadoDokumen4 halaman2º Simulado Geografia ModificadoBryan AmadorBelum ada peringkat
- PROJETO AfricanidadesDokumen7 halamanPROJETO AfricanidadesROMERITO10Belum ada peringkat
- Archetekton: Algumas Considerações A Respeito Do Trabalho Do Arquiteto Na Grécia AntigaDokumen14 halamanArchetekton: Algumas Considerações A Respeito Do Trabalho Do Arquiteto Na Grécia AntigaJaquelineRibeiroBelum ada peringkat
- Tutorial MapaDokumen24 halamanTutorial MapaIvan BlandeBelum ada peringkat
- Plano de Ensino 2 - História - 8º Ano (Anos Finais)Dokumen5 halamanPlano de Ensino 2 - História - 8º Ano (Anos Finais)Ellem MendesBelum ada peringkat
- Estudo de GeografiaDokumen2 halamanEstudo de GeografiaKaren GalvãoBelum ada peringkat
- Fontes Da Informação - Fontes Primárias, Secundárias e TerciáriasDokumen5 halamanFontes Da Informação - Fontes Primárias, Secundárias e TerciáriasLine FSilvaBelum ada peringkat
- Classe HospitalarDokumen254 halamanClasse HospitalarElisangela Castedo MariaBelum ada peringkat
- IBN KHALDUN PortuguesDokumen10 halamanIBN KHALDUN PortuguesargomillaBelum ada peringkat
- Leis Do Modelado - ABR 2018 - CART SIG - 07MAR PDFDokumen70 halamanLeis Do Modelado - ABR 2018 - CART SIG - 07MAR PDFTyago Andrade100% (1)
- MENDES Claudinei Magno Magre - Política e História em Caio Prado JúniorDokumen220 halamanMENDES Claudinei Magno Magre - Política e História em Caio Prado JúniorEstudos Brasileiros USPBelum ada peringkat
- Plano Semestral Filosofia 2 Ano 2023 GOVERNO DO ESTADO DO MARANHÃODokumen2 halamanPlano Semestral Filosofia 2 Ano 2023 GOVERNO DO ESTADO DO MARANHÃORaimunda GonçalvesBelum ada peringkat
- ANAIS Final Evento Regional Dez 2016Dokumen1.184 halamanANAIS Final Evento Regional Dez 2016tyrone_mello100% (1)
- GEOMORFOLODokumen9 halamanGEOMORFOLOOrlando Cristovao RuvaBelum ada peringkat