Anda mungkin juga menyukai
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Some Technical Aspects of Open Pit Mine Dewatering: Section2Dokumen11 halamanSome Technical Aspects of Open Pit Mine Dewatering: Section2Thiago MarquesBelum ada peringkat
- Present Perfect.Dokumen1 halamanPresent Perfect.Leidy DiazBelum ada peringkat
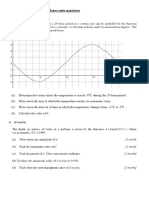
- Sine and Cosine Exam QuestionsDokumen8 halamanSine and Cosine Exam QuestionsGamer Shabs100% (1)
- Coriolis - Atlas CompendiumDokumen62 halamanCoriolis - Atlas CompendiumSquamata100% (2)
- Keb Combivis 6 enDokumen232 halamanKeb Combivis 6 enhaithamBelum ada peringkat
- Method Statement Pressure TestingDokumen15 halamanMethod Statement Pressure TestingAkmaldeen AhamedBelum ada peringkat
- LabManual For Cryptography and Network SecurityDokumen14 halamanLabManual For Cryptography and Network SecurityRajeshkannan Vasinathan100% (2)
- Passive HouseDokumen16 halamanPassive HouseZarkima RanteBelum ada peringkat
- Weight Loss ChartDokumen1 halamanWeight Loss Chartvidi87Belum ada peringkat
- Tnea 2019 OverallDokumen94 halamanTnea 2019 Overallvidi87Belum ada peringkat
- 29.5.23 Lab QuestionsDokumen6 halaman29.5.23 Lab Questionsvidi87Belum ada peringkat
- Eligibility, Parameters, Weightages AICTE-CII Survey 2018Dokumen6 halamanEligibility, Parameters, Weightages AICTE-CII Survey 2018vidi87Belum ada peringkat
- (WWW - Entrance-Exam - Net) - IsRO Sample Paper 7Dokumen6 halaman(WWW - Entrance-Exam - Net) - IsRO Sample Paper 7guptadivyanshuBelum ada peringkat
- Graphics and Multimedia: Unit 1 2D PrimitivesDokumen36 halamanGraphics and Multimedia: Unit 1 2D Primitivesvidi87Belum ada peringkat
- 1.principles of ContrastDokumen8 halaman1.principles of Contrastvidi87Belum ada peringkat
- c1cd7b4cdd34596 EkDokumen4 halamanc1cd7b4cdd34596 Ekvidi87Belum ada peringkat
- Mri Images Thresholding For Alzheimer DetectionDokumen10 halamanMri Images Thresholding For Alzheimer DetectionCS & ITBelum ada peringkat
- Automatic Identification and Elimination of Pectoral Muscle in Digital MammogramsDokumen4 halamanAutomatic Identification and Elimination of Pectoral Muscle in Digital Mammogramsvidi87Belum ada peringkat
- Formula PaperDokumen3 halamanFormula PaperKampa LavanyaBelum ada peringkat
- Screen ShotsDokumen15 halamanScreen Shotsvidi87Belum ada peringkat
- An Introduction To Networking TerminologyDokumen18 halamanAn Introduction To Networking Terminologyvidi87Belum ada peringkat
- Pre ProcessingDokumen9 halamanPre Processingvidi87Belum ada peringkat
- Asst 2 IAPDokumen2 halamanAsst 2 IAPvidi87Belum ada peringkat
- CP Question BankDokumen4 halamanCP Question Bankvidi87Belum ada peringkat
- Asst 2 IAPDokumen2 halamanAsst 2 IAPvidi87Belum ada peringkat
- 16Dokumen18 halaman16vidi87Belum ada peringkat
- CP7101 Design and Management of Computer Networks Important and Model Question PaperDokumen1 halamanCP7101 Design and Management of Computer Networks Important and Model Question PaperJai SharmaBelum ada peringkat
- IiitadvDokumen7 halamanIiitadvvidi87Belum ada peringkat
- Excel Multiple Choice QuestionsDokumen31 halamanExcel Multiple Choice QuestionsrajBelum ada peringkat
- Iiiiiiiiii: Verview OF Omputer YstemsDokumen8 halamanIiiiiiiiii: Verview OF Omputer YstemscristigoBelum ada peringkat
- QSD/CHE Department Meeting AgendaDokumen1 halamanQSD/CHE Department Meeting Agendavidi87Belum ada peringkat
- Ontologies: Principles, Methods and Applications GuideDokumen69 halamanOntologies: Principles, Methods and Applications Guidevidi87Belum ada peringkat
- 00839119Dokumen5 halaman00839119vidi87Belum ada peringkat
- Dxgbvi Abdor Rahim OsmanmrDokumen1 halamanDxgbvi Abdor Rahim OsmanmrSakhipur TravelsBelum ada peringkat
- Degrees of Comparison: When We Compare Two Nouns: Comparative. When We Compare Three or More Nouns: SuperlativeDokumen6 halamanDegrees of Comparison: When We Compare Two Nouns: Comparative. When We Compare Three or More Nouns: SuperlativeMerlina AryantiBelum ada peringkat
- Reg OPSDokumen26 halamanReg OPSAlexandru RusuBelum ada peringkat
- Construction Internship ReportDokumen8 halamanConstruction Internship ReportDreaminnBelum ada peringkat
- Product 243: Technical Data SheetDokumen3 halamanProduct 243: Technical Data SheetRuiBelum ada peringkat
- Mumbai Tourist Attractions.Dokumen2 halamanMumbai Tourist Attractions.Guru SanBelum ada peringkat
- Froyen06-The Keynesian System I - The Role of Aggregate DemandDokumen40 halamanFroyen06-The Keynesian System I - The Role of Aggregate DemandUditi BiswasBelum ada peringkat
- Sustainability 15 06202Dokumen28 halamanSustainability 15 06202Somesh AgrawalBelum ada peringkat
- Self-Learning Home Task (SLHT) : Describe The Impact ofDokumen9 halamanSelf-Learning Home Task (SLHT) : Describe The Impact ofJeffrey FloresBelum ada peringkat
- Uses of The Internet in Our Daily LifeDokumen20 halamanUses of The Internet in Our Daily LifeMar OcolBelum ada peringkat
- Future War in Cities Alice Hills PDFDokumen5 halamanFuture War in Cities Alice Hills PDFazardarioBelum ada peringkat
- Nistha Tamrakar Chicago Newa VIIDokumen2 halamanNistha Tamrakar Chicago Newa VIIKeshar Man Tamrakar (केशरमान ताम्राकार )Belum ada peringkat
- Pakistan Affairs Current Affairs 2016 MCQSDokumen3 halamanPakistan Affairs Current Affairs 2016 MCQSMuhammad MudassarBelum ada peringkat
- GF26.10-S-0002S Manual Transmission (MT), Function 9.7.03 Transmission 716.6 in MODEL 639.601 /603 /605 /701 /703 /705 /711 /713 /811 /813 /815Dokumen2 halamanGF26.10-S-0002S Manual Transmission (MT), Function 9.7.03 Transmission 716.6 in MODEL 639.601 /603 /605 /701 /703 /705 /711 /713 /811 /813 /815Sven GoshcBelum ada peringkat
- Report On Indian Airlines Industry On Social Media, Mar 2015Dokumen9 halamanReport On Indian Airlines Industry On Social Media, Mar 2015Vang LianBelum ada peringkat
- 3.6 God Provides Water and Food MaryDokumen22 halaman3.6 God Provides Water and Food MaryHadassa ArzagaBelum ada peringkat
- Investigation Report on Engine Room Fire on Ferry BerlinDokumen63 halamanInvestigation Report on Engine Room Fire on Ferry Berlin卓文翔Belum ada peringkat
- Affidavit of 2 Disinterested Persons (Haidee Gullodo)Dokumen1 halamanAffidavit of 2 Disinterested Persons (Haidee Gullodo)GersonGamasBelum ada peringkat
- DISADVANTAGESDokumen3 halamanDISADVANTAGESMhd MiranBelum ada peringkat
- Instruction Manual PC Interface RSM 100: TOSHIBA Corporation 1999 All Rights ReservedDokumen173 halamanInstruction Manual PC Interface RSM 100: TOSHIBA Corporation 1999 All Rights ReservedFarid HakikiBelum ada peringkat
- CV. Anderson Hario Pangestiaji (English Version)Dokumen5 halamanCV. Anderson Hario Pangestiaji (English Version)Anderson PangestiajiBelum ada peringkat
- Move Over G7, It's Time For A New and Improved G11: Long ShadowDokumen16 halamanMove Over G7, It's Time For A New and Improved G11: Long ShadowVidhi SharmaBelum ada peringkat
- Chapter 9 Lease DecisionsDokumen51 halamanChapter 9 Lease Decisionsceoji25% (4)