Anda mungkin juga menyukai
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Cost Models-Pillars For Efficient Cloud ComputingDokumen12 halamanCost Models-Pillars For Efficient Cloud Computingdelia2011Belum ada peringkat
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Evaluating Integrated Watershed Management Using Multiple Criteria Analysis-A Case Study at Chittagong Hill Tracts in BangladeshDokumen21 halamanEvaluating Integrated Watershed Management Using Multiple Criteria Analysis-A Case Study at Chittagong Hill Tracts in Bangladeshdelia2011Belum ada peringkat
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Energy-Efficient Cluster Head Selection Scheme Based On Multiple Criteria Decision Making For Wireless Sensor NetworksDokumen24 halamanEnergy-Efficient Cluster Head Selection Scheme Based On Multiple Criteria Decision Making For Wireless Sensor Networksdelia2011Belum ada peringkat
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Multiple Criteria Districting Problems: The Public Transportation Network Pricing System of The Paris RegionDokumen24 halamanMultiple Criteria Districting Problems: The Public Transportation Network Pricing System of The Paris Regiondelia2011Belum ada peringkat
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Plugin art%3A10.1007%2Fs00158 010 0613 8Dokumen12 halamanPlugin art%3A10.1007%2Fs00158 010 0613 8delia2011Belum ada peringkat
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- A General Fuzzy TOPSIS Model in Multiple Criteria Decision MakingDokumen15 halamanA General Fuzzy TOPSIS Model in Multiple Criteria Decision Makingdelia2011Belum ada peringkat
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- A Primogenitary Linked Quad Tree Data Structure and Its Application To Discrete Multiple Criteria OptimizationDokumen21 halamanA Primogenitary Linked Quad Tree Data Structure and Its Application To Discrete Multiple Criteria Optimizationdelia2011Belum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- International Symposium On Nanoparticles: Technology and Sustainable Development,' Taipei, Taiwan, September 9-10, 2002Dokumen3 halamanInternational Symposium On Nanoparticles: Technology and Sustainable Development,' Taipei, Taiwan, September 9-10, 2002delia2011Belum ada peringkat
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- Plugin art%3A10.1007%2Fs11267 008 9203 9Dokumen1 halamanPlugin art%3A10.1007%2Fs11267 008 9203 9delia2011Belum ada peringkat
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- Plugin art%3A10.1007%2Fs11269 011 9888 9Dokumen2 halamanPlugin art%3A10.1007%2Fs11269 011 9888 9delia2011Belum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Plugin art%3A10.1007%2Fs11625 009 0072 6Dokumen2 halamanPlugin art%3A10.1007%2Fs11625 009 0072 6delia2011Belum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Propose A Model To Choose Best Project by AHP in Distributed GenerationDokumen4 halamanPropose A Model To Choose Best Project by AHP in Distributed Generationdelia2011Belum ada peringkat
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Measuring The Efficiency of Production Units by AHP Models: Josef JablonskyDokumen8 halamanMeasuring The Efficiency of Production Units by AHP Models: Josef Jablonskydelia2011Belum ada peringkat
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- Face Recognition Using LBPHDokumen16 halamanFace Recognition Using LBPHShaileshBelum ada peringkat
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- Problem Solving Through ProgrammingDokumen2 halamanProblem Solving Through Programmingsaravanan chandrasekaranBelum ada peringkat
- Fundamentals of Multibody Dynamics: Farid AmiroucheDokumen7 halamanFundamentals of Multibody Dynamics: Farid AmiroucheVijay ChhillarBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Section 3 Newton Divided-Difference Interpolating PolynomialsDokumen43 halamanSection 3 Newton Divided-Difference Interpolating PolynomialsShawn GonzalesBelum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Data Structures: Course Code: USIT302Dokumen7 halamanData Structures: Course Code: USIT302AjayBelum ada peringkat
- Multiple Choice QuestionsDokumen8 halamanMultiple Choice QuestionsBan Le VanBelum ada peringkat
- 14 Different Types of Learning in Machine LearningDokumen2 halaman14 Different Types of Learning in Machine LearningWilliam OlissBelum ada peringkat
- Quantum Sciam05Dokumen6 halamanQuantum Sciam05J PabloBelum ada peringkat
- B ATPGDokumen98 halamanB ATPGxinxiang365Belum ada peringkat
- Converting A Normal Random Variable: Ask QuestionDokumen4 halamanConverting A Normal Random Variable: Ask QuestionGLADY VIDALBelum ada peringkat
- Presantation - Chapter 06 - Brute Force and Exhaustive SearchDokumen68 halamanPresantation - Chapter 06 - Brute Force and Exhaustive SearchDesadaBelum ada peringkat
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- EMM 3514 - Numerical MethodDokumen33 halamanEMM 3514 - Numerical MethodAdhar GoodBelum ada peringkat
- Lecture 08-Gauss-EleminationDokumen55 halamanLecture 08-Gauss-EleminationMaria Anndrea MendozaBelum ada peringkat
- Python Program For Dijkstra's Shortest Path Algorithm - Greedy Algo-7 - GeeksforGeeksDokumen6 halamanPython Program For Dijkstra's Shortest Path Algorithm - Greedy Algo-7 - GeeksforGeeksmmorad aamraouyBelum ada peringkat
- Non Deterministic Finite AutomataDokumen37 halamanNon Deterministic Finite AutomataMarryam ZulfiqarBelum ada peringkat
- SchedulingDokumen44 halamanSchedulingapi-19975941Belum ada peringkat
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Decision ModelsDokumen19 halamanDecision ModelsChetan TgBelum ada peringkat
- Lecture Notes: Programming Quantum ComputersDokumen36 halamanLecture Notes: Programming Quantum Computersmakumba1972Belum ada peringkat
- Numerical Analysis in Engineering: Taylor SeriesDokumen28 halamanNumerical Analysis in Engineering: Taylor SeriesCollano M. Noel RogieBelum ada peringkat
- Survival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)Dokumen3 halamanSurvival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)irsadBelum ada peringkat
- Digital Control Systems (DCS) : Lecture-1-2 Lead CompensationDokumen61 halamanDigital Control Systems (DCS) : Lecture-1-2 Lead CompensationMeer Zafarullah NoohaniBelum ada peringkat
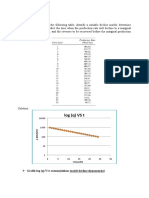
- Problems: Log (Q) VS TDokumen8 halamanProblems: Log (Q) VS TDianita ZuamaBelum ada peringkat
- 11 Sliding Mode ControlDokumen9 halaman11 Sliding Mode ControlKgotsofalang Kayson NqhwakiBelum ada peringkat
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- SG Unit1progresscheckmcqpartc 5d98d17329c205.75481124Dokumen10 halamanSG Unit1progresscheckmcqpartc 5d98d17329c205.75481124bl2ckiceBelum ada peringkat
- Generalized Linear ModelDokumen67 halamanGeneralized Linear Modelshanthikk3Belum ada peringkat
- Syllabus: Department of Mechanical EngineeringDokumen2 halamanSyllabus: Department of Mechanical EngineeringChhagan kharolBelum ada peringkat
- The RSA AlgorithmDokumen31 halamanThe RSA AlgorithmbyprasadBelum ada peringkat
- Lock-Free and Practical Deques Using Single-Word Compare-And-SwapDokumen17 halamanLock-Free and Practical Deques Using Single-Word Compare-And-Swapjenana4059Belum ada peringkat
- Daa MCQDokumen28 halamanDaa MCQNEHAL KUBADEBelum ada peringkat
- Normal Distribution WorksheetDokumen5 halamanNormal Distribution Worksheetapi-534996578Belum ada peringkat