Anda mungkin juga menyukai
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Orlando TB Me 2016Dokumen19 halamanOrlando TB Me 2016José Ignacio OrlandoBelum ada peringkat
- Think Stats: Probability and Statistics For ProgrammersDokumen140 halamanThink Stats: Probability and Statistics For ProgrammersIka KristinBelum ada peringkat
- Zheng2012automated - AriaDokumen9 halamanZheng2012automated - AriaJosé Ignacio OrlandoBelum ada peringkat
- Owen2009measuring - Chasedb1Dokumen7 halamanOwen2009measuring - Chasedb1José Ignacio OrlandoBelum ada peringkat
- Comparative study of retinal vessel segmentation methods on new publicly available databaseDokumen9 halamanComparative study of retinal vessel segmentation methods on new publicly available databaseJosé Ignacio OrlandoBelum ada peringkat
- SikDokumen58 halamanSikJosé Ignacio OrlandoBelum ada peringkat
- Fully Automated Brain Tumor Segmentation Using Improved Fuzzy ConnectednessDokumen10 halamanFully Automated Brain Tumor Segmentation Using Improved Fuzzy ConnectednessJosé Ignacio OrlandoBelum ada peringkat
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Species Diversity in Lentic and Lotic Systems of Lake Tamblyn and The Mcintyre RiverDokumen21 halamanSpecies Diversity in Lentic and Lotic Systems of Lake Tamblyn and The Mcintyre Riverapi-393048315Belum ada peringkat
- Alternate Mekton Zeta Weapon CreationDokumen7 halamanAlternate Mekton Zeta Weapon CreationJavi BuenoBelum ada peringkat
- A Sample of The Completed Essential Principles Conformity Checklist MD CCLDokumen12 halamanA Sample of The Completed Essential Principles Conformity Checklist MD CCLAyman Ali100% (1)
- Nursing Care PlansDokumen10 halamanNursing Care PlansGracie S. Vergara100% (1)
- Carpentry Shop: Building, Doors, Windows, Trusses, WorkbenchesDokumen105 halamanCarpentry Shop: Building, Doors, Windows, Trusses, WorkbenchesVinod KumarBelum ada peringkat
- Solcon Catalog WebDokumen12 halamanSolcon Catalog Webquocviet612Belum ada peringkat
- AYUSHMAN BHARAT Operationalizing Health and Wellness CentresDokumen34 halamanAYUSHMAN BHARAT Operationalizing Health and Wellness CentresDr. Sachendra Raj100% (1)
- Board Review Endocrinology A. ApiradeeDokumen47 halamanBoard Review Endocrinology A. ApiradeePiyasak NaumnaBelum ada peringkat
- Indonesia Organic Farming 2011 - IndonesiaDOCDokumen18 halamanIndonesia Organic Farming 2011 - IndonesiaDOCJamal BakarBelum ada peringkat
- Cell City ProjectDokumen8 halamanCell City ProjectDaisy beBelum ada peringkat
- Measure BlowingDokumen52 halamanMeasure BlowingLos Ángeles Customs GarageBelum ada peringkat
- RHS NCRPO COVID FormDokumen1 halamanRHS NCRPO COVID Formspd pgsBelum ada peringkat
- The National Building Code of The PhilippinesDokumen390 halamanThe National Building Code of The PhilippinesJohn Joseph EstebanBelum ada peringkat
- Esaote MyLabX7Dokumen12 halamanEsaote MyLabX7Neo BiosBelum ada peringkat
- Manual Masina de Spalat Slim SamsungDokumen1.020 halamanManual Masina de Spalat Slim SamsungPerfectreviewBelum ada peringkat
- Analisis Dampak Reklamasi Teluk Banten Terhadap Kondisi Lingkungan Dan Sosial EkonomiDokumen10 halamanAnalisis Dampak Reklamasi Teluk Banten Terhadap Kondisi Lingkungan Dan Sosial EkonomiSYIFA ABIYU SAGITA 08211840000099Belum ada peringkat
- Erapol EHP95ADokumen2 halamanErapol EHP95AMohammad Doost MohammadiBelum ada peringkat
- Spec BoilerDokumen9 halamanSpec BoilerAchmad MakmuriBelum ada peringkat
- Thee Correlational Study of Possittive Emotionons and Coping Strategies For Academic Stress Among CASS Studentts - updaTEDDokumen23 halamanThee Correlational Study of Possittive Emotionons and Coping Strategies For Academic Stress Among CASS Studentts - updaTEDJuliet AcelBelum ada peringkat
- Workplace Hazard Analysis ProcedureDokumen12 halamanWorkplace Hazard Analysis ProcedureKent Nabz60% (5)
- Case Report on Right Knee FuruncleDokumen47 halamanCase Report on Right Knee Furuncle馮宥忻Belum ada peringkat
- Benefits at Cognizant Technology SolutionsDokumen5 halamanBenefits at Cognizant Technology Solutions8130089011Belum ada peringkat
- Nicenstripy Gardening Risk AssessmentDokumen38 halamanNicenstripy Gardening Risk AssessmentVirta Nisa100% (1)
- Grade Eleven Test 2019 Social StudiesDokumen6 halamanGrade Eleven Test 2019 Social StudiesClair VickerieBelum ada peringkat
- Activity No 1 - Hydrocyanic AcidDokumen4 halamanActivity No 1 - Hydrocyanic Acidpharmaebooks100% (2)
- Request For Review FormDokumen11 halamanRequest For Review FormJoel MillerBelum ada peringkat
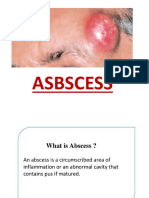
- ABSCESSDokumen35 halamanABSCESSlax prajapatiBelum ada peringkat
- Allium CepaDokumen90 halamanAllium CepaYosr Ahmed100% (3)
- Haematology Notes - 3rd EdDokumen100 halamanHaematology Notes - 3rd EdSally Brit100% (1)
- Reach Out and Read Georgia Selected For AJC Peachtree Road Race Charity Partner ProgramDokumen2 halamanReach Out and Read Georgia Selected For AJC Peachtree Road Race Charity Partner ProgramPR.comBelum ada peringkat