Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- Hypertrophy Cluster Training HCT-12Dokumen23 halamanHypertrophy Cluster Training HCT-12Luis Montilla100% (5)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Diagnostic Test in English 7 2019-2020Dokumen4 halamanDiagnostic Test in English 7 2019-2020Christine Pugosa Inocencio100% (2)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- A Practical Handbook of Language Teaching by David CrossDokumen303 halamanA Practical Handbook of Language Teaching by David CrossLIZZETH ENRIQUEZ MACIAS100% (1)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Art and Design: Inside Listening and Speaking 3 Unit 3 Answer KeyDokumen6 halamanArt and Design: Inside Listening and Speaking 3 Unit 3 Answer KeyLâm Duy0% (2)
- 5 UPSR Trial BI (Paper 1 and 2) Perlis 2018 SJKC + JWPDokumen14 halaman5 UPSR Trial BI (Paper 1 and 2) Perlis 2018 SJKC + JWPzaheiraBelum ada peringkat
- Berberine Prevents Nigrostriatal Dopaminergic Neuronal Loss and Suppresses Hippocampal Apoptosis in Mice With Parkinson's DiseaseDokumen9 halamanBerberine Prevents Nigrostriatal Dopaminergic Neuronal Loss and Suppresses Hippocampal Apoptosis in Mice With Parkinson's DiseaseAnonymous WpMUZCb935Belum ada peringkat
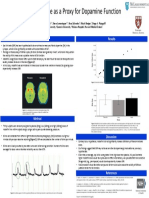
- Eye Blink Rate As A Proxy For Dopamine FunctionDokumen1 halamanEye Blink Rate As A Proxy For Dopamine FunctionAnonymous WpMUZCb935Belum ada peringkat
- Vitamin A and Sleep RegulationDokumen8 halamanVitamin A and Sleep RegulationAnonymous WpMUZCb935Belum ada peringkat
- 2018 Medicare Physician Fee Schedule SLPDokumen14 halaman2018 Medicare Physician Fee Schedule SLPAnonymous WpMUZCb935Belum ada peringkat
- Akkadian Empire - Wikipedia, The Free EncyclopediaDokumen21 halamanAkkadian Empire - Wikipedia, The Free EncyclopediaAnonymous WpMUZCb935Belum ada peringkat
- GABA Exerts Protective and Regenerative Effects On Islet Beta Cells and Reverses DiabetesDokumen6 halamanGABA Exerts Protective and Regenerative Effects On Islet Beta Cells and Reverses DiabetesAnonymous WpMUZCb935Belum ada peringkat
- Metformin Prevents Nigrostriatal Dopamine Degeneration Independent of AMPK Activation in Dopamine NeuronsDokumen15 halamanMetformin Prevents Nigrostriatal Dopamine Degeneration Independent of AMPK Activation in Dopamine NeuronsAnonymous WpMUZCb935Belum ada peringkat
- HDAC Dietary Agents As Histone Deacetylase InhibitorsDokumen4 halamanHDAC Dietary Agents As Histone Deacetylase InhibitorsAnonymous WpMUZCb935Belum ada peringkat
- 161-Point Inspection Checklist: Dealer and Vehicle InformationDokumen6 halaman161-Point Inspection Checklist: Dealer and Vehicle InformationAnonymous WpMUZCb935Belum ada peringkat
- The Biblical Geography of Central Asia Vol 1Dokumen364 halamanThe Biblical Geography of Central Asia Vol 1Anonymous WpMUZCb935Belum ada peringkat
- Affidavit of Process ServerDokumen1 halamanAffidavit of Process ServerAnonymous WpMUZCb935Belum ada peringkat
- What Is Decision MappingDokumen6 halamanWhat Is Decision MappingAnonymous WpMUZCb935Belum ada peringkat
- Go Further: Have Vehicle Questions?Dokumen11 halamanGo Further: Have Vehicle Questions?Anonymous WpMUZCb935Belum ada peringkat
- A Jewish Interpretation of The Book of GenesisDokumen360 halamanA Jewish Interpretation of The Book of GenesisAnonymous WpMUZCb935Belum ada peringkat
- Disconnection Between Amygdala and Medial Prefrontal Cortex in Psychotic DisordersDokumen12 halamanDisconnection Between Amygdala and Medial Prefrontal Cortex in Psychotic DisordersAnonymous WpMUZCb935Belum ada peringkat
- The Biblical Geography of Central Asia Vol 1Dokumen364 halamanThe Biblical Geography of Central Asia Vol 1Anonymous WpMUZCb935Belum ada peringkat
- Veritas, Revelation of Mysteries - MelvilleDokumen179 halamanVeritas, Revelation of Mysteries - MelvilleAnonymous WpMUZCb935100% (4)
- Hall - Ethnic-Identity-in-Greek-Antiquity-Cambridge PDFDokumen242 halamanHall - Ethnic-Identity-in-Greek-Antiquity-Cambridge PDFAnonymous WpMUZCb935100% (1)
- Glutamine Supplements in The Critically IllDokumen3 halamanGlutamine Supplements in The Critically IllAnonymous WpMUZCb935Belum ada peringkat
- Primitive Traditional History Vol I - HewittDokumen477 halamanPrimitive Traditional History Vol I - HewittAnonymous WpMUZCb935100% (1)
- A Welsh Classical DictionaryDokumen90 halamanA Welsh Classical DictionaryAnonymous WpMUZCb935Belum ada peringkat
- Nutrition For SarcopeniaDokumen6 halamanNutrition For SarcopeniaAnonymous WpMUZCb935Belum ada peringkat
- Scythian and Spartan Analogies in Herodotus' Representation: Rites of Initiationa and Kinship GroupsDokumen20 halamanScythian and Spartan Analogies in Herodotus' Representation: Rites of Initiationa and Kinship GroupsAnonymous WpMUZCb935Belum ada peringkat
- Self-Myofascial Release, Purpose, Methods and TechniquesDokumen47 halamanSelf-Myofascial Release, Purpose, Methods and TechniquesJonathan Warncke100% (14)
- Impromptu Speech Planning Using Unified Analysis PDFDokumen3 halamanImpromptu Speech Planning Using Unified Analysis PDFAnonymous WpMUZCb935Belum ada peringkat
- Kingship and Law in The Middle Ages - KernDokumen250 halamanKingship and Law in The Middle Ages - KernAnonymous WpMUZCb935Belum ada peringkat
- Green ManDokumen74 halamanGreen ManXozan100% (8)
- Cities Ranked by Billionaires, 2012 PDFDokumen12 halamanCities Ranked by Billionaires, 2012 PDFAnonymous WpMUZCb935Belum ada peringkat
- CIA Tradecraft Primer Structured Analytic TechniquesDokumen45 halamanCIA Tradecraft Primer Structured Analytic Techniquessmoothoperator30Belum ada peringkat
- English Form 3 Scheme of Work 2015Dokumen8 halamanEnglish Form 3 Scheme of Work 2015Suhana AhmadBelum ada peringkat
- Sound Foundations Phonemic ChartDokumen5 halamanSound Foundations Phonemic ChartCareema ChoongBelum ada peringkat
- Ngữ Âm Âm Vị Trắc NghiệmDokumen14 halamanNgữ Âm Âm Vị Trắc Nghiệmd.duongnguyen1901Belum ada peringkat
- BusPar WB B1PLUS PronunciationDokumen8 halamanBusPar WB B1PLUS PronunciationPhượng (K.NN) Nguyễn Lê TườngBelum ada peringkat
- l1949 Arsen HuastecoDokumen11 halamanl1949 Arsen HuastecoRoberto A. Díaz HernándezBelum ada peringkat
- Teaching Pronunciation: Using The Prosody Pyramid Judy B. GilbertDokumen56 halamanTeaching Pronunciation: Using The Prosody Pyramid Judy B. GilbertSLavBelum ada peringkat
- MFI 2 - Unit 2 - SB - L+SDokumen9 halamanMFI 2 - Unit 2 - SB - L+SHoan HoàngBelum ada peringkat
- 21 Skills You Must Test For A Perfect Call Center - AssessmentDokumen16 halaman21 Skills You Must Test For A Perfect Call Center - AssessmentmrmdnadimBelum ada peringkat
- Topic and FocusDokumen299 halamanTopic and FocusAli Muhammad YousifBelum ada peringkat
- UntitledDokumen152 halamanUntitledLamNguyenBelum ada peringkat
- Pronunciation 2Dokumen34 halamanPronunciation 2Adam PrabowoBelum ada peringkat
- Language TestDokumen80 halamanLanguage TestZit ZestBelum ada peringkat
- Grade 6 Exam FormatDokumen2 halamanGrade 6 Exam FormatrobnovisBelum ada peringkat
- JIPA RussianDokumen8 halamanJIPA RussianArcadio CanepariBelum ada peringkat
- Macro Plan - Class 4Dokumen16 halamanMacro Plan - Class 4Gayathri SenthilmuruganBelum ada peringkat
- Cluster 2Dokumen9 halamanCluster 2Putri Lestari IskandarBelum ada peringkat
- Pathways LS Foundations Independent Student HandbookDokumen6 halamanPathways LS Foundations Independent Student HandbookKhet NweBelum ada peringkat
- Listen To The Beat - Activities For English PronunciationDokumen91 halamanListen To The Beat - Activities For English PronunciationClare TreleavenBelum ada peringkat
- Daily Lesson Log DraftDokumen2 halamanDaily Lesson Log DraftLauriz Esquivel0% (1)
- TC Ques BankDokumen571 halamanTC Ques BankinvestorBelum ada peringkat
- Yazoo 1 Teaching ProgrammeDokumen147 halamanYazoo 1 Teaching Programmemiren4850% (4)
- Teaching PronunciationDokumen11 halamanTeaching PronunciationAliya FaithBelum ada peringkat
- Midterm Reviewer in Introduction To Linguistic 1Dokumen10 halamanMidterm Reviewer in Introduction To Linguistic 1Ashley MaravillaBelum ada peringkat
- Language B HL Individual Oral: Assessment CriteriaDokumen1 halamanLanguage B HL Individual Oral: Assessment CriteriaMatilda El HageBelum ada peringkat
- TEMPLATE PELAPORAN EFC FORM 2 (Latest)Dokumen8 halamanTEMPLATE PELAPORAN EFC FORM 2 (Latest)nazrin salehaBelum ada peringkat
- Linguistica IngleseDokumen45 halamanLinguistica Inglesemariapia2sicondolfiBelum ada peringkat