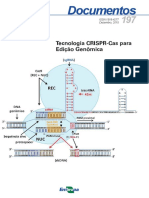
Anda mungkin juga menyukai
- Anotação de genomas fúngicos e bases de dadosDokumen4 halamanAnotação de genomas fúngicos e bases de dadosIvina BritoBelum ada peringkat
- Técnicas Moleculares Aplicadas À Microbiología de AlimentosDokumen11 halamanTécnicas Moleculares Aplicadas À Microbiología de AlimentosMacario CalvarioBelum ada peringkat
- Edição Gênica por CRISPR/Cas9: Da Teoria à PráticaDari EverandEdição Gênica por CRISPR/Cas9: Da Teoria à PráticaBelum ada peringkat
- Nomenclatura de GenesDokumen5 halamanNomenclatura de GenesHeitor AndradeBelum ada peringkat
- APS - Marcadores MolecularesDokumen11 halamanAPS - Marcadores MolecularesRafaela AdrianoBelum ada peringkat
- Marcadores Genetico Moleculares Aplicados A Programas de Conservacao e Uso de Recursos Geneticos PDFDokumen99 halamanMarcadores Genetico Moleculares Aplicados A Programas de Conservacao e Uso de Recursos Geneticos PDFlebio12Belum ada peringkat
- Desvendando A História Natural Dos Nematóides ParasitasDokumen36 halamanDesvendando A História Natural Dos Nematóides ParasitasHelena ReisBelum ada peringkat
- Marcador molecular bovinosDokumen9 halamanMarcador molecular bovinosJosé AntonioBelum ada peringkat
- Avaliação de BioinformáticaDokumen7 halamanAvaliação de BioinformáticaÍris AlvesBelum ada peringkat
- Genomica e ProteomicaDokumen42 halamanGenomica e ProteomicaBárbara Albuquerque100% (1)
- Introducao As Tecninas de PCR - Cap.3Dokumen11 halamanIntroducao As Tecninas de PCR - Cap.3Daniel CoelhoBelum ada peringkat
- Maria Eduarda Araujo Biotecnologia 19-06-2023 Estudo Dirigido Aula06 Genomica FuncionalDokumen7 halamanMaria Eduarda Araujo Biotecnologia 19-06-2023 Estudo Dirigido Aula06 Genomica FuncionalMaria EduardaBelum ada peringkat
- 2012 - Comparação de Diferentes Protocolos de Extração de Dna de Bactérias para A Utilização em RAPD-PCRDokumen10 halaman2012 - Comparação de Diferentes Protocolos de Extração de Dna de Bactérias para A Utilização em RAPD-PCRHumberto MadeiraBelum ada peringkat
- Artigo Micro Dos AlimentosDokumen11 halamanArtigo Micro Dos AlimentosMaju Bazilio CostaBelum ada peringkat
- CRISPR CasDokumen39 halamanCRISPR CasDiana Gabriela NinaBelum ada peringkat
- Sequenciamento de DNA - Desvendando o Código Da VidaDokumen12 halamanSequenciamento de DNA - Desvendando o Código Da VidaAlex Barbosa CamiloBelum ada peringkat
- Calefee Et Al. (2016)Dokumen5 halamanCalefee Et Al. (2016)Guilherme FratassiBelum ada peringkat
- PCR e RT-PCR em Tempo RealDokumen8 halamanPCR e RT-PCR em Tempo RealJorge Alberto CardosoBelum ada peringkat
- AVA 02 - Biologia Molecular - 113706Dokumen7 halamanAVA 02 - Biologia Molecular - 113706Ilsi MouraBelum ada peringkat
- Protocolo de Extração de Dna E Obtenção de Perfil Genético Visando Identificação de CultivaresDokumen9 halamanProtocolo de Extração de Dna E Obtenção de Perfil Genético Visando Identificação de CultivaresSabrina Cristina CarneiroBelum ada peringkat
- Bioinformática: Sequenciamento de DNA e suas aplicaçõesDokumen6 halamanBioinformática: Sequenciamento de DNA e suas aplicaçõesMax TrinityBelum ada peringkat
- Matemática e Estatística Na Análise de Experimentos e No MelhoramentoDokumen568 halamanMatemática e Estatística Na Análise de Experimentos e No MelhoramentoVALDINEI JUNIO BRITO VILELABelum ada peringkat
- Atividade Marcadores Moleculares - DIEGODokumen4 halamanAtividade Marcadores Moleculares - DIEGODiego IgorBelum ada peringkat
- PaperDokumen7 halamanPaperEmelinda RitaBelum ada peringkat
- FilogeografiaPDF PDFDokumen105 halamanFilogeografiaPDF PDFLuiz Gustavo ValleBelum ada peringkat
- Trabalho de Bioquímica-MicroarranjoDokumen5 halamanTrabalho de Bioquímica-Microarranjospilingueta_71394279Belum ada peringkat
- Estudo de Genes Relevantes Envolvidos No Processo Da Carcinogênese Cervical e Atuação Como Possíveis Alvos TerapêuticosDokumen4 halamanEstudo de Genes Relevantes Envolvidos No Processo Da Carcinogênese Cervical e Atuação Como Possíveis Alvos TerapêuticosGeovanna Gobbi SzaboBelum ada peringkat
- Aplicações Biológicas Da Reação em Cadeia Da PolimeraseDokumen6 halamanAplicações Biológicas Da Reação em Cadeia Da PolimeraseRayanne MendesBelum ada peringkat
- Unidade 4 - Capítulo 4.5 Genômica, Transcriptômica e ProteômicaDokumen13 halamanUnidade 4 - Capítulo 4.5 Genômica, Transcriptômica e ProteômicaLarissa ChaveirinhoBelum ada peringkat
- Desenvolvimento de protocolo de descelularização de pâncreas suíno para a produção de arcabouços naturais para enxertos de bioengenhariaDari EverandDesenvolvimento de protocolo de descelularização de pâncreas suíno para a produção de arcabouços naturais para enxertos de bioengenhariaBelum ada peringkat
- Sequenciamento Nova Geração.Dokumen10 halamanSequenciamento Nova Geração.Emerson PawoskiBelum ada peringkat
- CRISPR/Cas: edição genéticaDokumen16 halamanCRISPR/Cas: edição genéticacaco3000Belum ada peringkat
- Genômica, bioinformática e análise funcional de genesDokumen36 halamanGenômica, bioinformática e análise funcional de genesCristiano de Souza MarchesiBelum ada peringkat
- qPCR WB miRNA DNA metilação transcriptômica proteômica avaliar toxicidade EchinodorusDokumen1 halamanqPCR WB miRNA DNA metilação transcriptômica proteômica avaliar toxicidade Echinodorusamanda abreuBelum ada peringkat
- Metodos Estatisticos Otimos Na Analise de ExperimentosDokumen57 halamanMetodos Estatisticos Otimos Na Analise de ExperimentosFelipe GabrielBelum ada peringkat
- Bioinformática e o AgronegócioDokumen61 halamanBioinformática e o AgronegócioMarcus Barros BragaBelum ada peringkat
- Exercícios de Revisão 1a Avaliação de BiotecnologiaDokumen2 halamanExercícios de Revisão 1a Avaliação de BiotecnologiaKetene Werneck Saick Corti100% (1)
- Ajuste de modelos Logístico e Gompertz ao crescimento de frutos de tamareira-anãDokumen7 halamanAjuste de modelos Logístico e Gompertz ao crescimento de frutos de tamareira-anãIábita SousaBelum ada peringkat
- Ensinando Genética Molecular com DNADokumen7 halamanEnsinando Genética Molecular com DNAHeitor CalestiniBelum ada peringkat
- PCR gene amplificaçãoDokumen3 halamanPCR gene amplificaçãoAlbino VelasquezBelum ada peringkat
- Analise de Expressao GenicaDokumen39 halamanAnalise de Expressao GenicaNivaldo TavaresBelum ada peringkat
- Desvendando o HemogramaDokumen2 halamanDesvendando o HemogramaThiago Ribeiro da SilvaBelum ada peringkat
- RNA-Seq: Uma abordagem para analisar o perfil de transcriptomaDokumen28 halamanRNA-Seq: Uma abordagem para analisar o perfil de transcriptomaPaola Frantchieli Teleken AvrellaBelum ada peringkat
- 1357 Full en PTDokumen16 halaman1357 Full en PTAdrian AlvarezBelum ada peringkat
- Microarranjos de DNADokumen26 halamanMicroarranjos de DNALaura Eliza OliveiraBelum ada peringkat
- Exercício 2 - Bioinformatica - pdf1Dokumen9 halamanExercício 2 - Bioinformatica - pdf1Renaly AraujoBelum ada peringkat
- Questão de Aula 4 - Biotecnologia: Nome: N.° Turma: Data: ProfessorDokumen3 halamanQuestão de Aula 4 - Biotecnologia: Nome: N.° Turma: Data: ProfessorAl. Madalena TorcatoBelum ada peringkat
- CRISPR/Cas9 na Drosophila melanogasterDokumen33 halamanCRISPR/Cas9 na Drosophila melanogasterLuiz FelipeBelum ada peringkat
- Genética forense: técnicas para identificação criminalDokumen11 halamanGenética forense: técnicas para identificação criminalAdriana LúcioBelum ada peringkat
- EXTRAÇÃODokumen3 halamanEXTRAÇÃOcarameloBelum ada peringkat
- Monografia Completa Josiane Stocco Pos Biotecnologia Fac IguacuDokumen41 halamanMonografia Completa Josiane Stocco Pos Biotecnologia Fac IguacujosianevendasonlineBelum ada peringkat
- Teste de Biologia OutubroDokumen9 halamanTeste de Biologia OutubroRafael saraivaBelum ada peringkat
- Prova de Biologia - Sistema Respiratório e ImunológicoDokumen3 halamanProva de Biologia - Sistema Respiratório e ImunológicoAlexandra SilvaBelum ada peringkat
- 2007 Faleiro Marcadores Moleculares LIVRODokumen99 halaman2007 Faleiro Marcadores Moleculares LIVROGrasiela Santana100% (1)
- Código Genético e Síntese de ProteínasDokumen5 halamanCódigo Genético e Síntese de ProteínasLuciano BelcavelloBelum ada peringkat
- Detecção de Molicutes de Milho Por Testes SerológicosDokumen5 halamanDetecção de Molicutes de Milho Por Testes SerológicosPedro SpadaBelum ada peringkat
- Manual Metodos de TipagemDokumen27 halamanManual Metodos de TipagemDionei Joaquim HaasBelum ada peringkat
- Aula 7Dokumen5 halamanAula 7mateus silvaBelum ada peringkat
- Modelo de comunicação digital para importação de proteínas mitocondriaisDokumen165 halamanModelo de comunicação digital para importação de proteínas mitocondriaisCelina D Ávila SamoginBelum ada peringkat
- Práticas de Química Farmacêutica Medicinal: Uma Abordagem ComputacionalDari EverandPráticas de Química Farmacêutica Medicinal: Uma Abordagem ComputacionalBelum ada peringkat
- A Modelagem Matemática No Ensino de MatrizesDokumen9 halamanA Modelagem Matemática No Ensino de MatrizesMaria Ozelia Silva MendesBelum ada peringkat
- Efeito DopplerDokumen16 halamanEfeito DopplerJanaina FernandesBelum ada peringkat
- Probabilidade e Processos Estocásticos2Dokumen49 halamanProbabilidade e Processos Estocásticos2Janaina FernandesBelum ada peringkat
- Matrizes Algebra Linear I Aula 01 559 MatrizesDokumen20 halamanMatrizes Algebra Linear I Aula 01 559 MatrizeshmvungeBelum ada peringkat
- Rresolvidos BpnormalDokumen18 halamanRresolvidos BpnormalRogério Lopes Da Costa100% (1)
- Probabilidade e intervalos de confiançaDokumen2 halamanProbabilidade e intervalos de confiançaJanaina FernandesBelum ada peringkat
- Explorando o Winplot - Funções de 1o e 2o grauDokumen71 halamanExplorando o Winplot - Funções de 1o e 2o grauPaulo Canedo da SilvaBelum ada peringkat
- Aula 7 - Aproximacao Da Binomial Pela Normal (Somente Leitura)Dokumen21 halamanAula 7 - Aproximacao Da Binomial Pela Normal (Somente Leitura)Janaina FernandesBelum ada peringkat
- Distribuições de Probabilidade NormaisDokumen36 halamanDistribuições de Probabilidade NormaisNelson MirandaBelum ada peringkat
- SEMINÁRIO FÍSICA LLLDokumen18 halamanSEMINÁRIO FÍSICA LLLJanaina FernandesBelum ada peringkat
- Exercicios Teste de Hipotese Desvio Padrao ConhecidoDokumen1 halamanExercicios Teste de Hipotese Desvio Padrao ConhecidoJanaina FernandesBelum ada peringkat
- Polar EsDokumen9 halamanPolar EsAndré Minoru Takasu da SilvaBelum ada peringkat
- Exercicio 2013 1 DepDokumen2 halamanExercicio 2013 1 DepJanaina FernandesBelum ada peringkat
- Distribuição de Poisson (Ok)Dokumen15 halamanDistribuição de Poisson (Ok)Janaina FernandesBelum ada peringkat
- Exercicio Revisao 2013 Teste de HipoteseDokumen1 halamanExercicio Revisao 2013 Teste de HipoteseJanaina FernandesBelum ada peringkat
- Exercicio Calculo 1 20132Dokumen2 halamanExercicio Calculo 1 20132Janaina FernandesBelum ada peringkat
- Distribuicaotdestudent PDFDokumen10 halamanDistribuicaotdestudent PDFJanaina FernandesBelum ada peringkat
- Metodo de Euler BBDokumen3 halamanMetodo de Euler BBJanaina FernandesBelum ada peringkat
- Apostila EstatisticaDokumen100 halamanApostila EstatisticaJanaina FernandesBelum ada peringkat
- Re SumoDokumen5 halamanRe SumoJanaina FernandesBelum ada peringkat
- (LIVRO) - Calculo Numérico Com Aplicações - 2 Edição - Leonidas BarrosoDokumen189 halaman(LIVRO) - Calculo Numérico Com Aplicações - 2 Edição - Leonidas BarrosoMayra SouzaBelum ada peringkat
- Costa, RicharddeSouza MPDokumen102 halamanCosta, RicharddeSouza MPJanaina FernandesBelum ada peringkat
- NBR 5382 - Verificação de Iluminação de Interiores PDFDokumen4 halamanNBR 5382 - Verificação de Iluminação de Interiores PDFMateus DauricioBelum ada peringkat
- Calibração FWDDokumen21 halamanCalibração FWDWilfredo TejerinaBelum ada peringkat
- Quimica - Propriedades Dos Líquidos e SólidosDokumen3 halamanQuimica - Propriedades Dos Líquidos e SólidosQuímica Qui0% (2)
- Perfis H de abas paralelasDokumen9 halamanPerfis H de abas paralelasedson alfaBelum ada peringkat
- Aula 15 Ciclo de Roscamento - TorneamentoDokumen6 halamanAula 15 Ciclo de Roscamento - TorneamentoJunior GuedesBelum ada peringkat
- O valor histórico e pessoal das cartasDokumen23 halamanO valor histórico e pessoal das cartaslincolnanderson tinocovenancioBelum ada peringkat
- Aula1 - Introdução e Ponto FlutuanteDokumen32 halamanAula1 - Introdução e Ponto FlutuanteLuana NobreBelum ada peringkat
- 5 - Modelamento GibbsCAMDokumen5 halaman5 - Modelamento GibbsCAMjulio457Belum ada peringkat
- MRP SAP Estudo conceitosDokumen18 halamanMRP SAP Estudo conceitosTuaregue_BRBelum ada peringkat
- Balança Magna L-PCR Magna ManualDokumen8 halamanBalança Magna L-PCR Magna ManualJuvenal MatiasBelum ada peringkat
- Leis de Newton exercíciosDokumen11 halamanLeis de Newton exercíciosIsabelle LopesBelum ada peringkat
- Avaliação Trimestral - Matemática - 4.º AnoDokumen7 halamanAvaliação Trimestral - Matemática - 4.º AnoCarla PereiraBelum ada peringkat
- FRP Análise Numérica e ExperimentalDokumen9 halamanFRP Análise Numérica e ExperimentalJose Eduardo GranatoBelum ada peringkat
- Treino Matemático 8o anoDokumen4 halamanTreino Matemático 8o anoAna Carla de OliveiraBelum ada peringkat
- Fundamentos de Cartografia para Profissionais de Geomãtica PDFDokumen59 halamanFundamentos de Cartografia para Profissionais de Geomãtica PDFAreli Nogueira100% (1)
- Espelho ParabólicoDokumen10 halamanEspelho ParabólicoArmando Célio LealBelum ada peringkat
- Atividades de GramáticaDokumen33 halamanAtividades de GramáticaDebora RibeiroBelum ada peringkat
- Lista de Exercícios PODokumen196 halamanLista de Exercícios POSamuel WolfBelum ada peringkat
- Interpretação do Método de RorschachDokumen35 halamanInterpretação do Método de RorschachVictória PoiaresBelum ada peringkat
- Tabela comparativa entre as técnicas de multiplexação FDM e TDMDokumen129 halamanTabela comparativa entre as técnicas de multiplexação FDM e TDMwelltonarruda100% (2)
- Trabalho de EstaleiroDokumen10 halamanTrabalho de EstaleiroMarijó NeuriceBelum ada peringkat
- Temas poderosos e reflexões sobre nome e destinoDokumen45 halamanTemas poderosos e reflexões sobre nome e destinoFérnanda Moura100% (4)
- Campo magnético produzido por corrente elétricaDokumen28 halamanCampo magnético produzido por corrente elétrica451072jaBelum ada peringkat
- Planilha Calculo BDI REVISADADokumen4 halamanPlanilha Calculo BDI REVISADALeandro RibeiroBelum ada peringkat
- Regras Descartes método verdadeDokumen6 halamanRegras Descartes método verdadeCelso Wzorek100% (2)
- Catalogo Material Didactico e Educativo 2013-2014Dokumen294 halamanCatalogo Material Didactico e Educativo 2013-2014Odete LoureiroBelum ada peringkat
- CapacitoresDokumen2 halamanCapacitoresMateus CostaBelum ada peringkat
- AvaliaÇÃo Da ExposiÇÃo Ocupacional Ao CalorDokumen2 halamanAvaliaÇÃo Da ExposiÇÃo Ocupacional Ao Calorapi-3704990Belum ada peringkat
- Fisica Livro2 Parte1 Capitulo1Dokumen16 halamanFisica Livro2 Parte1 Capitulo1pedrohps10Belum ada peringkat
- Mini-Ficha de Trabalho - Probabilidades e AxiomáticaDokumen3 halamanMini-Ficha de Trabalho - Probabilidades e AxiomáticaJoana AlvesBelum ada peringkat