Anda mungkin juga menyukai
- El Arcaico Somos Traído Corre Buscando MuchedumbreDokumen12 halamanEl Arcaico Somos Traído Corre Buscando MuchedumbreRockerGrungerBelum ada peringkat
- Malasiente Mies Piramo RozaganteDokumen5 halamanMalasiente Mies Piramo RozaganteRockerGrungerBelum ada peringkat
- vesicanteVenialDelAnacoluto PDFDokumen7 halamanvesicanteVenialDelAnacoluto PDFRockerGrungerBelum ada peringkat
- alanazoLudibrioMalbarataInefableInfiernillo PDFDokumen10 halamanalanazoLudibrioMalbarataInefableInfiernillo PDFRockerGrungerBelum ada peringkat
- CompiladorC PDFDokumen1 halamanCompiladorC PDFRockerGrungerBelum ada peringkat
- Malasiente Mies Piramo RozaganteDokumen5 halamanMalasiente Mies Piramo RozaganteRockerGrungerBelum ada peringkat
- senectudRefocilaElTraqudoTrebejo PDFDokumen8 halamansenectudRefocilaElTraqudoTrebejo PDFRockerGrungerBelum ada peringkat
- AnaquelAparaLaosLegamo PDFDokumen8 halamanAnaquelAparaLaosLegamo PDFRockerGrungerBelum ada peringkat
- vesicanteVenialDelAnacoluto PDFDokumen7 halamanvesicanteVenialDelAnacoluto PDFRockerGrungerBelum ada peringkat
- AndabeAstanioBenadiraAgolatoFenSarturmena PDFDokumen7 halamanAndabeAstanioBenadiraAgolatoFenSarturmena PDFRockerGrungerBelum ada peringkat
- EntradaSalidaC PDFDokumen2 halamanEntradaSalidaC PDFRockerGrungerBelum ada peringkat
- MacroAssert PDFDokumen1 halamanMacroAssert PDFRockerGrungerBelum ada peringkat
- BiosintesisDeProteinas PDFDokumen42 halamanBiosintesisDeProteinas PDFRockerGrungerBelum ada peringkat
- Fortran VersionesDokumen1 halamanFortran VersionesRockerGrungerBelum ada peringkat
- JerarquiaOperadores PDFDokumen1 halamanJerarquiaOperadores PDFRockerGrungerBelum ada peringkat
- Matlab 1Dokumen52 halamanMatlab 1William MosqueraBelum ada peringkat
- OperadorCast PDFDokumen1 halamanOperadorCast PDFRockerGrungerBelum ada peringkat
- Fortran VariablesDokumen1 halamanFortran VariablesRockerGrungerBelum ada peringkat
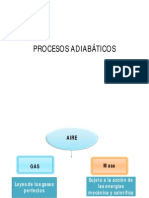
- ProcesosAdiabaticos PDFDokumen30 halamanProcesosAdiabaticos PDFRockerGrungerBelum ada peringkat
- FortranLenguaje PDFDokumen1 halamanFortranLenguaje PDFRockerGrungerBelum ada peringkat
- Transformada FourierDokumen81 halamanTransformada FourierFrancisco FloresBelum ada peringkat
- For Trant Ipos Deda To SDokumen1 halamanFor Trant Ipos Deda To SRockerGrungerBelum ada peringkat
- Fracciones Parciales PDFDokumen5 halamanFracciones Parciales PDFLuis SegoviaBelum ada peringkat
- Matlab 1Dokumen52 halamanMatlab 1William MosqueraBelum ada peringkat
- Escala LogaritmicaDokumen3 halamanEscala Logaritmicasata6_5Belum ada peringkat
- Escala LogaritmicaDokumen3 halamanEscala Logaritmicasata6_5Belum ada peringkat
- Matlab 1Dokumen52 halamanMatlab 1William MosqueraBelum ada peringkat
- Matlab 1Dokumen52 halamanMatlab 1William MosqueraBelum ada peringkat
- El Conocimiento y El Actor de ConocimientoDokumen20 halamanEl Conocimiento y El Actor de ConocimientoDiego RomeroBelum ada peringkat
- 6 Teorías Contemporáneas de La TraducciónDokumen3 halaman6 Teorías Contemporáneas de La TraducciónalexandraBelum ada peringkat
- Escuelas de Pensamiento en MarketingDokumen16 halamanEscuelas de Pensamiento en MarketingStefany Trujillo20% (5)
- El Idealismo IiiDokumen10 halamanEl Idealismo IiiAndrea Vidarte VegaBelum ada peringkat
- SESION DE APRENDIZAJE Inicios de La RepublicaDokumen3 halamanSESION DE APRENDIZAJE Inicios de La RepublicaEdwyn TA100% (4)
- Sesión de Aprendizaje 05Dokumen3 halamanSesión de Aprendizaje 05CésarBelum ada peringkat
- Aguas Con Las Adicciones Folleto PDFDokumen27 halamanAguas Con Las Adicciones Folleto PDFDavid MolinaBelum ada peringkat
- Ernst CassirerDokumen27 halamanErnst CassirerFrancis AlarcónBelum ada peringkat
- Estructura de Proyecto para Sesiones Aprendizaje PDFDokumen5 halamanEstructura de Proyecto para Sesiones Aprendizaje PDFDavid Garriazo NuñezBelum ada peringkat
- Traabajo de InvestigacionDokumen53 halamanTraabajo de InvestigacionLeonardo Tony Goicochea DavalosBelum ada peringkat
- ACTITUD DOCENTE FRENTE A LA DISLEXIA (Velásquez Sánchez, Áles Gustavo)Dokumen4 halamanACTITUD DOCENTE FRENTE A LA DISLEXIA (Velásquez Sánchez, Áles Gustavo)Alex Gustavo Velasquez SanchezBelum ada peringkat
- Recomendaciones para estudiantes en crisisDokumen3 halamanRecomendaciones para estudiantes en crisisJimmy AnticonaBelum ada peringkat
- Yanina-Godoy-tarea Semana S5 Psicopedagogia de La Niñez y AdolescenciaDokumen7 halamanYanina-Godoy-tarea Semana S5 Psicopedagogia de La Niñez y Adolescenciayanina godoy100% (1)
- El Discurso y Sus ComponentesDokumen5 halamanEl Discurso y Sus ComponentesPamela Torres ElguetaBelum ada peringkat
- Diseño GraficoDokumen8 halamanDiseño GraficoHANNIA MELO GONZALEZBelum ada peringkat
- Inteligencia Emocional Puntos Extras 3Dokumen5 halamanInteligencia Emocional Puntos Extras 3kevin marin100% (4)
- Métodos de Investigación PsicológicaDokumen8 halamanMétodos de Investigación PsicológicaCesar100% (2)
- Sesion 6 Inteligencia MultiplesDokumen17 halamanSesion 6 Inteligencia MultiplesDiegoBelum ada peringkat
- Teorías y VariablesDokumen6 halamanTeorías y Variablessamar2008Belum ada peringkat
- Análisis DAFODokumen2 halamanAnálisis DAFOAntonio OrtizBelum ada peringkat
- Importancia de La PsicopedagogíaDokumen3 halamanImportancia de La PsicopedagogíaCarmen Barron100% (2)
- Documento 4Dokumen18 halamanDocumento 4elizabeth mazo pereBelum ada peringkat
- Ensayo de Orientación EducativaDokumen2 halamanEnsayo de Orientación EducativaMartinjonathan86% (21)
- La Verdad Como Concepto MasonicoDokumen9 halamanLa Verdad Como Concepto Masonicobubonia100% (3)
- Educación A Distancia (Sangra)Dokumen8 halamanEducación A Distancia (Sangra)pmunozc1Belum ada peringkat
- EstrésDokumen10 halamanEstrésSavka Rondanelli ArayaBelum ada peringkat
- DicotomiainvcualicuanteDokumen11 halamanDicotomiainvcualicuanteIsabella EspejoBelum ada peringkat
- Modelo de Sesion de Aprendizaje 2023Dokumen6 halamanModelo de Sesion de Aprendizaje 2023Leydy P.A.Belum ada peringkat
- NOVENO Continuidad de La Vida - Variacion y HerenciaDokumen174 halamanNOVENO Continuidad de La Vida - Variacion y HerenciacesarivanolivasBelum ada peringkat
- Instructivo PPEDokumen56 halamanInstructivo PPEVielka JulissaBelum ada peringkat