Anda mungkin juga menyukai
- 1Q 2017 Adult Bible Study Guide 6Dokumen177 halaman1Q 2017 Adult Bible Study Guide 6Emmanuel MasaboBelum ada peringkat
- HCI&MobilityDokumen51 halamanHCI&MobilityEmmanuel MasaboBelum ada peringkat
- WEKA A Practical Machine Learning ToolDokumen18 halamanWEKA A Practical Machine Learning ToolEmmanuel MasaboBelum ada peringkat
- SimulationDokumen18 halamanSimulationEmmanuel MasaboBelum ada peringkat
- Malware Detection Techniques Using Artificial Immune SystemDokumen14 halamanMalware Detection Techniques Using Artificial Immune SystemEmmanuel MasaboBelum ada peringkat
- x86 1Dokumen102 halamanx86 1Chaitanya VaddadiBelum ada peringkat
- WEKA Explorer TutorialDokumen45 halamanWEKA Explorer TutorialMichel De Almeida SilvaBelum ada peringkat
- x86 1Dokumen102 halamanx86 1Chaitanya VaddadiBelum ada peringkat
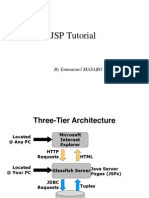
- JSP Tutorial: by Emmanuel MASABODokumen4 halamanJSP Tutorial: by Emmanuel MASABOEmmanuel MasaboBelum ada peringkat
- JSP CRUD TutorialDokumen32 halamanJSP CRUD TutorialEmmanuel MasaboBelum ada peringkat
- Java ProjectsDokumen38 halamanJava Projectsarvind6199Belum ada peringkat
- PHP Training: Introduction To PHP & MysqlDokumen2 halamanPHP Training: Introduction To PHP & MysqlEmmanuel MasaboBelum ada peringkat
- DFDs for Joe's Yard SystemDokumen28 halamanDFDs for Joe's Yard SystemEmmanuel MasaboBelum ada peringkat
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Mind and self in Victorian literatureDokumen6 halamanMind and self in Victorian literatureOI LU YI (TJC)Belum ada peringkat
- List of cable nomenclature and ratingsDokumen4 halamanList of cable nomenclature and ratingssmcsamindaBelum ada peringkat
- A Day Without Conflicts Proiect EnglezaDokumen5 halamanA Day Without Conflicts Proiect Englezaproiecte de liceulBelum ada peringkat
- Boeing 767 CaseSummaryDokumen5 halamanBoeing 767 CaseSummaryRunit Marda100% (2)
- Temperature Sensor Instruction ManualDokumen41 halamanTemperature Sensor Instruction ManualFARHANUDDIN100% (1)
- Heat Exchanger Selection Webinar PDFDokumen47 halamanHeat Exchanger Selection Webinar PDFAzar DeenBelum ada peringkat
- Climbing Mount EverestDokumen2 halamanClimbing Mount EverestAndRos Chin Yong KeatBelum ada peringkat
- Cutting The Fat Tail of Climate Risk: Carbon Backstop Technologies As A Climate Insurance PolicyDokumen56 halamanCutting The Fat Tail of Climate Risk: Carbon Backstop Technologies As A Climate Insurance PolicyHoover InstitutionBelum ada peringkat
- Emergency Hotlines - Official Gazette of The Republic of The PhilippinesDokumen8 halamanEmergency Hotlines - Official Gazette of The Republic of The PhilippinesBibimbop LewrenceBelum ada peringkat
- M03 Formula B1 PracticeExam 1 AUDDokumen3 halamanM03 Formula B1 PracticeExam 1 AUDNESTOR GONZALO CORTES LUCEROBelum ada peringkat
- Bison Epoxy 5 MinDokumen1 halamanBison Epoxy 5 MinRadu ConstantinBelum ada peringkat
- R 41031022015Dokumen8 halamanR 41031022015GokulSubramanianBelum ada peringkat
- Global Warming Consensus Among ScientistsDokumen121 halamanGlobal Warming Consensus Among ScientistsAtraSicariusBelum ada peringkat
- WSET Level 2 中级葡萄酒品尝教材Dokumen83 halamanWSET Level 2 中级葡萄酒品尝教材凱日本Belum ada peringkat
- Lecture 3. Refrigeration Cycles 2Dokumen37 halamanLecture 3. Refrigeration Cycles 2addisudagneBelum ada peringkat
- Climograph LessonDokumen13 halamanClimograph LessonCheryl LimBelum ada peringkat
- Nett WarriorDokumen2 halamanNett WarriorGcmarshall82Belum ada peringkat
- Fort Peck Reservoir Dodges A Bullet: Mr. WhiskersDokumen8 halamanFort Peck Reservoir Dodges A Bullet: Mr. WhiskersBS Central, Inc. "The Buzz"Belum ada peringkat
- PEST Analysis Test ACCADokumen5 halamanPEST Analysis Test ACCAAshwin Jain0% (1)
- Geodesic Structure: Abellana, Carlo Curyaga, Arlyn Sialongo, HanniveDokumen20 halamanGeodesic Structure: Abellana, Carlo Curyaga, Arlyn Sialongo, Hannivedan pendonBelum ada peringkat
- NASA Technical Paper 2256Dokumen145 halamanNASA Technical Paper 2256Anonymous QFTSj1YBelum ada peringkat
- 1 1 The AtmoshereDokumen7 halaman1 1 The Atmoshereapi-240094705Belum ada peringkat
- GLITTERING LYRICSDokumen31 halamanGLITTERING LYRICSNurul Chiko-pyon IzraBelum ada peringkat
- Weather Lesson Plan for 5th Form BeginnersDokumen3 halamanWeather Lesson Plan for 5th Form BeginnersFlavia NitaBelum ada peringkat
- Lab 5 Heat ExchangerDokumen13 halamanLab 5 Heat ExchangerNur Syuhaidah100% (1)
- For Information For Review For Approval For Construction As-BuiltDokumen20 halamanFor Information For Review For Approval For Construction As-BuiltUtku Can KılıçBelum ada peringkat
- Heterosis and Combining Ability Studies inDokumen78 halamanHeterosis and Combining Ability Studies inSundar JoeBelum ada peringkat
- Indeso Full CatalogueDokumen19 halamanIndeso Full Catalogueindrawan_suparanBelum ada peringkat
- T G 1658734218 Ks1 Brazil Information Powerpoint Ver 2Dokumen16 halamanT G 1658734218 Ks1 Brazil Information Powerpoint Ver 2İrem YıldırımBelum ada peringkat
- Fuentes AlfaDokumen4 halamanFuentes AlfaCarlos Arturo HoyosBelum ada peringkat