Anda mungkin juga menyukai
- Numerical Investigation of Self-Healing Concrete Using ABAQUSDokumen13 halamanNumerical Investigation of Self-Healing Concrete Using ABAQUSSujan NeupaneBelum ada peringkat
- Emmett Katherine G 200508 MaDokumen57 halamanEmmett Katherine G 200508 MaFr Jesmond Micallef100% (1)
- The Miracle Belly Button: Gate to the body - gate to healingDari EverandThe Miracle Belly Button: Gate to the body - gate to healingBelum ada peringkat
- Building A Floating Hydroponic Garden PDFDokumen4 halamanBuilding A Floating Hydroponic Garden PDFPhiter Van KondoleleBelum ada peringkat
- The World of Little Spook As Channelled by Deidre AmohangaDokumen59 halamanThe World of Little Spook As Channelled by Deidre AmohangaTheresa Aperehama100% (1)
- Compost ManualDokumen21 halamanCompost ManualssskguBelum ada peringkat
- High-Altitude NutritionDokumen11 halamanHigh-Altitude NutritionGlowstarBelum ada peringkat
- Animal Whisperer PDFDokumen4 halamanAnimal Whisperer PDFKevinPriestmanBelum ada peringkat
- Encountering Thoughts: A Footprint in The SandDokumen47 halamanEncountering Thoughts: A Footprint in The SandRobert the Mole Smith100% (1)
- Illuminati Card GameDokumen5 halamanIlluminati Card GameJavi AbadBelum ada peringkat
- Home Remedies For Dogs With MangeDokumen6 halamanHome Remedies For Dogs With MangeRic AlbanBelum ada peringkat
- Natural Remedy for Your Snoring Problem: How to Quit Snoring and Enjoy a Sound Sleep Every NightDari EverandNatural Remedy for Your Snoring Problem: How to Quit Snoring and Enjoy a Sound Sleep Every NightBelum ada peringkat
- Deworming of PetsDokumen5 halamanDeworming of PetsRehan Ashraf BandeshaBelum ada peringkat
- Living Among Bigfoot: Volumes 6-10 (Living Among Bigfoot: Collector's Edition Book 2): Living Among Bigfoot: Collector's Edition, #2Dari EverandLiving Among Bigfoot: Volumes 6-10 (Living Among Bigfoot: Collector's Edition Book 2): Living Among Bigfoot: Collector's Edition, #2Belum ada peringkat
- The Matrix and PlatoDokumen2 halamanThe Matrix and PlatojohnBelum ada peringkat
- Acupressure Newly Adopted DogsDokumen1 halamanAcupressure Newly Adopted DogsIoana SavaBelum ada peringkat
- Health Care 13 "Ebola Virus": Dr. Titus BantilesDokumen22 halamanHealth Care 13 "Ebola Virus": Dr. Titus Bantilesvanessa0% (1)
- Great Story NevertoldDokumen998 halamanGreat Story Nevertoldmrbig7002Belum ada peringkat
- Project Star Gate: $20 Million in 'Psychic' ResearchDokumen0 halamanProject Star Gate: $20 Million in 'Psychic' ResearchMark Kern100% (1)
- A Memory Returned: Healing in Its Deepest FormDari EverandA Memory Returned: Healing in Its Deepest FormPenilaian: 5 dari 5 bintang5/5 (1)
- Spirituality and Total Health-IsBNDokumen31 halamanSpirituality and Total Health-IsBNrealiserBelum ada peringkat
- WWW Wikihow Com Develop Telepathy PDFDokumen14 halamanWWW Wikihow Com Develop Telepathy PDFPraveen YampallaBelum ada peringkat
- Supplies Needed: - Keep Liquid Essiac Refrigerated at All TimesDokumen2 halamanSupplies Needed: - Keep Liquid Essiac Refrigerated at All TimesM.I.S.Belum ada peringkat
- Growing Temperate Tree Fruit and Nut Crops in The HomeDokumen37 halamanGrowing Temperate Tree Fruit and Nut Crops in The Homehassan_maatoukBelum ada peringkat
- Kindney Stones - Coke and AsparagusDokumen1 halamanKindney Stones - Coke and AsparagusGeoff CostelloBelum ada peringkat
- Law of KarmaDokumen3 halamanLaw of Karmassnishand100% (1)
- UntitledDokumen397 halamanUntitledPeter LuxruelBelum ada peringkat
- Starting Anew - A Guide for Daily RenewalDokumen348 halamanStarting Anew - A Guide for Daily RenewalultragaffBelum ada peringkat
- Universal LawsDokumen2 halamanUniversal LawsKristina Hanson100% (4)
- Amazing Psychic World of AnimalsDokumen3 halamanAmazing Psychic World of AnimalsSharon Crago100% (1)
- Those That Make It and Those That Make It Big (The 4 Laws)Dokumen13 halamanThose That Make It and Those That Make It Big (The 4 Laws)Onyemenam ChinodebemBelum ada peringkat
- Passive Rainwater Harvesting GuideDokumen32 halamanPassive Rainwater Harvesting GuideAlbuquerque JournalBelum ada peringkat
- DonDokumen3 halamanDonBecky BBelum ada peringkat
- Animal Telepathy To Communicate With AnimalsDokumen15 halamanAnimal Telepathy To Communicate With Animalsaditya.kumarBelum ada peringkat
- ATLANTIS - Gordon Michael Scallion - Channeler2 PDFDokumen3 halamanATLANTIS - Gordon Michael Scallion - Channeler2 PDFNikša100% (1)
- The Power Pyramid - A GovStuff Foundation Special ReportDokumen11 halamanThe Power Pyramid - A GovStuff Foundation Special ReportMichaelM.PastoreBelum ada peringkat
- Gray Squirrel: Joyce Reedy Glenda Combs 2007Dokumen20 halamanGray Squirrel: Joyce Reedy Glenda Combs 2007Nitin KumarBelum ada peringkat
- Emp InfoDokumen90 halamanEmp InfoArc AngleBelum ada peringkat
- 4g Subliminal Program InstructionsDokumen4 halaman4g Subliminal Program InstructionsStar GazerBelum ada peringkat
- Squirrel ManualDokumen20 halamanSquirrel ManualAlka KulkarniBelum ada peringkat
- Recommended Vitamin k2 Intake PDFDokumen13 halamanRecommended Vitamin k2 Intake PDFRocco LamponeBelum ada peringkat
- Not Impossible!: How Our Universe May Exist Inside of a ComputerDari EverandNot Impossible!: How Our Universe May Exist Inside of a ComputerBelum ada peringkat
- I'Ve Got A Secret: The Law of Attraction Is A LIE: Join Our Email List For Weekly UpdatesDokumen1 halamanI'Ve Got A Secret: The Law of Attraction Is A LIE: Join Our Email List For Weekly UpdatesLieurd Shepherd0% (1)
- Vedantic Philosophy's Matrix for Contemporary ManagementDokumen9 halamanVedantic Philosophy's Matrix for Contemporary ManagementLors PorseenaBelum ada peringkat
- Introduction To Bethel Living MineralsDokumen7 halamanIntroduction To Bethel Living Mineralsapi-484602061100% (1)
- Improving Our Brain Power - An Interview With Gary NullDokumen4 halamanImproving Our Brain Power - An Interview With Gary Nullmika2k01Belum ada peringkat
- Tips and Tricks For Foraging and EnrichmentDokumen6 halamanTips and Tricks For Foraging and EnrichmentOmary2jBelum ada peringkat
- Pets Can Communicate Newsletter/March 2013Dokumen5 halamanPets Can Communicate Newsletter/March 2013Brenda SeldinBelum ada peringkat
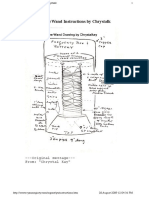
- Powerwand Instructions by Chrystalk: - Original Message - From: "Chrystal Kay"Dokumen4 halamanPowerwand Instructions by Chrystalk: - Original Message - From: "Chrystal Kay"lighteagles131100% (1)
- Breeding Basics: Preparing, Mating, Pregnancy & WhelpingDokumen5 halamanBreeding Basics: Preparing, Mating, Pregnancy & WhelpingChelsea ValdezBelum ada peringkat
- Techniques for Listening to Inner SoundsDokumen3 halamanTechniques for Listening to Inner Soundss207100% (1)
- Mатурски Рад Из Енглеског Језика Hip-HopDokumen19 halamanMатурски Рад Из Енглеског Језика Hip-HopDragoljub ĐurkovićBelum ada peringkat
- Caesar CipherDokumen21 halamanCaesar CipherMustafa KhairallahBelum ada peringkat
- Relaxation Based Methods ("Floating Out") : Ballabene's Astral PagesDokumen10 halamanRelaxation Based Methods ("Floating Out") : Ballabene's Astral Pagesindie4wildBelum ada peringkat
- 72-Reptilian Forces Withdraw From The White HouseDokumen3 halaman72-Reptilian Forces Withdraw From The White HouseJamesComeyJustaBitchBelum ada peringkat
- TRUTH SEEKER Imagination and The Decentraisation of PowerDokumen16 halamanTRUTH SEEKER Imagination and The Decentraisation of PowerKahn EllmersBelum ada peringkat
- How politicians extort our freedomDokumen2 halamanHow politicians extort our freedomJosh SnyderBelum ada peringkat
- CVCITC Smoke-Free Workplace Policy & ProgramDokumen2 halamanCVCITC Smoke-Free Workplace Policy & ProgramKristine Joy CabujatBelum ada peringkat
- Course Code: Hrm353 L1Dokumen26 halamanCourse Code: Hrm353 L1Jaskiran KaurBelum ada peringkat
- ReadingDokumen6 halamanReadingakhyar sanchiaBelum ada peringkat
- Ecma L1221BR3 PD02 05172016Dokumen2 halamanEcma L1221BR3 PD02 05172016Anil JindalBelum ada peringkat
- The NicotinaDokumen8 halamanThe Nicotinab0beiiiBelum ada peringkat
- Investigation Report on Engine Room Fire on Ferry BerlinDokumen63 halamanInvestigation Report on Engine Room Fire on Ferry Berlin卓文翔Belum ada peringkat
- Inventory of Vacant Units in Elan Miracle Sector-84 GurgaonDokumen2 halamanInventory of Vacant Units in Elan Miracle Sector-84 GurgaonBharat SadanaBelum ada peringkat
- 8510C - 15, - 50, - 100 Piezoresistive Pressure Transducer: Features DescriptionDokumen3 halaman8510C - 15, - 50, - 100 Piezoresistive Pressure Transducer: Features Descriptionedward3600Belum ada peringkat
- Chapter 9 Screw ConveyorsDokumen7 halamanChapter 9 Screw ConveyorsMarew Getie100% (1)
- Product Data Sheet: Eas Configurator: Easy Online Configuration Ekv1+1 120 Vg4Gxhq (Vg4Gxhq)Dokumen1 halamanProduct Data Sheet: Eas Configurator: Easy Online Configuration Ekv1+1 120 Vg4Gxhq (Vg4Gxhq)Attila HorvathBelum ada peringkat
- Iso 16399-2014-05Dokumen52 halamanIso 16399-2014-05nadim100% (1)
- Chapter 20: Sleep Garzon Maaks: Burns' Pediatric Primary Care, 7th EditionDokumen4 halamanChapter 20: Sleep Garzon Maaks: Burns' Pediatric Primary Care, 7th EditionHelen UgochukwuBelum ada peringkat
- Smartrac - Iolineug - r5Dokumen66 halamanSmartrac - Iolineug - r5Darwin Elvis Giron HurtadoBelum ada peringkat
- Regional Office X: Republic of The PhilippinesDokumen2 halamanRegional Office X: Republic of The PhilippinesCoreine Imee ValledorBelum ada peringkat
- UM Routing L3P 15 01 UsDokumen102 halamanUM Routing L3P 15 01 UsmiroBelum ada peringkat
- TheSun 2008-11-04 Page16 Asian Stocks Rally Continues On Policy HopesDokumen1 halamanTheSun 2008-11-04 Page16 Asian Stocks Rally Continues On Policy HopesImpulsive collectorBelum ada peringkat
- Baella-Silva v. Hulsey, 454 F.3d 5, 1st Cir. (2006)Dokumen9 halamanBaella-Silva v. Hulsey, 454 F.3d 5, 1st Cir. (2006)Scribd Government DocsBelum ada peringkat
- BA50BCODokumen6 halamanBA50BCOpedroarlindo-1Belum ada peringkat
- 45 - Altivar 61 Plus Variable Speed DrivesDokumen130 halaman45 - Altivar 61 Plus Variable Speed Drivesabdul aziz alfiBelum ada peringkat
- Hics 203-Organization Assignment ListDokumen2 halamanHics 203-Organization Assignment ListslusafBelum ada peringkat
- MRI Week3 - Signal - Processing - TheoryDokumen43 halamanMRI Week3 - Signal - Processing - TheoryaboladeBelum ada peringkat
- Organic Evolution (Evolutionary Biology) Revised Updated Ed by Veer Bala RastogiDokumen1.212 halamanOrganic Evolution (Evolutionary Biology) Revised Updated Ed by Veer Bala RastogiTATHAGATA OJHA83% (6)
- M Audio bx10s Manuel Utilisateur en 27417Dokumen8 halamanM Audio bx10s Manuel Utilisateur en 27417TokioBelum ada peringkat
- First Aid Emergency Action PrinciplesDokumen7 halamanFirst Aid Emergency Action PrinciplesJosellLim67% (3)
- Coca Cola Live-ProjectDokumen20 halamanCoca Cola Live-ProjectKanchan SharmaBelum ada peringkat
- Simple Present 60991Dokumen17 halamanSimple Present 60991Ketua EE 2021 AndrianoBelum ada peringkat
- FRP/HDPE septic tank specificationDokumen2 halamanFRP/HDPE septic tank specificationpeakfortuneBelum ada peringkat
- Coriolis - Atlas CompendiumDokumen62 halamanCoriolis - Atlas CompendiumSquamata100% (2)
- AE3212 I 2 Static Stab 1 AcDokumen23 halamanAE3212 I 2 Static Stab 1 AcRadj90Belum ada peringkat
- Lab 1 Boys CalorimeterDokumen11 halamanLab 1 Boys CalorimeterHafizszul Feyzul100% (1)