Anda mungkin juga menyukai
- Statistics ProjectDokumen13 halamanStatistics ProjectFred KruegerBelum ada peringkat
- False - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of PopulationDokumen5 halamanFalse - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of Populationpiepie2Belum ada peringkat
- 123 T F Z Chi Test 2Dokumen5 halaman123 T F Z Chi Test 2izzyguyBelum ada peringkat
- In Hypothesis TestingDokumen20 halamanIn Hypothesis TestingDhara TandonBelum ada peringkat
- Testing Two Independent Samples - With Minitab Procedures)Dokumen67 halamanTesting Two Independent Samples - With Minitab Procedures)Hey its meBelum ada peringkat
- Chapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Dokumen91 halamanChapter No. 08 Fundamental Sampling Distributions and Data Descriptions - 02 (Presentation)Sahib Ullah MukhlisBelum ada peringkat
- Making Inferences about Population VariancesDokumen19 halamanMaking Inferences about Population VariancesEhsan KarimBelum ada peringkat
- Test Formula Assumption Notes Source Procedures That Utilize Data From A Single SampleDokumen12 halamanTest Formula Assumption Notes Source Procedures That Utilize Data From A Single SamplesitifothmanBelum ada peringkat
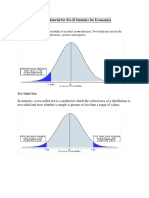
- Study Material For BA-II Statistics For Economics: One Tailed TestDokumen9 halamanStudy Material For BA-II Statistics For Economics: One Tailed TestC.s TanyaBelum ada peringkat
- Notes 515 Fall 10 Chap 6Dokumen12 halamanNotes 515 Fall 10 Chap 6Sultana RajaBelum ada peringkat
- Rank Biserial Correlation Coefficient rbDokumen3 halamanRank Biserial Correlation Coefficient rbryanosleep100% (1)
- DATA SCIENCE INTERVIEW PREPARATIONDokumen27 halamanDATA SCIENCE INTERVIEW PREPARATIONSatyavaraprasad BallaBelum ada peringkat
- Hypothesis Testing Statistical InferencesDokumen10 halamanHypothesis Testing Statistical InferencesReaderBelum ada peringkat
- SM 38Dokumen58 halamanSM 38ayushBelum ada peringkat
- Unit 3 HypothesisDokumen41 halamanUnit 3 Hypothesisabhinavkapoor101Belum ada peringkat
- Basic Concepts in Hypothesis Testing (Rosalind L P Phang)Dokumen7 halamanBasic Concepts in Hypothesis Testing (Rosalind L P Phang)SARA MORALES GALVEZBelum ada peringkat
- Chapter 8 and 9Dokumen7 halamanChapter 8 and 9Ellii YouTube channelBelum ada peringkat
- Understanding the t-Test in 38 CharactersDokumen5 halamanUnderstanding the t-Test in 38 CharactersMeenalochini kannanBelum ada peringkat
- Hypothesis Testing for MeansDokumen20 halamanHypothesis Testing for MeansSAIRITHISH SBelum ada peringkat
- AnovaDokumen55 halamanAnovaFiona Fernandes67% (3)
- Stats BDokumen75 halamanStats BmihsovyaBelum ada peringkat
- Hypothesis TestDokumen19 halamanHypothesis TestmalindaBelum ada peringkat
- Module 2 in IStat 1 Probability DistributionDokumen6 halamanModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeBelum ada peringkat
- Independent Samples T TestDokumen19 halamanIndependent Samples T TestKimesha BrownBelum ada peringkat
- Samenvatting Statistiek 10tm17Dokumen11 halamanSamenvatting Statistiek 10tm17ISBelum ada peringkat
- Spss Tutorials: Independent Samples T TestDokumen13 halamanSpss Tutorials: Independent Samples T TestMat3xBelum ada peringkat
- Univariate Statistics: Statistical Inference: Testing HypothesisDokumen28 halamanUnivariate Statistics: Statistical Inference: Testing HypothesisEyasu DestaBelum ada peringkat
- T testsAsVarianceRatioTestsDokumen6 halamanT testsAsVarianceRatioTestssangeethasBelum ada peringkat
- MATH7340 Module 7 NotesDokumen39 halamanMATH7340 Module 7 NotesdhsjhfdkjBelum ada peringkat
- Introduction To The T-Statistic: PSY295 Spring 2003 SummerfeltDokumen19 halamanIntroduction To The T-Statistic: PSY295 Spring 2003 SummerfeltEddy MwachenjeBelum ada peringkat
- Point and Interval Estimation-26!08!2011Dokumen28 halamanPoint and Interval Estimation-26!08!2011Syed OvaisBelum ada peringkat
- Gurruh Dwi Septano Tugas Rangkuman BAB 2Dokumen16 halamanGurruh Dwi Septano Tugas Rangkuman BAB 2gurruh dwi septanoBelum ada peringkat
- Assumptions and Properties of Z and T DistributionDokumen4 halamanAssumptions and Properties of Z and T DistributionAdnan AkramBelum ada peringkat
- Normal Distribution: X e X FDokumen30 halamanNormal Distribution: X e X FNilesh DhakeBelum ada peringkat
- L7 Hypothesis TestingDokumen59 halamanL7 Hypothesis Testingمصطفى سامي شهيد لفتهBelum ada peringkat
- CHAPTER 11 Chi Square and Other Non Parametric TestsDokumen77 halamanCHAPTER 11 Chi Square and Other Non Parametric TestsAyushi JangpangiBelum ada peringkat
- StatisticsDokumen49 halamanStatisticshazalulger5Belum ada peringkat
- Forms of Test StatisticDokumen31 halamanForms of Test StatisticJackielou TrongcosoBelum ada peringkat
- Test of Hypothesis - T and Z Tests. Chi-Square Test. F Test.Dokumen15 halamanTest of Hypothesis - T and Z Tests. Chi-Square Test. F Test.Barath RajBelum ada peringkat
- Test of HypothesisDokumen85 halamanTest of HypothesisJyoti Prasad Sahu64% (11)
- Unit+16 T TestDokumen35 halamanUnit+16 T Testmathurakshay99Belum ada peringkat
- MODULE 3 Normal Probabaility Curve and Hypothesis TestingDokumen7 halamanMODULE 3 Normal Probabaility Curve and Hypothesis TestingShijiThomasBelum ada peringkat
- Statistics For College Students-Part 2Dokumen43 halamanStatistics For College Students-Part 2Yeyen Patino100% (1)
- STAT1301 Notes: Steps For Scientific StudyDokumen31 halamanSTAT1301 Notes: Steps For Scientific StudyjohnBelum ada peringkat
- Simple Random SamplingDokumen10 halamanSimple Random SamplingNafees A. SiddiqueBelum ada peringkat
- Testing of HypothesisDokumen37 halamanTesting of HypothesisSiddharth Bahri67% (3)
- Readings For Lecture 5,: S S N N S NDokumen16 halamanReadings For Lecture 5,: S S N N S NSara BayedBelum ada peringkat
- Data Types and DistributionsDokumen1 halamanData Types and Distributionssk112988Belum ada peringkat
- Independent Samples T Test (LECTURE)Dokumen10 halamanIndependent Samples T Test (LECTURE)Max SantosBelum ada peringkat
- Biostat W9Dokumen18 halamanBiostat W9Erica Veluz LuyunBelum ada peringkat
- Instalinotes - PREVMED IIDokumen24 halamanInstalinotes - PREVMED IIKenneth Cuballes100% (1)
- The Central Limit Theorem and Hypothesis Testing FinalDokumen29 halamanThe Central Limit Theorem and Hypothesis Testing FinalMichelleneChenTadle100% (1)
- Allama Iqbal Open University Islamabad: Muhammad AshrafDokumen25 halamanAllama Iqbal Open University Islamabad: Muhammad AshrafHafiz M MudassirBelum ada peringkat
- Chapter 12 T - Test, F TestDokumen38 halamanChapter 12 T - Test, F TestHum92reBelum ada peringkat
- Student's T TestDokumen56 halamanStudent's T TestmelprvnBelum ada peringkat
- Non-Parametric Methods - 1 PDFDokumen3 halamanNon-Parametric Methods - 1 PDFRajkamal79Belum ada peringkat
- Statistical Analysis Data Treatment and EvaluationDokumen55 halamanStatistical Analysis Data Treatment and EvaluationJyl CodeñieraBelum ada peringkat
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignDari EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignBelum ada peringkat
- Learn Statistics Fast: A Simplified Detailed Version for StudentsDari EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsBelum ada peringkat
- SubjectGuideMGMT30018 2015 JulyDokumen23 halamanSubjectGuideMGMT30018 2015 JulydeltathebestBelum ada peringkat
- Internet Marketing Subject Guide 2015 v1.2-1Dokumen15 halamanInternet Marketing Subject Guide 2015 v1.2-1deltathebestBelum ada peringkat
- Internet Marketing Subject Guide 2015 v1.2-1Dokumen15 halamanInternet Marketing Subject Guide 2015 v1.2-1deltathebestBelum ada peringkat
- Highpoint Movie Times Dragon 2: SATURDAY 5th JulyDokumen1 halamanHighpoint Movie Times Dragon 2: SATURDAY 5th JulydeltathebestBelum ada peringkat
- Cairnlea Newsletter Term 3 13 2 PDFDokumen4 halamanCairnlea Newsletter Term 3 13 2 PDFdeltathebestBelum ada peringkat
- US DeclineDokumen4 halamanUS DeclinedeltathebestBelum ada peringkat
- Paint1 TiffDokumen1 halamanPaint1 TiffdeltathebestBelum ada peringkat
- Rebel Sport: Rebels Sport - Weekend Sale!Dokumen1 halamanRebel Sport: Rebels Sport - Weekend Sale!deltathebestBelum ada peringkat
- Growth Rate of Output Per Worker Equal To GaDokumen1 halamanGrowth Rate of Output Per Worker Equal To GadeltathebestBelum ada peringkat
- The Cheesecake Shop Welcome VoucherDokumen1 halamanThe Cheesecake Shop Welcome VoucherdeltathebestBelum ada peringkat
- PTSP Jntua Old Question PapersDokumen32 halamanPTSP Jntua Old Question PapersrajuBelum ada peringkat
- MADokumen18 halamanMATit NguyenBelum ada peringkat
- Chapter 6-Continuous Probability Distributions: Multiple ChoiceDokumen30 halamanChapter 6-Continuous Probability Distributions: Multiple ChoiceMon Carla LagonBelum ada peringkat
- STATISTICS ProblemsDokumen5 halamanSTATISTICS ProblemsA100% (1)
- Probit and Logit-MadeshDokumen22 halamanProbit and Logit-MadeshfffhghBelum ada peringkat
- Module 4 PDFDokumen33 halamanModule 4 PDFdeerajBelum ada peringkat
- Probability Powerpoint LessonDokumen28 halamanProbability Powerpoint LessonNoemi RosarioBelum ada peringkat
- Solomon Press S1GDokumen4 halamanSolomon Press S1GnmanBelum ada peringkat
- Sampling DistributionDokumen32 halamanSampling Distributionayushi jhaBelum ada peringkat
- Chapter No. 15 ProbabilityDokumen57 halamanChapter No. 15 ProbabilityTanmay SanchetiBelum ada peringkat
- 7.2 and 7.3 QuizDokumen2 halaman7.2 and 7.3 Quizoceanolive2Belum ada peringkat
- Identifying a binomial experimentDokumen2 halamanIdentifying a binomial experimentEstefania FigueroaBelum ada peringkat
- PATTERN RECOGNITION Final NotesDokumen40 halamanPATTERN RECOGNITION Final Notesssa83% (6)
- Lab 5 - Elementary Statistics With R - Matlab - Numerical MeasuresDokumen8 halamanLab 5 - Elementary Statistics With R - Matlab - Numerical MeasuresSam Caunca OrtizBelum ada peringkat
- Revision 1 (28 Ogos)Dokumen2 halamanRevision 1 (28 Ogos)SRI SIVABALASUNDRAM A/L KRISHNAN -Belum ada peringkat
- Unit 4. Probability DistributionsDokumen18 halamanUnit 4. Probability DistributionszinfadelsBelum ada peringkat
- Multiple Choice Ch11 & 12 Stats Confidence Intervals Chi-Squared TestsDokumen3 halamanMultiple Choice Ch11 & 12 Stats Confidence Intervals Chi-Squared TestsalishaBelum ada peringkat
- Markov Chains Unit 1 Conditional ProbabilityDokumen85 halamanMarkov Chains Unit 1 Conditional ProbabilityRavi Shankar VermaBelum ada peringkat
- Module 6 - Central Limit TheoremDokumen6 halamanModule 6 - Central Limit TheoremGerovic ParinasBelum ada peringkat
- ASSIGNMENT 2 SIM 3251 (DUE DATE: 22/5/2020) Chapter 3, 4 & 5Dokumen3 halamanASSIGNMENT 2 SIM 3251 (DUE DATE: 22/5/2020) Chapter 3, 4 & 5syah howBelum ada peringkat
- Geographically Weighted Regression - BayesianDokumen34 halamanGeographically Weighted Regression - BayesianKarla DanielaBelum ada peringkat
- STAM Formula SheetDokumen4 halamanSTAM Formula Sheetkosaunderground100% (2)
- Random VariableDokumen18 halamanRandom Variabledev1712Belum ada peringkat
- Lindley Distribution and Its Application: M.E. Ghitany, B. Atieh, S. NadarajahDokumen14 halamanLindley Distribution and Its Application: M.E. Ghitany, B. Atieh, S. NadarajahricellygamaBelum ada peringkat
- Econometric Theory Lecture NotesDokumen90 halamanEconometric Theory Lecture NotesKun ZhouBelum ada peringkat
- Single Maths B Probability & Statistics: Exercises & SolutionsDokumen18 halamanSingle Maths B Probability & Statistics: Exercises & SolutionsKeith Bernard Gazo MartiBelum ada peringkat
- Problems 2Dokumen8 halamanProblems 2Qi Ming Chen100% (2)
- Aitken 1934Dokumen5 halamanAitken 1934MariaUrtubiBelum ada peringkat
- Random Variables & Probability DistributionsDokumen2 halamanRandom Variables & Probability DistributionsRazman BijanBelum ada peringkat
- Euler-Maruyama Method: Numerical SimulationDokumen3 halamanEuler-Maruyama Method: Numerical SimulationJese MadridBelum ada peringkat