Anda mungkin juga menyukai
- Exposición UpesDokumen17 halamanExposición UpeselpeludasBelum ada peringkat
- BiologIaIRosaGamboa PDFDokumen2 halamanBiologIaIRosaGamboa PDFAbel VillardBelum ada peringkat
- Constancia JoanaDokumen1 halamanConstancia JoanaAbel VillardBelum ada peringkat
- Literatur ADokumen7 halamanLiteratur AAbel VillardBelum ada peringkat
- Alondra LgaDokumen3 halamanAlondra LgaAbel VillardBelum ada peringkat
- Alondra LiteraturaDokumen3 halamanAlondra LiteraturaAbel VillardBelum ada peringkat
- BiologIaIRosaGamboa PDFDokumen2 halamanBiologIaIRosaGamboa PDFAbel VillardBelum ada peringkat
- Actividad 2 U 4Dokumen2 halamanActividad 2 U 4Abel VillardBelum ada peringkat
- U2. EstimacionDokumen45 halamanU2. EstimacionZamanta TorresBelum ada peringkat
- Mest1 - U2 - A2 - AbvvDokumen2 halamanMest1 - U2 - A2 - AbvvAbel VillardBelum ada peringkat
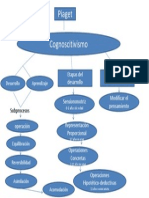
- Piaget Cognoscitivismo: Etapas Del Desarrollo Sensioromotriz ConocimientoDokumen1 halamanPiaget Cognoscitivismo: Etapas Del Desarrollo Sensioromotriz ConocimientoAbel VillardBelum ada peringkat
- Cuadro 1 y 2Dokumen4 halamanCuadro 1 y 2Abel VillardBelum ada peringkat
- Michelle Map ADokumen1 halamanMichelle Map AAbel VillardBelum ada peringkat
- InglesDokumen2 halamanIngleselpeludasBelum ada peringkat
- Map A Maria IsabelDokumen1 halamanMap A Maria IsabelAbel VillardBelum ada peringkat
- Ali U2 Eu AbvvDokumen4 halamanAli U2 Eu Abvvisabel_aramburo1872Belum ada peringkat
- HCM U3 A3 AbvvDokumen7 halamanHCM U3 A3 AbvvAbel VillardBelum ada peringkat
- Atr U1 AbvvDokumen1 halamanAtr U1 AbvvAbel VillardBelum ada peringkat
- Del 17 Al 21 de Enero Del 2012Dokumen7 halamanDel 17 Al 21 de Enero Del 2012Abel VillardBelum ada peringkat
- TatuajessDokumen2 halamanTatuajessAbel VillardBelum ada peringkat
- Atr U1 AbvvDokumen1 halamanAtr U1 AbvvAbel VillardBelum ada peringkat
- Actividades para Lectura EneroDokumen15 halamanActividades para Lectura EneroAbel VillardBelum ada peringkat
- Manual de MacrosDokumen25 halamanManual de MacrosEduardo SaenzBelum ada peringkat
- Guia N°1 - Ejercicios Con Arrays Unidimensionales en JavaDokumen3 halamanGuia N°1 - Ejercicios Con Arrays Unidimensionales en JavaNorman ArauzBelum ada peringkat
- Curso MS Project 2010Dokumen143 halamanCurso MS Project 2010JuanCarlos Musayon83% (6)
- Tutorial Isatis PDFDokumen54 halamanTutorial Isatis PDFFernando Beroiza100% (2)
- Informe Instrucción SwitchDokumen4 halamanInforme Instrucción SwitchMiguel RomeroBelum ada peringkat
- Instrucciones DMLDokumen9 halamanInstrucciones DMLrubenpcaBelum ada peringkat
- RUP-DS-029 Instructivo de Programación y Reprogramación de La EjecuciónDokumen36 halamanRUP-DS-029 Instructivo de Programación y Reprogramación de La Ejecucióncesarm moranmBelum ada peringkat
- Elaboración de Interfaces de Usuario: Intérprete de Órdenes Interfaz Iconos Menús Elemento ApuntadorDokumen37 halamanElaboración de Interfaces de Usuario: Intérprete de Órdenes Interfaz Iconos Menús Elemento ApuntadorMatias CubasBelum ada peringkat
- Pay BackDokumen14 halamanPay BackEnrique Corcino BarrialBelum ada peringkat
- Patrones ArquitecturaDokumen23 halamanPatrones ArquitecturaDiego Alejandro Muñoz ToroBelum ada peringkat
- Plantilla Plan Unidad LlenaDokumen4 halamanPlantilla Plan Unidad Llenaapi-253440230Belum ada peringkat
- Planificacion de Proyecto de SoftwareDokumen30 halamanPlanificacion de Proyecto de SoftwareEly CondoriBelum ada peringkat
- Estudio Del Uso de La Librería Arcgis JS para El Análisis de Datos Georeferenciados en Mapas de Tipo GISDokumen5 halamanEstudio Del Uso de La Librería Arcgis JS para El Análisis de Datos Georeferenciados en Mapas de Tipo GISCarlos Geovanny Escobar PortilloBelum ada peringkat
- Anexo 02 Informe Tecnico Aplicacion Diseno de Algoritmos 220501096 AA2Dokumen5 halamanAnexo 02 Informe Tecnico Aplicacion Diseno de Algoritmos 220501096 AA2brayan estevez100% (1)
- Ejemplo de Pilas y Programa en CDokumen4 halamanEjemplo de Pilas y Programa en CYop YopBelum ada peringkat
- Avance Programatico 3o SecDokumen4 halamanAvance Programatico 3o SecAlex Ram HipoBelum ada peringkat
- Sesión 13: Aplicación de Estructuras Dinámicas Con Objetos: ArraylistDokumen12 halamanSesión 13: Aplicación de Estructuras Dinámicas Con Objetos: ArraylistThiago Enrique Sánchez AbadBelum ada peringkat
- Orientación A Objetos - Compressed PDFDokumen232 halamanOrientación A Objetos - Compressed PDFBernardo Sánchez OrdóñezBelum ada peringkat
- Código de Operación PDFDokumen2 halamanCódigo de Operación PDFGerardo DávilaBelum ada peringkat
- Optimized Title for SQL Query and Functions Guide Less Than 40 CharactersDokumen16 halamanOptimized Title for SQL Query and Functions Guide Less Than 40 CharactersCarlos ReyesBelum ada peringkat
- Tarea No. 2 Métodos NuméricosDokumen60 halamanTarea No. 2 Métodos NuméricosDavid López0% (1)
- Arboles BinariosDokumen1 halamanArboles BinariosPriscila CodringtonBelum ada peringkat
- Unidad 3 Programación BásicaDokumen25 halamanUnidad 3 Programación BásicaFranciscvs TezcatlipocaBelum ada peringkat
- Descuento y factura IVADokumen8 halamanDescuento y factura IVAkatia martinezBelum ada peringkat
- Yucra 2018Dokumen2 halamanYucra 2018DAVID VLADIMIR ARRATEA PILLCOBelum ada peringkat
- Mapa MentalDokumen5 halamanMapa Mentaljerson arias83% (6)
- 1 - Resumen Manejo de Ficheros Java-2Dokumen8 halaman1 - Resumen Manejo de Ficheros Java-2jesusgomBelum ada peringkat
- Método de Rigidez NO SistematizadoDokumen11 halamanMétodo de Rigidez NO SistematizadoGonzalo GarciaBelum ada peringkat
- Almacen PDFDokumen30 halamanAlmacen PDFEsteban Joaquin Jordan CarbajalBelum ada peringkat
- P UT1 IntroduccionDokumen40 halamanP UT1 IntroduccionAngélica Fernández RozaBelum ada peringkat