Anda mungkin juga menyukai
- DSP Cores vs. ChipsDokumen189 halamanDSP Cores vs. ChipsARAVINDBelum ada peringkat
- DR Tahir Zaidi: Targets For AlgorithmsDokumen37 halamanDR Tahir Zaidi: Targets For AlgorithmsBilal AwanBelum ada peringkat
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Dari EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Belum ada peringkat
- Unit 5 DSP SystemDokumen30 halamanUnit 5 DSP SystemSiddhasen Patil100% (2)
- Embedded System Design-PresentationDokumen120 halamanEmbedded System Design-PresentationAdarsh Prakash100% (1)
- Evolution of DSP ProcessorsDokumen23 halamanEvolution of DSP ProcessorsMuhamed ShereefBelum ada peringkat
- Design and Implementation of Signal Processing Systems: An IntroductionDokumen58 halamanDesign and Implementation of Signal Processing Systems: An Introductiongrbavithra0% (1)
- 633888485056270520Dokumen115 halaman633888485056270520rafeshBelum ada peringkat
- Classification of Embedded Systems Three Types of Embedded Systems AreDokumen24 halamanClassification of Embedded Systems Three Types of Embedded Systems Arekartika_krazeBelum ada peringkat
- Bga900c80p30x30 2500X2500X355 Ti Fcbga CMS S-Pbga-N900 PDFDokumen298 halamanBga900c80p30x30 2500X2500X355 Ti Fcbga CMS S-Pbga-N900 PDFMohan K SBelum ada peringkat
- Experiements (Using DSP Kit) Introduction To DSP Processors: MicroprocessorDokumen9 halamanExperiements (Using DSP Kit) Introduction To DSP Processors: Microprocessorshiksha singhBelum ada peringkat
- DSP LabmanualDokumen82 halamanDSP LabmanualHemanth SharmaBelum ada peringkat
- Qualcomm Hexagon ArchitectureDokumen23 halamanQualcomm Hexagon ArchitectureRahul SharmaBelum ada peringkat
- Digital Signal ProcessorDokumen3 halamanDigital Signal ProcessorSanjeev TarigopulaBelum ada peringkat
- Digital Signal Processors Application ArchitectureDokumen61 halamanDigital Signal Processors Application ArchitectureanjugaduBelum ada peringkat
- DSP ArchitectureDokumen90 halamanDSP Architectureharish akellaBelum ada peringkat
- DSP TMS Series Processor and MOTOR ControlDokumen28 halamanDSP TMS Series Processor and MOTOR Controlavi013Belum ada peringkat
- DSP Unit-5 FinalDokumen97 halamanDSP Unit-5 FinalreventhhuntBelum ada peringkat
- 08.508 DSP Lab Manual Part-ADokumen64 halaman08.508 DSP Lab Manual Part-AAssini HussainBelum ada peringkat
- Core of The Embedded SystemDokumen107 halamanCore of The Embedded SystemSanskrithi TigerBelum ada peringkat
- AC 1997paper109 PDFDokumen8 halamanAC 1997paper109 PDFFranklin Cardeñoso FernándezBelum ada peringkat
- DSP ProcessorsDokumen24 halamanDSP ProcessorsHerald Rufus100% (1)
- ARM CortexDokumen20 halamanARM CortexivanmeyerBelum ada peringkat
- Unit6dspprocessor 140207205522 Phpapp02Dokumen34 halamanUnit6dspprocessor 140207205522 Phpapp02Arun Kumar SBelum ada peringkat
- Eecs 318 Cad Computer Aided DesignDokumen36 halamanEecs 318 Cad Computer Aided Designshilpaa11Belum ada peringkat
- Unit 6 ECE131 - Part 4 - K1Dokumen66 halamanUnit 6 ECE131 - Part 4 - K1abhi shekBelum ada peringkat
- DSPDokumen77 halamanDSPVikas YadavBelum ada peringkat
- DSP Based Electrical Lab: Gokaraju Rangaraju Institute of Engineering & Technology (Autonomous)Dokumen77 halamanDSP Based Electrical Lab: Gokaraju Rangaraju Institute of Engineering & Technology (Autonomous)P Praveen KumarBelum ada peringkat
- Digital Signal Processing Unit V: DSP ProcessorDokumen20 halamanDigital Signal Processing Unit V: DSP ProcessorKumar ManiBelum ada peringkat
- DSP CasestudyDokumen23 halamanDSP CasestudyShayani BatabyalBelum ada peringkat
- 5.1. Unit V - DSP ProcessorDokumen83 halaman5.1. Unit V - DSP ProcessorJayaram ThamizhmaniBelum ada peringkat
- Unit 1 - ARM7, ARM9, ARM11 ProcessorsDokumen88 halamanUnit 1 - ARM7, ARM9, ARM11 ProcessorsKunal Khandelwal50% (2)
- Tms 320 DM 6467Dokumen355 halamanTms 320 DM 6467sjpritchardBelum ada peringkat
- EECC722 - ShaabanDokumen101 halamanEECC722 - ShaabanAditya JagtapBelum ada peringkat
- Microprocessors Unit-1 - 3Dokumen5 halamanMicroprocessors Unit-1 - 3Yoyo MaitrayBelum ada peringkat
- DSP Lab 21-09-2021Dokumen78 halamanDSP Lab 21-09-2021POORNIMA PBelum ada peringkat
- DSP Lecture 01Dokumen39 halamanDSP Lecture 01sitaram_1100% (1)
- TMS320F281x Digital Signal Processors: 1 Device OverviewDokumen167 halamanTMS320F281x Digital Signal Processors: 1 Device OverviewYoelBelum ada peringkat
- 1.8051 MicrocontrollerDokumen34 halaman1.8051 MicrocontrollervanithaBelum ada peringkat
- Digital Signal Processors: Inderdeep Kaur Aulakh Asst. Prof. (IT), UIET Pu, CHDDokumen19 halamanDigital Signal Processors: Inderdeep Kaur Aulakh Asst. Prof. (IT), UIET Pu, CHDAseem SharmaBelum ada peringkat
- Es Unit1Dokumen83 halamanEs Unit1venneti kiranBelum ada peringkat
- Embedded System Design (BEE-446) : General-Purpose Processors (Software)Dokumen12 halamanEmbedded System Design (BEE-446) : General-Purpose Processors (Software)Humna KhanBelum ada peringkat
- Tms 320 F 28379 DDokumen215 halamanTms 320 F 28379 DadnantanBelum ada peringkat
- Example de Datasheet Complet D'un SoC - TI DM814x - sprs647cDokumen375 halamanExample de Datasheet Complet D'un SoC - TI DM814x - sprs647cJean-Philippe УдеBelum ada peringkat
- Ece699 Lecture1Dokumen106 halamanEce699 Lecture1Maninder SinghBelum ada peringkat
- Fundamentals of Microcomputers: Seng4122 - Microprocessor and Assembly LanguageDokumen16 halamanFundamentals of Microcomputers: Seng4122 - Microprocessor and Assembly LanguageFeyisa BekeleBelum ada peringkat
- 6713 User ManualDokumen92 halaman6713 User Manualsningle100% (1)
- Cancellation Chip Solution: High Density Packet EchoDokumen9 halamanCancellation Chip Solution: High Density Packet EchoGigi IonBelum ada peringkat
- Embedded and Real-Time Operating Systems: Course Code: 70439Dokumen76 halamanEmbedded and Real-Time Operating Systems: Course Code: 70439SrikanthBelum ada peringkat
- Arm ShowDokumen38 halamanArm Showselva33Belum ada peringkat
- 19 Bee 039Dokumen62 halaman19 Bee 03919BEE039 Satyam guptaBelum ada peringkat
- C1. D S P: Igital Ignal RocessorsDokumen39 halamanC1. D S P: Igital Ignal Rocessorseugen lupuBelum ada peringkat
- MicroprocessorsDokumen25 halamanMicroprocessorsKarneshwar SannamaniBelum ada peringkat
- AVR MicrocontrollerDokumen56 halamanAVR MicrocontrollerK S Ravi Kumar (MVGR EEE)Belum ada peringkat
- Tms320F2833X, Tms320F2823X Digital Signal Controllers (DSCS)Dokumen203 halamanTms320F2833X, Tms320F2823X Digital Signal Controllers (DSCS)PrashanthManikumarBelum ada peringkat
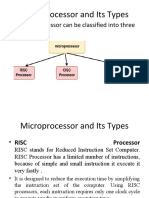
- Microprocessor and Its TypesDokumen16 halamanMicroprocessor and Its TypesAisha SarinBelum ada peringkat
- TMS320DM365ZCE30Dokumen210 halamanTMS320DM365ZCE30rodeoaBelum ada peringkat
- Advanced Processors: Overview of DSP Unit-5 Unit-6Dokumen58 halamanAdvanced Processors: Overview of DSP Unit-5 Unit-6isha rajBelum ada peringkat
- Memory Map inDokumen22 halamanMemory Map inkrajasekarantutiBelum ada peringkat
- Integrating Wireless ECG Monitoring in Textiles: Johan Coosemans, Bart Hermans, Robert PuersDokumen6 halamanIntegrating Wireless ECG Monitoring in Textiles: Johan Coosemans, Bart Hermans, Robert PuerskrajasekarantutiBelum ada peringkat
- Capacitive SensingDokumen9 halamanCapacitive SensingkrajasekarantutiBelum ada peringkat
- Automotive Interview QuestionsDokumen61 halamanAutomotive Interview Questionskrajasekarantuti50% (2)
- Ubiquitous Healthcare Service Using Zigbee and Mobile Phone For Elderly PatientsDokumen6 halamanUbiquitous Healthcare Service Using Zigbee and Mobile Phone For Elderly PatientskrajasekarantutiBelum ada peringkat
- Integrating Wireless ECG Monitoring in Textiles: Johan Coosemans, Bart Hermans, Robert PuersDokumen6 halamanIntegrating Wireless ECG Monitoring in Textiles: Johan Coosemans, Bart Hermans, Robert PuerskrajasekarantutiBelum ada peringkat
- 1 SensorsDokumen18 halaman1 SensorsTimothy LeonardBelum ada peringkat
- Self-Powered, Ambient Light SensorDokumen6 halamanSelf-Powered, Ambient Light SensorkrajasekarantutiBelum ada peringkat
- 4Dokumen27 halaman4binukirubaBelum ada peringkat
- Separation of Maternal and Fetal ECG Signals From The Mixed Source Signal Using FASTICADokumen8 halamanSeparation of Maternal and Fetal ECG Signals From The Mixed Source Signal Using FASTICAkrajasekarantutiBelum ada peringkat
- Feature Measurements of ECG Beats Based On Statistical ClassifiersDokumen9 halamanFeature Measurements of ECG Beats Based On Statistical ClassifierskrajasekarantutiBelum ada peringkat
- Real-Time ECG Telemonitoring System Design With Mobile Phone PlatformDokumen8 halamanReal-Time ECG Telemonitoring System Design With Mobile Phone PlatformkrajasekarantutiBelum ada peringkat
- Nav Inertial Navigation BWDokumen53 halamanNav Inertial Navigation BWmeamsheanBelum ada peringkat
- Biomedical Sensing TechnologiesDokumen16 halamanBiomedical Sensing TechnologieskrajasekarantutiBelum ada peringkat
- Crandall Hhr3 3Dokumen8 halamanCrandall Hhr3 3krajasekarantutiBelum ada peringkat
- Heart BettermentDokumen8 halamanHeart BettermentkrajasekarantutiBelum ada peringkat
- Analysis of Finite Wordlength EffectsDokumen11 halamanAnalysis of Finite Wordlength EffectskrajasekarantutiBelum ada peringkat
- Ch10 MfilesDokumen6 halamanCh10 MfileskrajasekarantutiBelum ada peringkat
- Digital Signal Prossessing I Part01Dokumen6 halamanDigital Signal Prossessing I Part01krajasekarantutiBelum ada peringkat
- Analysis of Finite Wordlength EffectsDokumen11 halamanAnalysis of Finite Wordlength EffectskrajasekarantutiBelum ada peringkat
- Introduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremsDokumen42 halamanIntroduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremskrajasekarantutiBelum ada peringkat
- Quickstart Eval Kit IARDokumen14 halamanQuickstart Eval Kit IARfubuki293Belum ada peringkat
- Embedded System For Short-Term Weather ForecastingDokumen6 halamanEmbedded System For Short-Term Weather ForecastingPrakash DattBelum ada peringkat
- Introduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremsDokumen42 halamanIntroduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremskrajasekarantutiBelum ada peringkat
- RealAnalog Circuits1 Chapter3Dokumen36 halamanRealAnalog Circuits1 Chapter3krajasekarantutiBelum ada peringkat
- Datasheet 1Dokumen72 halamanDatasheet 1krajasekarantutiBelum ada peringkat
- Introduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremsDokumen42 halamanIntroduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremskrajasekarantutiBelum ada peringkat
- Introduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremsDokumen42 halamanIntroduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 4: Systems and Network TheoremskrajasekarantutiBelum ada peringkat
- Introduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 2: Circuit ReductionDokumen27 halamanIntroduction and Chapter Objectives: Real Analog - Circuits 1 Chapter 2: Circuit ReductionkrajasekarantutiBelum ada peringkat
- RealAnalog Circuits1 Chapter1Dokumen35 halamanRealAnalog Circuits1 Chapter1krajasekarantutiBelum ada peringkat
- Configuration Recommendations For Hardening of Windows 10 Using Built-In FunctionalitiesDokumen33 halamanConfiguration Recommendations For Hardening of Windows 10 Using Built-In Functionalities02AhmadIzah KhafidunKamalBelum ada peringkat
- KNR 1063 Digital Electronics: RegisterDokumen28 halamanKNR 1063 Digital Electronics: RegisterCyprian Mikael CorgedoBelum ada peringkat
- F 31719784Dokumen4 halamanF 31719784Nick LuftBelum ada peringkat
- OceanStor 2000 V3 Series Storage Systems V300R006C20 Upgrade Guide 06Dokumen295 halamanOceanStor 2000 V3 Series Storage Systems V300R006C20 Upgrade Guide 06Pelon SinpeloBelum ada peringkat
- Quiz On Computer Awareness For Bank ExamsDokumen18 halamanQuiz On Computer Awareness For Bank ExamsSatya SharonBelum ada peringkat
- Killer ErrorDokumen2 halamanKiller ErrorLei BieneBelum ada peringkat
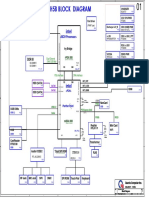
- Quanta FH5B REV 1A - FUJITSU SIEMENS Lifebook AH512Dokumen34 halamanQuanta FH5B REV 1A - FUJITSU SIEMENS Lifebook AH512n nn100% (1)
- Loquendo Text To Speech 7.5Dokumen3 halamanLoquendo Text To Speech 7.5Jessica C0% (1)
- 10th Physics Chapter 17 - 2 PDFDokumen1 halaman10th Physics Chapter 17 - 2 PDFAsad SaleemBelum ada peringkat
- How To Use C++ EnvironmentDokumen12 halamanHow To Use C++ EnvironmentRoyce GodenBelum ada peringkat
- (润州)ZX5102WT DataSheetDokumen3 halaman(润州)ZX5102WT DataSheetjorgeBelum ada peringkat
- Uvm MethodologyDokumen2 halamanUvm MethodologyFeroz AhmedBelum ada peringkat
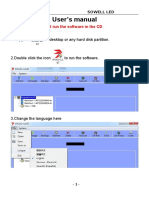
- Manual Cartel Programable Led VideomaxDokumen3 halamanManual Cartel Programable Led VideomaxCharly Saavedra0% (1)
- Starting The System: Keysight I3070 Series 5 In-Circuit Test SystemDokumen5 halamanStarting The System: Keysight I3070 Series 5 In-Circuit Test SystemHà LêBelum ada peringkat
- PT Activity 4.3.3: Configure VTP: Topology DiagramDokumen7 halamanPT Activity 4.3.3: Configure VTP: Topology DiagramWayne E. BollmanBelum ada peringkat
- Dte Ut PaperDokumen1 halamanDte Ut Paperrashmi patilBelum ada peringkat
- User'S Manual: Revision 1.0aDokumen126 halamanUser'S Manual: Revision 1.0azeeshan ilyasBelum ada peringkat
- Multiprocessor and Real-Time Scheduling: Operating Systems: Internals and Design PrinciplesDokumen42 halamanMultiprocessor and Real-Time Scheduling: Operating Systems: Internals and Design Principlesmuhammad redhaBelum ada peringkat
- Careers360: NCO Class 9Dokumen3 halamanCareers360: NCO Class 9Divya RanjanBelum ada peringkat
- Weblogic Exercises PDFDokumen27 halamanWeblogic Exercises PDFparyabBelum ada peringkat
- JNCIA-Cloud Voucher Assessment ExamDokumen13 halamanJNCIA-Cloud Voucher Assessment ExamKamal Shovon0% (1)
- CIS 2030: Structure and Application of Microcomputers Computer Science Fall, 2013Dokumen3 halamanCIS 2030: Structure and Application of Microcomputers Computer Science Fall, 2013eggyolk98Belum ada peringkat
- Installation ManualDokumen18 halamanInstallation ManualNadeem AbbasiBelum ada peringkat
- Linux+Recommended+Settings-Multipathing-IO BalanceDokumen11 halamanLinux+Recommended+Settings-Multipathing-IO BalanceMeganathan RamanathanBelum ada peringkat
- SBC SWe Lite Datasheet - Virtualized SoftwareDokumen4 halamanSBC SWe Lite Datasheet - Virtualized SoftwareaureltataruBelum ada peringkat
- Learning Activity Sheet Special Program in Ict 9 Computer Systems Servicing 9Dokumen6 halamanLearning Activity Sheet Special Program in Ict 9 Computer Systems Servicing 9ria sevillaBelum ada peringkat
- NMS/EMS Systems Tracking and Governance For Central ElementsDokumen11 halamanNMS/EMS Systems Tracking and Governance For Central ElementsChakravarthi ChittajalluBelum ada peringkat
- BCA 513 Linux Operating System CIA I NotesDokumen8 halamanBCA 513 Linux Operating System CIA I NotessatwikBelum ada peringkat
- NomadFactory 80s-Spaces ManualDokumen13 halamanNomadFactory 80s-Spaces ManualJJSBelum ada peringkat
- Learning Modules IN TLE 221-Teaching Ict As An Exploratory CourseDokumen10 halamanLearning Modules IN TLE 221-Teaching Ict As An Exploratory CourseZoyBelum ada peringkat