Anda mungkin juga menyukai
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5795)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Commutation Relations For Toeplitz and Hankel MatricesDokumen19 halamanCommutation Relations For Toeplitz and Hankel MatricesTadiyos Hailemichael MamoBelum ada peringkat
- IPG Spring 2014 Incentive Publications Math, Science, Reading, Social Studies and Teacher Resources TitlesDokumen80 halamanIPG Spring 2014 Incentive Publications Math, Science, Reading, Social Studies and Teacher Resources TitlesIndependent Publishers GroupBelum ada peringkat
- Maths 30Dokumen11 halamanMaths 30BenBelum ada peringkat
- DiskretDokumen71 halamanDiskretChazy Satu Lapan DuaBelum ada peringkat
- Rekap Kurikulum (Rasio & Perbandingan) - Ib CurriculumDokumen2 halamanRekap Kurikulum (Rasio & Perbandingan) - Ib CurriculumMaulidia NurBelum ada peringkat
- CollegeAlgebra LRDokumen1.150 halamanCollegeAlgebra LRJd DibrellBelum ada peringkat
- Brain Test System: 1. Circle The Correct AnswerDokumen2 halamanBrain Test System: 1. Circle The Correct AnswerMZeeshanAkramBelum ada peringkat
- Cbjemass08 PDFDokumen10 halamanCbjemass08 PDFgirishvenggBelum ada peringkat
- Verifying Identities SolutionsDokumen2 halamanVerifying Identities SolutionsIsmail Medhat SalahBelum ada peringkat
- Min/Max/Saddle Points: Printed by Wolfram Mathematica Student EditionDokumen6 halamanMin/Max/Saddle Points: Printed by Wolfram Mathematica Student EditiontestBelum ada peringkat
- ILL Conditioned SystemsDokumen5 halamanILL Conditioned SystemsD.n.PrasadBelum ada peringkat
- IFEM Ch01Dokumen19 halamanIFEM Ch01Sahir AbasBelum ada peringkat
- 18BCE10291 - Outliers AssignmentDokumen10 halaman18BCE10291 - Outliers AssignmentvikramBelum ada peringkat
- (Springer Series in Synergetics 60) Yu. A. Kravtsov (Auth.), Professor Dr. Yurii A. Kravtsov (Eds.) - Limits of Predictability-Springer-Verlag Berlin Heidelberg (1993)Dokumen260 halaman(Springer Series in Synergetics 60) Yu. A. Kravtsov (Auth.), Professor Dr. Yurii A. Kravtsov (Eds.) - Limits of Predictability-Springer-Verlag Berlin Heidelberg (1993)Ashiq Elahi Design & Application EngineerBelum ada peringkat
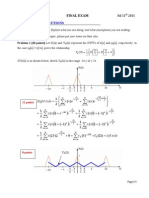
- EE341 FinalDokumen4 halamanEE341 FinalLe HuyBelum ada peringkat
- Spatial Referencing: Faculty of Applied Engineering and Urban Planning Civil Engineering DepartmentDokumen43 halamanSpatial Referencing: Faculty of Applied Engineering and Urban Planning Civil Engineering DepartmentMohammed Al MaqadmaBelum ada peringkat
- Electrical Power and Energy Systems: A. Augugliaro, L. Dusonchet, S. Favuzza, M.G. Ippolito, E. Riva SanseverinoDokumen10 halamanElectrical Power and Energy Systems: A. Augugliaro, L. Dusonchet, S. Favuzza, M.G. Ippolito, E. Riva SanseverinofirdoseBelum ada peringkat
- Mad111 Chap 4Dokumen145 halamanMad111 Chap 4Minh VuBelum ada peringkat
- Question Paper 3 - 2010 ClassDokumen2 halamanQuestion Paper 3 - 2010 ClassSaumil S. SharmaBelum ada peringkat
- Distribution of Waves and Wave Loads in A Random Sea: Application Example 12Dokumen4 halamanDistribution of Waves and Wave Loads in A Random Sea: Application Example 12Dr. Ir. R. Didin Kusdian, MT.Belum ada peringkat
- 02problem Set 2005Dokumen5 halaman02problem Set 2005vinibarcelosBelum ada peringkat
- Pre TestDokumen2 halamanPre TestPing Homigop Jamio100% (2)
- Sheet Metal Forming - 2Dokumen3 halamanSheet Metal Forming - 2HasanBadjrieBelum ada peringkat
- Trigonometric EquationsDokumen70 halamanTrigonometric EquationsPavan ChintalapatiBelum ada peringkat
- Vist Previa 4-Manifolds and Kirby CalculuDokumen45 halamanVist Previa 4-Manifolds and Kirby CalculuMariana CBelum ada peringkat
- Plane and Solid Review Module Nov2020finalDokumen2 halamanPlane and Solid Review Module Nov2020finalrhodel cosyeloBelum ada peringkat
- Weighted Regression in ExcelDokumen1 halamanWeighted Regression in Exceldardo1990Belum ada peringkat
- Chapter 1Dokumen27 halamanChapter 1Mainul Islam 312Belum ada peringkat
- NS FreefemDokumen49 halamanNS FreefemTheTruc NguyenBelum ada peringkat