Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
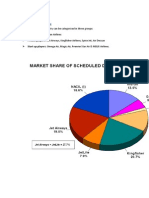
- KDD Market Report 2Dokumen1 halamanKDD Market Report 2Mohd MohsinBelum ada peringkat
- KDD Market ReportDokumen3 halamanKDD Market ReportMohd MohsinBelum ada peringkat
- Scan 4Dokumen1 halamanScan 4Mohd MohsinBelum ada peringkat
- IT ScribdDokumen12 halamanIT Scribdbijal_voraBelum ada peringkat
- RJ Collage Oc ProjectDokumen18 halamanRJ Collage Oc ProjectMohd MohsinBelum ada peringkat
- Industry AnalysisDokumen8 halamanIndustry AnalysisMohd MohsinBelum ada peringkat
- Humanresources 2Dokumen10 halamanHumanresources 2Mohd MohsinBelum ada peringkat
- 0 BorktxDokumen11 halaman0 BorktxMohd MohsinBelum ada peringkat
- Indian Small Car IndustryDokumen33 halamanIndian Small Car IndustryparagmasleBelum ada peringkat
- Password mk9580939030.: Mohd - Mohsin.khan2 Id of My Skype and Password mk8237368070, and Microsoft Id IsDokumen1 halamanPassword mk9580939030.: Mohd - Mohsin.khan2 Id of My Skype and Password mk8237368070, and Microsoft Id IsMohd MohsinBelum ada peringkat
- Introduction To Aviation IndustryDokumen10 halamanIntroduction To Aviation IndustryMohd MohsinBelum ada peringkat
- Indian Aviation IndustryDokumen25 halamanIndian Aviation IndustryMohd MohsinBelum ada peringkat
- Consumer BehaviourDokumen196 halamanConsumer BehaviourMohd MohsinBelum ada peringkat
- Mohd Mohsin KhanDokumen1 halamanMohd Mohsin KhanMohd MohsinBelum ada peringkat
- Consumer Markerting India (PVT) LTDDokumen8 halamanConsumer Markerting India (PVT) LTDMohd MohsinBelum ada peringkat
- Consumer Markerting India (PVT) LTDDokumen8 halamanConsumer Markerting India (PVT) LTDMohd MohsinBelum ada peringkat
- Figaro Daily ReportcDokumen15 halamanFigaro Daily ReportcMohd MohsinBelum ada peringkat
- Figaro Purchase RecordDokumen1 halamanFigaro Purchase RecordMohd MohsinBelum ada peringkat
- Figaro Purchase RecordDokumen1 halamanFigaro Purchase RecordMohd MohsinBelum ada peringkat
- Figaro: Consumer Marketing India (PVT) LTD Stock Record Name of S.O. Mohd. Mohsin. KhanDokumen2 halamanFigaro: Consumer Marketing India (PVT) LTD Stock Record Name of S.O. Mohd. Mohsin. KhanMohd MohsinBelum ada peringkat
- Question For The Assignment For Thhje EntrepreneurshDokumen12 halamanQuestion For The Assignment For Thhje EntrepreneurshMohd MohsinBelum ada peringkat
- Bertoli: Consumer Marketing India (PVT) LTD Stock Record Mohd - Mohsin.Khan (Shabi) Classico E-Tra Virgin E-Tra LightDokumen2 halamanBertoli: Consumer Marketing India (PVT) LTD Stock Record Mohd - Mohsin.Khan (Shabi) Classico E-Tra Virgin E-Tra LightMohd MohsinBelum ada peringkat
- Ahmed Raza KhanDokumen7 halamanAhmed Raza KhanMohd MohsinBelum ada peringkat
- Rs-1/- Extra Recharge Below Rs-50Dokumen1 halamanRs-1/- Extra Recharge Below Rs-50Mohd MohsinBelum ada peringkat
- Trains from Kalyan Jn to Allahabad JnDokumen2 halamanTrains from Kalyan Jn to Allahabad JnMohd MohsinBelum ada peringkat
- Rs-1/- Extra Recharge Below Rs-50Dokumen1 halamanRs-1/- Extra Recharge Below Rs-50Mohd MohsinBelum ada peringkat
- Historical Development of Organizational BehaviourDokumen35 halamanHistorical Development of Organizational BehaviourMohd MohsinBelum ada peringkat
- A Broad Definition of Research Is Given by MartynDokumen1 halamanA Broad Definition of Research Is Given by MartynMohd MohsinBelum ada peringkat
- Research Methods Project BreakdownDokumen47 halamanResearch Methods Project BreakdownMohd MohsinBelum ada peringkat
- 16 RMM Spring Edition 2020 Solutions CompressedDokumen83 halaman16 RMM Spring Edition 2020 Solutions CompressedKhokon GayenBelum ada peringkat
- Chapter 13: The Electronic Spectra of ComplexesDokumen42 halamanChapter 13: The Electronic Spectra of ComplexesAmalia AnggreiniBelum ada peringkat
- DebugDokumen14 halamanDebugMigui94Belum ada peringkat
- Welding Machine CatalogueDokumen12 halamanWelding Machine CatalogueRodney LanagBelum ada peringkat
- NEO PGM 'AND'/'OR' FunctionalityDokumen5 halamanNEO PGM 'AND'/'OR' FunctionalityAndre EinsteinBelum ada peringkat
- Treatment of Electroplating Wastewater Containing Cu2+, ZN 2+ and CR (VI) by ElectrocoagulationDokumen8 halamanTreatment of Electroplating Wastewater Containing Cu2+, ZN 2+ and CR (VI) by ElectrocoagulationAnonymous ZAr1RKBelum ada peringkat
- No.1 PrestressedDokumen10 halamanNo.1 PrestressedKristin ArgosinoBelum ada peringkat
- A Git Cheat Sheet (Git Command Reference) - A Git Cheat Sheet and Command ReferenceDokumen14 halamanA Git Cheat Sheet (Git Command Reference) - A Git Cheat Sheet and Command ReferenceMohd AzahariBelum ada peringkat
- Proportional Chopper Amplifier VB-3A: Min MaxDokumen5 halamanProportional Chopper Amplifier VB-3A: Min MaxryujoniBelum ada peringkat
- Digital Image Processing TechniquesDokumen34 halamanDigital Image Processing Techniquesaishuvc1822Belum ada peringkat
- IP46 - Guide To Use BAPCO WPS & Welding ProceduresDokumen4 halamanIP46 - Guide To Use BAPCO WPS & Welding ProceduressajiBelum ada peringkat
- 3-Lecture 03 Translational Mechanical System3-SDokumen23 halaman3-Lecture 03 Translational Mechanical System3-SHamza KhanBelum ada peringkat
- Order Change Management (OCM)Dokumen19 halamanOrder Change Management (OCM)Debasish BeheraBelum ada peringkat
- Fiziks: Basic Properties and Tools of ThermodynamicsDokumen28 halamanFiziks: Basic Properties and Tools of ThermodynamicsSURAJ PRATAP SINGHBelum ada peringkat
- 9 CE AmplifierDokumen5 halaman9 CE AmplifierAnsh PratapBelum ada peringkat
- Solution to Tutorials 1-4: Shock Absorber, Crane, SDOF Vibration, Landing GearDokumen19 halamanSolution to Tutorials 1-4: Shock Absorber, Crane, SDOF Vibration, Landing GearPearlyn Tiko TeoBelum ada peringkat
- SE 2003&2008 Pattern PDFDokumen799 halamanSE 2003&2008 Pattern PDFBenigno Tique Jonasse100% (1)
- TM View Software User - S ManualDokumen190 halamanTM View Software User - S ManualLuis SánchezBelum ada peringkat
- Ee242 Lect06 TwoportsDokumen32 halamanEe242 Lect06 TwoportsZyad IskandarBelum ada peringkat
- JefimenkoDokumen10 halamanJefimenkoBilly M. SpragueBelum ada peringkat
- Week 10 TelecommunicationsDokumen7 halamanWeek 10 TelecommunicationsGuido MartinezBelum ada peringkat
- PEA ClocksDokumen50 halamanPEA ClocksSuresh Reddy PolinatiBelum ada peringkat
- SteganographyDokumen13 halamanSteganographyIgloo JainBelum ada peringkat
- Code - Aster: Multiaxial Criteria of Starting in FatigueDokumen44 halamanCode - Aster: Multiaxial Criteria of Starting in FatigueYoyoBelum ada peringkat
- Is 14416 1996Dokumen20 halamanIs 14416 1996kaustavBelum ada peringkat
- BMW M5 ConfigurationDokumen12 halamanBMW M5 ConfigurationprasadBelum ada peringkat
- Debating Deponency: Its Past, Present, and Future in New Testament Greek StudiesDokumen32 halamanDebating Deponency: Its Past, Present, and Future in New Testament Greek StudiesSeth BrownBelum ada peringkat
- A RANS-based Analysis Ool For Ducted Propeller Systems in Open Water ConditionDokumen23 halamanA RANS-based Analysis Ool For Ducted Propeller Systems in Open Water ConditionLeonardo Duarte MilfontBelum ada peringkat
- KX DT543Dokumen74 halamanKX DT543Uriel Obregon BalbinBelum ada peringkat
- Sling PsychrometerDokumen8 halamanSling PsychrometerPavaniBelum ada peringkat