Anda mungkin juga menyukai
- Assignment No 1Dokumen5 halamanAssignment No 1AnkitGhildiyalBelum ada peringkat
- Logit AnalysisDokumen8 halamanLogit AnalysislilyBelum ada peringkat
- Assosa University School of Graduate Studies Mba ProgramDokumen10 halamanAssosa University School of Graduate Studies Mba Programyeneneh meseleBelum ada peringkat
- BSChem-Statistics in Chemical Analysis PDFDokumen6 halamanBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESBelum ada peringkat
- Minitab Tip Sheet 15Dokumen5 halamanMinitab Tip Sheet 15ixberisBelum ada peringkat
- Anoated Spss OutputDokumen8 halamanAnoated Spss OutputPRE027Belum ada peringkat
- Binomial PoissonDokumen19 halamanBinomial PoissonRoei ZoharBelum ada peringkat
- Biostatistics 101: Data Presentation: YhchanDokumen6 halamanBiostatistics 101: Data Presentation: YhchanThanos86Belum ada peringkat
- Dissertation Using Logistic RegressionDokumen6 halamanDissertation Using Logistic RegressionBuyCheapPapersSingapore100% (1)
- SPSS Regression Spring 2010Dokumen9 halamanSPSS Regression Spring 2010fuad_h05Belum ada peringkat
- Determing Statistical Significance of Skewness 121104Dokumen2 halamanDeterming Statistical Significance of Skewness 121104IMSQABelum ada peringkat
- SPSS ANNOTATED OUTPUT Multiple RegressionDokumen12 halamanSPSS ANNOTATED OUTPUT Multiple RegressionAditya MehraBelum ada peringkat
- 6 Basic Statistical ToolsDokumen30 halaman6 Basic Statistical Toolsdrs_mdu48Belum ada peringkat
- SPSS2 Guide Basic Non-ParametricsDokumen24 halamanSPSS2 Guide Basic Non-Parametricsrich_s_mooreBelum ada peringkat
- SPSS Binary Logistic Regression Demo 1 TerminateDokumen22 halamanSPSS Binary Logistic Regression Demo 1 Terminatefahadraja78Belum ada peringkat
- Final Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsDokumen11 halamanFinal Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsProf Bilal HassanBelum ada peringkat
- 10 - Regression - Explained - SPSS - Important For Basic ConceptDokumen23 halaman10 - Regression - Explained - SPSS - Important For Basic ConceptN FfBelum ada peringkat
- Introduction To Business Statistics Through R Software: SoftwareDari EverandIntroduction To Business Statistics Through R Software: SoftwareBelum ada peringkat
- Introduction To Predictive Modeling With Examples: David A. Dickey, N. Carolina State U., Raleigh, NCDokumen14 halamanIntroduction To Predictive Modeling With Examples: David A. Dickey, N. Carolina State U., Raleigh, NCtempla73Belum ada peringkat
- Standard Deviation DissertationDokumen5 halamanStandard Deviation DissertationOrderCustomPaperUK100% (1)
- Applied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabDari EverandApplied Statistics Manual: A Guide to Improving and Sustaining Quality with MinitabBelum ada peringkat
- SC968 Lecture 5 WorksheetDokumen8 halamanSC968 Lecture 5 WorksheetRafiaZamanBelum ada peringkat
- Logistic Regression Using SPSS: Presented by Nasser Hasan - Statistical Supporting Unit 7/8/2020 Nasser - Hasan@miami - EduDokumen30 halamanLogistic Regression Using SPSS: Presented by Nasser Hasan - Statistical Supporting Unit 7/8/2020 Nasser - Hasan@miami - EduNguyễn Khánh Ly100% (1)
- Chapter 13 - Tests For The Assumption That A Variable Is Normally Distributed Final - EditedDokumen4 halamanChapter 13 - Tests For The Assumption That A Variable Is Normally Distributed Final - Editedmehdi.chlif4374Belum ada peringkat
- Descriptive StatisticsDokumen6 halamanDescriptive StatisticsOvi IIIBelum ada peringkat
- Dissertation BoxplotDokumen8 halamanDissertation BoxplotPaySomeoneToWriteMyPaperCanada100% (1)
- 7-Multiple RegressionDokumen17 halaman7-Multiple Regressionحاتم سلطانBelum ada peringkat
- Descriptive StatisticsDokumen24 halamanDescriptive StatisticsCykeen Bofill DublonBelum ada peringkat
- A. Cause and Effect Diagram: Assignment-Set 1Dokumen26 halamanA. Cause and Effect Diagram: Assignment-Set 1Hariharan RajaramanBelum ada peringkat
- Dealing With ErrorsDokumen5 halamanDealing With ErrorsPun-Tak PangBelum ada peringkat
- 52) Statistical AnalysisDokumen11 halaman52) Statistical Analysisbobot80Belum ada peringkat
- Dwnload Full Understandable Statistics Concepts and Methods 12th Edition Brase Solutions Manual PDFDokumen36 halamanDwnload Full Understandable Statistics Concepts and Methods 12th Edition Brase Solutions Manual PDFteufitfatality6m12100% (9)
- 05 - Spps Logistic RegressionDokumen39 halaman05 - Spps Logistic RegressionESSA GHAZWANIBelum ada peringkat
- How To Do ANCOVA Problems in SPSSDokumen9 halamanHow To Do ANCOVA Problems in SPSSChad JamesBelum ada peringkat
- Descriptive StatisticsDokumen6 halamanDescriptive StatisticsRuach Dak TangBelum ada peringkat
- Paired T-TestDokumen7 halamanPaired T-TestJazzel Queny ZalduaBelum ada peringkat
- Logistic Regression WRD FileDokumen11 halamanLogistic Regression WRD Fileasdfg1987Belum ada peringkat
- App 3035 - Lecture 1 Research DesignDokumen16 halamanApp 3035 - Lecture 1 Research DesignAyden ShawBelum ada peringkat
- 6418 Chapter 3A Meyers I Proof 2Dokumen32 halaman6418 Chapter 3A Meyers I Proof 2Lei XingBelum ada peringkat
- Heather Walen-Frederick SPSS HandoutDokumen13 halamanHeather Walen-Frederick SPSS HandoutshmmalyBelum ada peringkat
- Methods For ProportionsDokumen19 halamanMethods For Proportionsdivyarai12345Belum ada peringkat
- Applied Survival Analysis: Regression Modeling of Time-to-Event DataDari EverandApplied Survival Analysis: Regression Modeling of Time-to-Event DataPenilaian: 4 dari 5 bintang4/5 (2)
- Notes On Data Processing, Analysis, PresentationDokumen63 halamanNotes On Data Processing, Analysis, Presentationjaneth pallangyoBelum ada peringkat
- Practical Engineering, Process, and Reliability StatisticsDari EverandPractical Engineering, Process, and Reliability StatisticsBelum ada peringkat
- Materi Chapter 6Dokumen11 halamanMateri Chapter 6cindy khairunnisaBelum ada peringkat
- Descriptive StatisticsDokumen5 halamanDescriptive StatisticsEmelson VertucioBelum ada peringkat
- Data Analysis Chp9 RMDokumen9 halamanData Analysis Chp9 RMnikjadhavBelum ada peringkat
- Data AnlalysisDokumen6 halamanData Anlalysisرجب جبBelum ada peringkat
- Descriptive Statistics Using Microsoft ExcelDokumen5 halamanDescriptive Statistics Using Microsoft ExcelVasant bhoknalBelum ada peringkat
- The Intraclass Correlation Coefficient: Is Your Measurement System Adequate? Donald J. WheelerDokumen10 halamanThe Intraclass Correlation Coefficient: Is Your Measurement System Adequate? Donald J. Wheelertehky63Belum ada peringkat
- Binomial Logistic Regression Using SPSSDokumen11 halamanBinomial Logistic Regression Using SPSSKhurram ZahidBelum ada peringkat
- Pam3100 Ps5 Revised Spring 2018Dokumen5 halamanPam3100 Ps5 Revised Spring 2018Marta Zavaleta DelgadoBelum ada peringkat
- QMT 3001 Business Forecasting Term ProjectDokumen30 halamanQMT 3001 Business Forecasting Term ProjectEKREM ÇAMURLUBelum ada peringkat
- Measurement ScalesDokumen6 halamanMeasurement ScalesRohit PandeyBelum ada peringkat
- Regression Explained SPSSDokumen23 halamanRegression Explained SPSSAngel Sanu100% (1)
- WWW Social Research Methods Net KB Statdesc PHPDokumen87 halamanWWW Social Research Methods Net KB Statdesc PHPNexBengson100% (1)
- Machine Learning - A Complete Exploration of Highly Advanced Machine Learning Concepts, Best Practices and Techniques: 4Dari EverandMachine Learning - A Complete Exploration of Highly Advanced Machine Learning Concepts, Best Practices and Techniques: 4Belum ada peringkat
- Error Types and Error PropagationDokumen6 halamanError Types and Error PropagationDerioUnboundBelum ada peringkat
- Chapter 2: Statistical Tests, Confidence Intervals and Comparative StudiesDokumen75 halamanChapter 2: Statistical Tests, Confidence Intervals and Comparative Studieslinda kumalayantiBelum ada peringkat
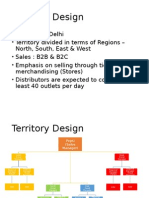
- PepsiCo Sales Territory DesignDokumen5 halamanPepsiCo Sales Territory Designhaider_simple71Belum ada peringkat
- PepsiCo Sales Territory DesignDokumen5 halamanPepsiCo Sales Territory Designhaider_simple71Belum ada peringkat
- Graphical Representation of ResponsesDokumen23 halamanGraphical Representation of Responseshaider_simple71Belum ada peringkat
- Zara Scm.Dokumen24 halamanZara Scm.haider_simple71100% (1)
- Ibm Watson TestDokumen17 halamanIbm Watson Testfahmi1987Belum ada peringkat
- Daa - Mini - Project (1) OrginalDokumen21 halamanDaa - Mini - Project (1) OrginalHarsh GuptaBelum ada peringkat
- Evolving Intelligent System For Classification Twitter Data: Dr. Yossra Hussain AliDokumen16 halamanEvolving Intelligent System For Classification Twitter Data: Dr. Yossra Hussain Aliحيدر محمدBelum ada peringkat
- Presented By: Group 3: Cacayan, Grace L. Canlas, Rinalyn O. Celestial, Artchie EDokumen9 halamanPresented By: Group 3: Cacayan, Grace L. Canlas, Rinalyn O. Celestial, Artchie EPatrick MakalintalBelum ada peringkat
- Evans Analytics2e PPT 10 Data MiningDokumen69 halamanEvans Analytics2e PPT 10 Data MiningCajetan1957Belum ada peringkat
- Personalized Food Recommendation System by Using Machine Learning ModelsDokumen5 halamanPersonalized Food Recommendation System by Using Machine Learning ModelsInternational Journal of Innovative Science and Research TechnologyBelum ada peringkat
- Diabetes Prediction Using Machine Learning KNN - Algorithm TechniqueDokumen4 halamanDiabetes Prediction Using Machine Learning KNN - Algorithm TechniqueInternational Journal of Innovative Science and Research TechnologyBelum ada peringkat
- Big Data in The Construction Industry A Review of Present Status, Opportunities, and Future TrendsDokumen42 halamanBig Data in The Construction Industry A Review of Present Status, Opportunities, and Future TrendsCatalina Maria Vlad100% (3)
- Proceedings ECT 2009Dokumen386 halamanProceedings ECT 2009Carlos Lino Rojas Agüero100% (1)
- Unit 5 - Week 4: Assignment 4Dokumen4 halamanUnit 5 - Week 4: Assignment 4Raushan KashyapBelum ada peringkat
- Aisyah Ariana Hamdan - Interim ReportDokumen26 halamanAisyah Ariana Hamdan - Interim Reportkshafee.kalid7988Belum ada peringkat
- Expert Systems With Applications: Yu-Ling Yeh, Tung-Hsu Hou, Wen-Yen ChangDokumen10 halamanExpert Systems With Applications: Yu-Ling Yeh, Tung-Hsu Hou, Wen-Yen ChangPaula CelsieBelum ada peringkat
- Artificial Intelligence and The Reshaping of SEO: A Quantitative Analysis of AI-Driven Content Effects On Search AlgorithmsDokumen7 halamanArtificial Intelligence and The Reshaping of SEO: A Quantitative Analysis of AI-Driven Content Effects On Search AlgorithmsInternational Journal of Innovative Science and Research TechnologyBelum ada peringkat
- Kaufmann - Genetic Programming - An IntroductionDokumen481 halamanKaufmann - Genetic Programming - An IntroductiongjorhugullBelum ada peringkat
- Up-2 Project ReportDokumen64 halamanUp-2 Project ReportG dileep KumarBelum ada peringkat
- Soft Computing Question PaperDokumen2 halamanSoft Computing Question PaperAnonymous 4bUl7jzGqBelum ada peringkat
- Corrected MainDokumen44 halamanCorrected MainVikramBelum ada peringkat
- ML Lab Manual AIML FinalDokumen61 halamanML Lab Manual AIML Finalsushankreddy0712Belum ada peringkat
- 15CSL76Dokumen35 halaman15CSL76suharika suharikaBelum ada peringkat
- M.Tech - Dissertation PresentationDokumen28 halamanM.Tech - Dissertation Presentationmkiran02Belum ada peringkat
- Assignment of Decision Tree in Machine LearningDokumen15 halamanAssignment of Decision Tree in Machine LearningFrederick S LeeBelum ada peringkat
- Introduction To Unsupervised Learning:: ClusteringDokumen21 halamanIntroduction To Unsupervised Learning:: Clusteringmohini senBelum ada peringkat
- CS467 Machine LearningDokumen3 halamanCS467 Machine LearningEbin PunnethottathilBelum ada peringkat
- Ec 467 Pattern RecognitionDokumen2 halamanEc 467 Pattern RecognitionJustin SajuBelum ada peringkat
- Agricultural and Food Engineering (Dual Degree) : Shubham Patidar - 16ag30024Dokumen1 halamanAgricultural and Food Engineering (Dual Degree) : Shubham Patidar - 16ag30024Shubham PatidarBelum ada peringkat
- Final Exam BWA44603Dokumen4 halamanFinal Exam BWA44603Mohd Asrul Affendi AbdullahBelum ada peringkat
- ICDAR 2021 Competition On On-Line Signature Verification: September 2021Dokumen17 halamanICDAR 2021 Competition On On-Line Signature Verification: September 2021Hannah JanawaBelum ada peringkat
- Bagging and Random Forest Presentation1Dokumen23 halamanBagging and Random Forest Presentation1endale100% (2)
- Hand Written Digit Recognition Using Artificial Neural NetworkDokumen10 halamanHand Written Digit Recognition Using Artificial Neural NetworkRavi ShankarBelum ada peringkat
- F# For Machine Learning Essentials - Sample ChapterDokumen29 halamanF# For Machine Learning Essentials - Sample ChapterPackt PublishingBelum ada peringkat