Anda mungkin juga menyukai
- Mobile Application Usability EvaluationDokumen5 halamanMobile Application Usability EvaluationkorisnikkkBelum ada peringkat
- Usability of Mobile Applications: Literature Review and Rationale For A New Usability ModelDokumen16 halamanUsability of Mobile Applications: Literature Review and Rationale For A New Usability ModelBernadette MontesBelum ada peringkat
- The State of The Art of Mobile Application Usability EvaluationDokumen6 halamanThe State of The Art of Mobile Application Usability EvaluationDesi ArisandiBelum ada peringkat
- Measuring The User Experience On A Large Scale: User-Centered Metrics For Web ApplicationsDokumen4 halamanMeasuring The User Experience On A Large Scale: User-Centered Metrics For Web ApplicationsMichael StephanblomeBelum ada peringkat
- Web Usability: Principles and Evaluation Methods: Abstract: Current Web Applications Are Very Complex and HighDokumen39 halamanWeb Usability: Principles and Evaluation Methods: Abstract: Current Web Applications Are Very Complex and HighThabetIssaouiBelum ada peringkat
- The Usability Metrics For User ExperienceDokumen6 halamanThe Usability Metrics For User ExperienceVIVA-TECH IJRIBelum ada peringkat
- Heuristic Evaluation On Mobile InterfacesDokumen20 halamanHeuristic Evaluation On Mobile Interfacesroman1978Belum ada peringkat
- A Strategic-Oriented Method For Web Applications Design: A Case StudyDokumen6 halamanA Strategic-Oriented Method For Web Applications Design: A Case StudyS Adryan GintingBelum ada peringkat
- 2194 0827 1 1 PDFDokumen16 halaman2194 0827 1 1 PDFZye QuinBelum ada peringkat
- Improving Mobile Application DevelopmentDokumen4 halamanImproving Mobile Application DevelopmentArindam BanerjeeBelum ada peringkat
- Assessing Educational Web-Site Usability Using Heuristic Evaluation RulesDokumen8 halamanAssessing Educational Web-Site Usability Using Heuristic Evaluation RulesLoai F AlzouabiBelum ada peringkat
- Alignment of Stakeholder Expectations About User Involvement in Agile Software DevelopmentDokumen11 halamanAlignment of Stakeholder Expectations About User Involvement in Agile Software DevelopmentMuhammad Ridwan Adi NugrahaBelum ada peringkat
- Cost Estimation in Agile Software Development: Utilizing Functional Size Measurement MethodsDari EverandCost Estimation in Agile Software Development: Utilizing Functional Size Measurement MethodsBelum ada peringkat
- Learning Mobile App DesignDokumen8 halamanLearning Mobile App DesignAndres Fernando Cuellar CardonaBelum ada peringkat
- Ass WebDokumen3 halamanAss WebMuhammad AshirBelum ada peringkat
- An Improved Usability Evaluation Model For Point-of-Sale SystemsDokumen15 halamanAn Improved Usability Evaluation Model For Point-of-Sale SystemsRonald AbletesBelum ada peringkat
- Evaluating Web Usability From The User's PerspectiveDokumen4 halamanEvaluating Web Usability From The User's PerspectiveÓscar González ColónBelum ada peringkat
- Phase 5 Part 1Dokumen2 halamanPhase 5 Part 1AliBelum ada peringkat
- Ijettcs 2014 06 25 137Dokumen6 halamanIjettcs 2014 06 25 137International Journal of Application or Innovation in Engineering & ManagementBelum ada peringkat
- Assigment Task2 (AutoRecovered)Dokumen3 halamanAssigment Task2 (AutoRecovered)Kaung Kaung Thant Linn 123Belum ada peringkat
- Usability of Mobile Applications A Systematic Literature Study - 45861Dokumen15 halamanUsability of Mobile Applications A Systematic Literature Study - 45861MAGUZMANR1Belum ada peringkat
- Comparison of Development Methodologies in Web ApplicationsDokumen21 halamanComparison of Development Methodologies in Web ApplicationsJason K. RubinBelum ada peringkat
- Accessibility in Software Practice: A Practitioner's PerspectiveDokumen26 halamanAccessibility in Software Practice: A Practitioner's PerspectivewasimsseBelum ada peringkat
- Integrating Usability Engineering and Agile Software Development A Literature ReviewDokumen8 halamanIntegrating Usability Engineering and Agile Software Development A Literature ReviewafdtukasgBelum ada peringkat
- Azham Hussain 3Dokumen8 halamanAzham Hussain 3Carl Harold AranaydoBelum ada peringkat
- Master Thesis Decision MakingDokumen14 halamanMaster Thesis Decision Makingjorisdeboer1997Belum ada peringkat
- Weekly JournalDokumen6 halamanWeekly Journalshemdennis53Belum ada peringkat
- Usability Metric Framework For Mobile Phone Application: Azham Hussain Maria KutarDokumen5 halamanUsability Metric Framework For Mobile Phone Application: Azham Hussain Maria Kutarkichan992Belum ada peringkat
- Opportunities and Challenges of Software CustomizationDokumen11 halamanOpportunities and Challenges of Software CustomizationIDESBelum ada peringkat
- A Critical Evaluation of Popular Ux Frameworksrelevant To E-Health AppsDokumen10 halamanA Critical Evaluation of Popular Ux Frameworksrelevant To E-Health AppsAnonymous BI4sNIkiNwBelum ada peringkat
- Architecting High Performing, Scalable and Available Enterprise Web ApplicationsDari EverandArchitecting High Performing, Scalable and Available Enterprise Web ApplicationsPenilaian: 4.5 dari 5 bintang4.5/5 (2)
- Mobile Application Benchmarking Basedonthe Resource Usage MonitoringDokumen15 halamanMobile Application Benchmarking Basedonthe Resource Usage Monitoringhtmnhung4Belum ada peringkat
- Summary of LinkedlnDokumen7 halamanSummary of LinkedlnCh Bilal MakenBelum ada peringkat
- ITECH7405: Subject Code: Subject Title: Assignment Number and Titile: Word Count (If Applicable) : 5000Dokumen21 halamanITECH7405: Subject Code: Subject Title: Assignment Number and Titile: Word Count (If Applicable) : 5000Pradip GuptaBelum ada peringkat
- Web Application Quality Measurement Using Heuristic MethodDokumen10 halamanWeb Application Quality Measurement Using Heuristic MethodIJAR JOURNALBelum ada peringkat
- The Impact of In-House Software Development Practices On System Usability in The Social Security Funds in TanzaniaDokumen12 halamanThe Impact of In-House Software Development Practices On System Usability in The Social Security Funds in TanzaniaijmitBelum ada peringkat
- Investigating The Awareness of Applying The Important Web Application Development and Measurement Practices in Small Software FirmsDokumen12 halamanInvestigating The Awareness of Applying The Important Web Application Development and Measurement Practices in Small Software FirmsAnonymous Gl4IRRjzNBelum ada peringkat
- Web Services With Java EE 6: An Example Using Planning in ReverseDokumen7 halamanWeb Services With Java EE 6: An Example Using Planning in Reverseمحمد المؤذنBelum ada peringkat
- Usability Metric Framework For Mobile Phone Application: June 2009Dokumen6 halamanUsability Metric Framework For Mobile Phone Application: June 2009sus023Belum ada peringkat
- 5 Software As A Service ModelDokumen7 halaman5 Software As A Service ModelNydia Massiel SanchezBelum ada peringkat
- Banimahendra, R., & Santoso, H. (2018) - Implementation and Evaluation of LMS Mobile Application. Scele Mobile Based On User-Centered DesignDokumen8 halamanBanimahendra, R., & Santoso, H. (2018) - Implementation and Evaluation of LMS Mobile Application. Scele Mobile Based On User-Centered DesignYanBelum ada peringkat
- Entropy: How To Utilize My App Reviews? A Novel Topics Extraction Machine Learning Schema For Strategic Business PurposesDokumen21 halamanEntropy: How To Utilize My App Reviews? A Novel Topics Extraction Machine Learning Schema For Strategic Business PurposesJesus AlarconBelum ada peringkat
- US Agile Journal XDX 090309Dokumen3 halamanUS Agile Journal XDX 090309tsap33Belum ada peringkat
- 22-W-Evaluating and Comparing The Usability of Mobile Banking Applications in Saudi ArabiaDokumen14 halaman22-W-Evaluating and Comparing The Usability of Mobile Banking Applications in Saudi ArabiaJhon DoeBelum ada peringkat
- Ba FaqDokumen14 halamanBa FaqKavya AmbekarBelum ada peringkat
- Adopting User-Centred Development For Arabic E-Commerce WebsitesDokumen17 halamanAdopting User-Centred Development For Arabic E-Commerce WebsitesijwestBelum ada peringkat
- User Experience Re-Mastered: Your Guide to Getting the Right DesignDari EverandUser Experience Re-Mastered: Your Guide to Getting the Right DesignBelum ada peringkat
- Modelos Concepuales en Proyectos AgilesDokumen22 halamanModelos Concepuales en Proyectos AgilesDarwin Ore RiveraBelum ada peringkat
- Paper Participatory-Usability SafariDokumen6 halamanPaper Participatory-Usability SafariAgostinho FranklinBelum ada peringkat
- HCI in The Software ProcessDokumen7 halamanHCI in The Software ProcessAhyel Libunao100% (1)
- RiportDokumen130 halamanRiport720 026 Promita GhoruiBelum ada peringkat
- Eval MethodDokumen21 halamanEval MethodF'ee MouangsunBelum ada peringkat
- E-Commerce Development Using AngularJS Framework ADokumen11 halamanE-Commerce Development Using AngularJS Framework AMinh TrịnhBelum ada peringkat
- Usability Lazada MobileDokumen7 halamanUsability Lazada MobileAkumA100% (1)
- Usability of Mobile Applications (2013) : Case Study of A Computer Based Examination System (2015)Dokumen2 halamanUsability of Mobile Applications (2013) : Case Study of A Computer Based Examination System (2015)nezclarkBelum ada peringkat
- Agile Customer Engagement A Longitudinal Qualitative Case StudyDokumen10 halamanAgile Customer Engagement A Longitudinal Qualitative Case StudyOdnooMgmrBelum ada peringkat
- Rad PawanDokumen6 halamanRad PawanGagandeep RatheeBelum ada peringkat
- Challenges and Best Practices For Mobile ApplicationDokumen8 halamanChallenges and Best Practices For Mobile ApplicationmukiBelum ada peringkat
- Issn 2321-0869 PDFDokumen6 halamanIssn 2321-0869 PDFKezia WendiBelum ada peringkat
- The Definitive JavaScript Handbook For A Developer InterviewDokumen34 halamanThe Definitive JavaScript Handbook For A Developer Interviewray_xBelum ada peringkat
- Impress Your Friends With Mental Math TricksDokumen6 halamanImpress Your Friends With Mental Math Tricksray_xBelum ada peringkat
- Media Queries Cheat Sheet (Hoja de Trampa) - I FuckingLoveCodingDokumen14 halamanMedia Queries Cheat Sheet (Hoja de Trampa) - I FuckingLoveCodingray_xBelum ada peringkat
- Talking About The Past - Try - Activities © BBC - British Council 2007Dokumen1 halamanTalking About The Past - Try - Activities © BBC - British Council 2007ray_xBelum ada peringkat
- 10 Easy Arithmetic TricksDokumen5 halaman10 Easy Arithmetic Tricksray_xBelum ada peringkat
- Marcel and The Mona LisaDokumen2 halamanMarcel and The Mona Lisaray_xBelum ada peringkat
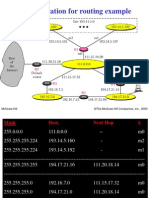
- Configuration For Routing Example: Mcgraw-Hill ©the Mcgraw-Hill Companies, Inc., 2000Dokumen17 halamanConfiguration For Routing Example: Mcgraw-Hill ©the Mcgraw-Hill Companies, Inc., 2000ray_xBelum ada peringkat
- IDA - MTCS X-Cert - Gap Analysis Report - MTCS To ISO270012013 - ReleaseDokumen50 halamanIDA - MTCS X-Cert - Gap Analysis Report - MTCS To ISO270012013 - ReleasekinzaBelum ada peringkat
- Shell Omala BrochureDokumen2 halamanShell Omala BrochurehuseynseymenBelum ada peringkat
- Gloomy Picture For Paint Highlights Depth of Supply Chain Crisis - Financial TimesDokumen8 halamanGloomy Picture For Paint Highlights Depth of Supply Chain Crisis - Financial Timesnoemie-quinnBelum ada peringkat
- TP-16 Schedule Analysis Techniques, MajerowiczDokumen45 halamanTP-16 Schedule Analysis Techniques, MajerowiczYossi Habibie100% (1)
- Ductwork Order FormDokumen5 halamanDuctwork Order FormShaun SullivanBelum ada peringkat
- Forming Process ReportDokumen4 halamanForming Process ReportAqib ZamanBelum ada peringkat
- Chapter 26 CroppedDokumen36 halamanChapter 26 Croppedgrantswaim100% (1)
- IGC3 Exam Template 2Dokumen17 halamanIGC3 Exam Template 2mibshBelum ada peringkat
- Implementation of ErpDokumen38 halamanImplementation of ErpAbhishek PatodiaBelum ada peringkat
- High Powered Committee Final Report On Traffic Management For MumbaiDokumen51 halamanHigh Powered Committee Final Report On Traffic Management For MumbaiRishi AggarwalBelum ada peringkat
- QS - Lesson - Plan PDFDokumen2 halamanQS - Lesson - Plan PDFrajaanwarBelum ada peringkat
- Metallurgical Factors Influencing The Machinability of Inconel 718 - SchirraDokumen12 halamanMetallurgical Factors Influencing The Machinability of Inconel 718 - SchirraAntonioBelum ada peringkat
- A 2020 Insights IAS Subjectwise Test 23Dokumen62 halamanA 2020 Insights IAS Subjectwise Test 23Sandeep SoniBelum ada peringkat
- Exhibit J - List of Vendor and SubcontractorDokumen62 halamanExhibit J - List of Vendor and SubcontractorpragatheeskBelum ada peringkat
- OvationDokumen12 halamanOvationeshanrastogiBelum ada peringkat
- Resource Planning & ProductivityDokumen19 halamanResource Planning & ProductivityVinit Kant Majumdar67% (3)
- Castrol Spheerol EPLDokumen2 halamanCastrol Spheerol EPLDiego GalvanBelum ada peringkat
- Auto Industry Case StudyDokumen5 halamanAuto Industry Case StudySabah khurshidBelum ada peringkat
- PFMEADokumen6 halamanPFMEAAcep GunawanBelum ada peringkat
- Router BitDokumen44 halamanRouter Bitsunrise designBelum ada peringkat
- Pihak Berkuasa Penerbangan Awam Malaysia (Civil Aviation Authority of Malaysia) Application For Unmanned Aircraft System (Uas) / DroneDokumen11 halamanPihak Berkuasa Penerbangan Awam Malaysia (Civil Aviation Authority of Malaysia) Application For Unmanned Aircraft System (Uas) / DroneMuhammad Fahmi MahmudBelum ada peringkat
- Buscar Filtro - Wix FiltersDokumen1 halamanBuscar Filtro - Wix FiltersRodolfo PerezBelum ada peringkat
- ISTQB Question Paper20Dokumen53 halamanISTQB Question Paper20rashmikupsadBelum ada peringkat
- Sop Piling WorkDokumen2 halamanSop Piling WorkamirBelum ada peringkat
- Functional SafetyDokumen4 halamanFunctional SafetyMsKarolyBelum ada peringkat
- Hexa Research IncDokumen5 halamanHexa Research Incapi-293819200Belum ada peringkat
- 06 Television in The United StatesDokumen42 halaman06 Television in The United StatesMilena ŠmigićBelum ada peringkat
- VDR Website Supplier InstructionsDokumen1 halamanVDR Website Supplier InstructionszalzizaBelum ada peringkat
- JobSparx - June 18th IssueDokumen36 halamanJobSparx - June 18th IssueJobSparxBelum ada peringkat