Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Automation Project Plan TemplateDokumen8 halamanAutomation Project Plan TemplateRamamurthyBelum ada peringkat
- CadScriptingLanguages SkillDokumen10 halamanCadScriptingLanguages SkillPraveen Meduri0% (1)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Full Chip Verification FlowDokumen7 halamanFull Chip Verification FlowSamBelum ada peringkat
- 59 5Dokumen11 halaman59 5SamBelum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Big Query GoogleDokumen62 halamanBig Query GoogleJuan Carlos Lara GallegoBelum ada peringkat
- Hive Mock TestDokumen6 halamanHive Mock TestAshraf Khan100% (1)
- Stack7 Cloud Runbook R19Dokumen46 halamanStack7 Cloud Runbook R19natarajan100% (2)
- Design Reuse Without Verification Reuse Is UselessDokumen7 halamanDesign Reuse Without Verification Reuse Is UselessSamBelum ada peringkat
- 6S TrainingDokumen40 halaman6S Trainingayaskant751001100% (2)
- Automated Testing Best PracticesDokumen5 halamanAutomated Testing Best PracticesvavakuttiBelum ada peringkat
- Metric Driven Verification of Mixed-Signal Designs: Neyaz Khan Yaron Kashai Hao FangDokumen6 halamanMetric Driven Verification of Mixed-Signal Designs: Neyaz Khan Yaron Kashai Hao FangSamBelum ada peringkat
- PHP Vs Python Vs RubyDokumen16 halamanPHP Vs Python Vs Rubymarkwang01Belum ada peringkat
- 111 AmbaDokumen7 halaman111 AmbaSam0% (1)
- 1502-Advanced VHDL Verification DatasheetDokumen1 halaman1502-Advanced VHDL Verification DatasheetSamBelum ada peringkat
- Welcome To The VHDL LanguageDokumen399 halamanWelcome To The VHDL LanguageardserBelum ada peringkat
- Is It Time To Declare A Verification War?: Brian BaileyDokumen41 halamanIs It Time To Declare A Verification War?: Brian BaileySamBelum ada peringkat
- Automated Testing Best PracticesDokumen5 halamanAutomated Testing Best PracticesvavakuttiBelum ada peringkat
- 557 Ijar-6553Dokumen7 halaman557 Ijar-6553SamBelum ada peringkat
- Emtech Core VerificationDokumen1 halamanEmtech Core VerificationSamBelum ada peringkat
- HW Simulator Perf Scaling Adv Node Soc TPDokumen9 halamanHW Simulator Perf Scaling Adv Node Soc TPSamBelum ada peringkat
- White Papers On Ieee 802.19Dokumen33 halamanWhite Papers On Ieee 802.19JAUNITHABelum ada peringkat
- Cdnlive Jungeblut PaperDokumen5 halamanCdnlive Jungeblut PaperSamBelum ada peringkat
- Ee201 TestbenchDokumen19 halamanEe201 TestbenchSamBelum ada peringkat
- Advanced Verification Techniques Approach Successful 510ODzCvcLLDokumen4 halamanAdvanced Verification Techniques Approach Successful 510ODzCvcLLSamBelum ada peringkat
- Verilog For TestbenchesDokumen18 halamanVerilog For TestbenchesAhmed Fathy Moustafa100% (1)
- Course Module ASIC VerificationDokumen6 halamanCourse Module ASIC VerificationSamBelum ada peringkat
- FSM Design Example With VerilogDokumen23 halamanFSM Design Example With Verilogkhan125Belum ada peringkat
- Verilog For TestbenchesDokumen18 halamanVerilog For TestbenchesAhmed Fathy Moustafa100% (1)
- Case Study Intelligent Storage Network Processor VerificationDokumen2 halamanCase Study Intelligent Storage Network Processor VerificationSamBelum ada peringkat
- A Verification Methodology For Reusable Test Cases and Coverage Based On System VerilogDokumen2 halamanA Verification Methodology For Reusable Test Cases and Coverage Based On System VerilogSamBelum ada peringkat
- The Current Topic: Python Announcements: Lecture RoomDokumen7 halamanThe Current Topic: Python Announcements: Lecture RoomSamBelum ada peringkat
- Bringing Formal Property Verification Methodology To An ASIC DesignDokumen8 halamanBringing Formal Property Verification Methodology To An ASIC DesignSamBelum ada peringkat
- Is It Time To Declare A Verification War?: Brian BaileyDokumen41 halamanIs It Time To Declare A Verification War?: Brian BaileySamBelum ada peringkat
- WEB API Interview QuestionsDokumen23 halamanWEB API Interview Questionsmanish srivastavaBelum ada peringkat
- 1.MS Access TutorialDokumen3 halaman1.MS Access TutorialSoumyajitDasBelum ada peringkat
- Good Programming Practice (GPP) in SAS® & Clinical TrialsDokumen10 halamanGood Programming Practice (GPP) in SAS® & Clinical TrialsSandeep BellapuBelum ada peringkat
- Exam Az 900 Microsoft Azure Fundamentals Skills MeasuredDokumen8 halamanExam Az 900 Microsoft Azure Fundamentals Skills MeasuredGilvanio NascimentoBelum ada peringkat
- 13 SymbolTableDokumen13 halaman13 SymbolTableAadhesh Malola ABelum ada peringkat
- Full Stack - nd0044 - SyllabusDokumen16 halamanFull Stack - nd0044 - SyllabusUsman Ghani BawanyBelum ada peringkat
- E03 ReferenceDataModel TryMeDokumen30 halamanE03 ReferenceDataModel TryMeVigneshwaran JBelum ada peringkat
- ONLINE VOTING SYSTEmDokumen33 halamanONLINE VOTING SYSTEmVinoth Kumar57% (14)
- Developing A Grading and Monitoring System: Towards An Effective Academic EvaluationDokumen5 halamanDeveloping A Grading and Monitoring System: Towards An Effective Academic EvaluationCharles CamralBelum ada peringkat
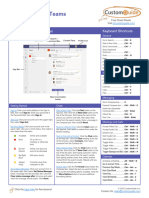
- Microsoft Teams Cheat SheetDokumen3 halamanMicrosoft Teams Cheat SheetMichael AbionaBelum ada peringkat
- Load Generator and Combination For RAM STRUCTURAL SYSTEMDokumen28 halamanLoad Generator and Combination For RAM STRUCTURAL SYSTEMWilbert ReuyanBelum ada peringkat
- Xtream 18Dokumen4 halamanXtream 18mhmdmhmood1770100% (1)
- ECZ Plant Maintenance WF Technical Design DocumentDokumen14 halamanECZ Plant Maintenance WF Technical Design DocumentTinashe BwakuraBelum ada peringkat
- Memory ManagementDokumen22 halamanMemory ManagementRehman ButtBelum ada peringkat
- MSTR Vs LookerDokumen45 halamanMSTR Vs LookerVictor FloresBelum ada peringkat
- VamaDokumen4 halamanVamaSanthosh k mBelum ada peringkat
- A Deep Dive Into Testing With TaskCat - Infrastructure & AutomationDokumen8 halamanA Deep Dive Into Testing With TaskCat - Infrastructure & AutomationPatricia FillipsBelum ada peringkat
- Test Driven Development Method in Software Development ProcessDokumen5 halamanTest Driven Development Method in Software Development ProcessRS BGM PROBelum ada peringkat
- Case Study On Cloud SecurityDokumen11 halamanCase Study On Cloud SecurityJohn Singh100% (1)
- Cucumber Framework: Prepared by Prasath Sambanthamoorthy, Qa TeamDokumen31 halamanCucumber Framework: Prepared by Prasath Sambanthamoorthy, Qa Teampooja singhBelum ada peringkat
- XII MS Computer Science PB-1 (2023-24)Dokumen9 halamanXII MS Computer Science PB-1 (2023-24)ujjwaldixit9452Belum ada peringkat
- Reality Show Management - TutorialsDuniyaDokumen44 halamanReality Show Management - TutorialsDuniyaJanvi SharmaBelum ada peringkat
- VLSI Design: SkillDokumen44 halamanVLSI Design: SkillPika ChuBelum ada peringkat
- Oracle Cloud Infrastructure 2019 Sales Specialist AssessmentDokumen3 halamanOracle Cloud Infrastructure 2019 Sales Specialist AssessmentааппBelum ada peringkat
- Courier Service Project ReportDokumen81 halamanCourier Service Project ReportSaranya GangBelum ada peringkat
- Lab 05 and 06 Shell ScriptingDokumen15 halamanLab 05 and 06 Shell ScriptingShahid ZikriaBelum ada peringkat
- FSD Offline PapDokumen3 halamanFSD Offline PapArun KrishnanBelum ada peringkat