Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Role of Scientific CommitteeDokumen1 halamanRole of Scientific CommitteeminaBelum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- New Drug Innovation and Pharmaceutical Industry Structure: Trends in The Output of Pharmaceutical FirmsDokumen26 halamanNew Drug Innovation and Pharmaceutical Industry Structure: Trends in The Output of Pharmaceutical FirmsminaBelum ada peringkat
- Crispr Cas 9 Gene EditingDokumen4 halamanCrispr Cas 9 Gene EditingminaBelum ada peringkat
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Safety and Immunogenicity of the Respiratory Syncytial Virus Vaccine RSV/ΔNS2/Δ1313/I1314L in RSV-Seronegative ChildrenDokumen10 halamanSafety and Immunogenicity of the Respiratory Syncytial Virus Vaccine RSV/ΔNS2/Δ1313/I1314L in RSV-Seronegative ChildrenminaBelum ada peringkat
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Crispr Cas 9 Gene EditingDokumen4 halamanCrispr Cas 9 Gene EditingminaBelum ada peringkat
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Innovating by Developing New Uses of Already-Approved Drugs: Trends in The Marketing Approval of Supplemental IndicationsDokumen11 halamanInnovating by Developing New Uses of Already-Approved Drugs: Trends in The Marketing Approval of Supplemental IndicationsminaBelum ada peringkat
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Computer Aided Drug Design Success and Limitations PDFDokumen10 halamanComputer Aided Drug Design Success and Limitations PDFminaBelum ada peringkat
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
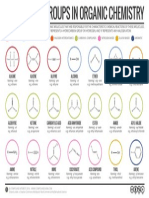
- Organic Functional Groups UpdateDokumen33 halamanOrganic Functional Groups UpdateminaBelum ada peringkat
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- How DNA Microarray WorksDokumen12 halamanHow DNA Microarray WorksminaBelum ada peringkat
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- Organic Functional GroupsDokumen1 halamanOrganic Functional GroupsCarolina MallamaBelum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Revision Notes Chemistry 2 CompleteDokumen11 halamanRevision Notes Chemistry 2 CompleteminaBelum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- TocDokumen4 halamanTocminaBelum ada peringkat
- How DNA Microarray Works PDFDokumen1 halamanHow DNA Microarray Works PDFminaBelum ada peringkat
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Safety Monitoring and Reporting in Clinical Trials NHMRC Nov2016 PDFDokumen27 halamanSafety Monitoring and Reporting in Clinical Trials NHMRC Nov2016 PDFminaBelum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- 2013 BPS Recertification GuideDokumen10 halaman2013 BPS Recertification GuideminaBelum ada peringkat
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Academic Word List - Sublist 4Dokumen4 halamanAcademic Word List - Sublist 4MarthaBelum ada peringkat
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- Academic Word List - Sublist 8Dokumen3 halamanAcademic Word List - Sublist 8pallavi agarwalBelum ada peringkat
- Revision Notes Chemistry 2 CompleteDokumen11 halamanRevision Notes Chemistry 2 CompleteminaBelum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Pharmacovigilance in Clinical Trials - PPTX FinalDokumen20 halamanPharmacovigilance in Clinical Trials - PPTX Finalmina100% (1)
- Metabolism of DisaccharidesDokumen15 halamanMetabolism of DisaccharidesminaBelum ada peringkat
- 15-2013 UTpt NephDokumen34 halaman15-2013 UTpt NephminaBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- 09-2013 UTpt EndoDokumen44 halaman09-2013 UTpt Endomina0% (1)
- 18-2013 UTpt Card01Dokumen48 halaman18-2013 UTpt Card01minaBelum ada peringkat
- Sierre Leone Guidelines For Medicinal PdtsDokumen20 halamanSierre Leone Guidelines For Medicinal PdtsminaBelum ada peringkat
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- PPC13 FacultyDokumen2 halamanPPC13 FacultyminaBelum ada peringkat
- Program Goals and Target AudienceDokumen1 halamanProgram Goals and Target AudienceminaBelum ada peringkat
- 9822 USP 1160 Pharm CalcDokumen12 halaman9822 USP 1160 Pharm Calcandreas hpBelum ada peringkat
- Medical Surgical Nursing Review NotesDokumen75 halamanMedical Surgical Nursing Review Notesstuffednurse92% (146)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (120)
- A To Z Drugs-2 PDFDokumen40 halamanA To Z Drugs-2 PDFMohamedYosef71% (7)
- Reliability of BiodexDokumen13 halamanReliability of BiodexMattBelum ada peringkat
- Solution Manual For A Second Course in Statistics Regression Analysis 8th Edition William Mendenhall Terry T SincichDokumen89 halamanSolution Manual For A Second Course in Statistics Regression Analysis 8th Edition William Mendenhall Terry T Sincichinfamousbunb100% (1)
- User Manual DASP Version 2.2: DASP: Distributive Analysis Stata PackageDokumen151 halamanUser Manual DASP Version 2.2: DASP: Distributive Analysis Stata PackagetarynaugustineBelum ada peringkat
- Sample Size CalculatorDokumen5 halamanSample Size CalculatorJoe BoustanyBelum ada peringkat
- Confidence IntervalDokumen20 halamanConfidence IntervalriganBelum ada peringkat
- Business Decision Making 2, Spring 2021: Practice Problems For Midterm ExamDokumen3 halamanBusiness Decision Making 2, Spring 2021: Practice Problems For Midterm ExamUyen ThuBelum ada peringkat
- Sample Size DeterminationDokumen19 halamanSample Size DeterminationGourav PatelBelum ada peringkat
- Answer: CDokumen16 halamanAnswer: CHʌɩɗɘʀ Aɭɩ100% (1)
- Limit of Detection Guidance DocumentDokumen33 halamanLimit of Detection Guidance DocumentMomer100% (1)
- Sampling Distributions, Estimation and Hypothesis Testing - Multiple Choice QuestionsDokumen6 halamanSampling Distributions, Estimation and Hypothesis Testing - Multiple Choice Questionsfafa salah100% (1)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Oral Contraceptives For Functional Ovarian Cysts (Review) : CochraneDokumen32 halamanOral Contraceptives For Functional Ovarian Cysts (Review) : CochraneAvneet KaurBelum ada peringkat
- London 2011 BoaDokumen154 halamanLondon 2011 Boaakita_1610Belum ada peringkat
- Estimation of Population MeanDokumen14 halamanEstimation of Population MeanAmartyaBelum ada peringkat
- 2022 Mathematical Methods Examination Paper 2Dokumen33 halaman2022 Mathematical Methods Examination Paper 2fefdesasdfaBelum ada peringkat
- Altekar Giacoletti NA17CESEP1 Process Validation Statistical Tool Overvi...Dokumen31 halamanAltekar Giacoletti NA17CESEP1 Process Validation Statistical Tool Overvi...Haroon RasheedBelum ada peringkat
- Research Methodology For BBS 4th YearDokumen41 halamanResearch Methodology For BBS 4th Yearchandra prakash khatriBelum ada peringkat
- Killing Me Softly Organizational E-Mail Monitoring Expectations' Impact On Employee and Significant Other Well-BeingDokumen29 halamanKilling Me Softly Organizational E-Mail Monitoring Expectations' Impact On Employee and Significant Other Well-BeingCarlosBelum ada peringkat
- Erdas Imagine Expert Classifier: Erdas, Inc. Atlanta, GeorgiaDokumen28 halamanErdas Imagine Expert Classifier: Erdas, Inc. Atlanta, GeorgiaJuvilcar AlbaceteBelum ada peringkat
- Effects of Mobilization, Stretching and Traction in Sports Professionals With Cervical Radiculopathies - For MergeDokumen20 halamanEffects of Mobilization, Stretching and Traction in Sports Professionals With Cervical Radiculopathies - For MergeVidya VS100% (1)
- Answer2 PDFDokumen16 halamanAnswer2 PDFarpitBelum ada peringkat
- Validation of Pharmaceutical ProcessesDokumen13 halamanValidation of Pharmaceutical ProcessesGULSHAN MADHURBelum ada peringkat
- Confidence Intervals For Variances and Standard DeviationsDokumen2 halamanConfidence Intervals For Variances and Standard DeviationsdurgaBelum ada peringkat
- PH.D Thesis M. UshaDokumen185 halamanPH.D Thesis M. UshaAdrian Serban100% (1)
- Calibration Laboratory Form Calibration of TankDokumen72 halamanCalibration Laboratory Form Calibration of TankericaBelum ada peringkat
- When To Use and How To Report The Results of PLS-SEM: Joseph F. HairDokumen23 halamanWhen To Use and How To Report The Results of PLS-SEM: Joseph F. HairSaifuddin HaswareBelum ada peringkat
- Iso 21748 2017 en PDFDokumen11 halamanIso 21748 2017 en PDFROBINBelum ada peringkat
- Waste and Waste Management: Standard Terminology ForDokumen18 halamanWaste and Waste Management: Standard Terminology ForFernanda MoralesBelum ada peringkat
- 538 PDFDokumen9 halaman538 PDFibnoliveirBelum ada peringkat
- Acceptance of COVID-19 Vaccination During The COVID-19 Pandemic in ChinaDokumen14 halamanAcceptance of COVID-19 Vaccination During The COVID-19 Pandemic in ChinaMark Nel NuñezBelum ada peringkat
- Tesis Doctoral Juan Jesus GutierrezDokumen193 halamanTesis Doctoral Juan Jesus GutierrezgayalamBelum ada peringkat
- The Body Keeps the Score by Bessel Van der Kolk, M.D. - Book Summary: Brain, Mind, and Body in the Healing of TraumaDari EverandThe Body Keeps the Score by Bessel Van der Kolk, M.D. - Book Summary: Brain, Mind, and Body in the Healing of TraumaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- Summary: Atomic Habits by James Clear: An Easy & Proven Way to Build Good Habits & Break Bad OnesDari EverandSummary: Atomic Habits by James Clear: An Easy & Proven Way to Build Good Habits & Break Bad OnesPenilaian: 5 dari 5 bintang5/5 (1635)
- The Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessDari EverandThe Compound Effect by Darren Hardy - Book Summary: Jumpstart Your Income, Your Life, Your SuccessPenilaian: 5 dari 5 bintang5/5 (456)
- Summary of The Anxious Generation by Jonathan Haidt: How the Great Rewiring of Childhood Is Causing an Epidemic of Mental IllnessDari EverandSummary of The Anxious Generation by Jonathan Haidt: How the Great Rewiring of Childhood Is Causing an Epidemic of Mental IllnessBelum ada peringkat
- The One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsDari EverandThe One Thing: The Surprisingly Simple Truth Behind Extraordinary ResultsPenilaian: 4.5 dari 5 bintang4.5/5 (709)
- The Whole-Brain Child by Daniel J. Siegel, M.D., and Tina Payne Bryson, PhD. - Book Summary: 12 Revolutionary Strategies to Nurture Your Child’s Developing MindDari EverandThe Whole-Brain Child by Daniel J. Siegel, M.D., and Tina Payne Bryson, PhD. - Book Summary: 12 Revolutionary Strategies to Nurture Your Child’s Developing MindPenilaian: 4.5 dari 5 bintang4.5/5 (57)
- Summary of 12 Rules for Life: An Antidote to ChaosDari EverandSummary of 12 Rules for Life: An Antidote to ChaosPenilaian: 4.5 dari 5 bintang4.5/5 (294)