Anda mungkin juga menyukai
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Interview Questions ExperiencesDokumen9 halamanInterview Questions ExperiencesPallav AnandBelum ada peringkat
- Machinelearningsalon Kit 28-12-2014Dokumen155 halamanMachinelearningsalon Kit 28-12-2014Vladimir PodshivalovBelum ada peringkat
- Case Interview Sample QuestionsDokumen2 halamanCase Interview Sample Questionssnaren77767% (3)
- Capital One PDFDokumen32 halamanCapital One PDFPallav AnandBelum ada peringkat
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDokumen33 halaman40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Churned A Matrix V 3Dokumen29 halamanChurned A Matrix V 3Pallav AnandBelum ada peringkat
- Churned A Matrix V 5Dokumen30 halamanChurned A Matrix V 5Pallav AnandBelum ada peringkat
- Churned A Matrix V 3Dokumen29 halamanChurned A Matrix V 3Pallav AnandBelum ada peringkat
- TX DL 2016Dokumen96 halamanTX DL 2016vreddy123Belum ada peringkat
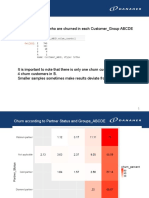
- No of Customers Who Are Churned in Each Customer - Group ABCDEDokumen27 halamanNo of Customers Who Are Churned in Each Customer - Group ABCDEPallav AnandBelum ada peringkat
- Resume Ahmed ZaidiDokumen2 halamanResume Ahmed ZaidiPallav AnandBelum ada peringkat
- Churned A Matrix V 3Dokumen29 halamanChurned A Matrix V 3Pallav AnandBelum ada peringkat
- Dates TimesDokumen12 halamanDates TimesPallav AnandBelum ada peringkat
- Data Processing With Dplyr TidyrDokumen25 halamanData Processing With Dplyr TidyrPallav AnandBelum ada peringkat
- Machine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Dokumen36 halamanMachine Learning and Data Mining: Prof. Alexander Ihler Fall 2012Pallav AnandBelum ada peringkat
- Artofdatascience PDFDokumen162 halamanArtofdatascience PDForchid21Belum ada peringkat
- Students As FormDokumen2 halamanStudents As FormPallav AnandBelum ada peringkat
- Lab 07Dokumen15 halamanLab 07Pallav AnandBelum ada peringkat
- Sanjay Natraj: Data Scientist/hadoop EngineerDokumen2 halamanSanjay Natraj: Data Scientist/hadoop EngineerPallav AnandBelum ada peringkat
- Biological NewDokumen5 halamanBiological NewPallav AnandBelum ada peringkat
- Caltrain Fares Effective 2-28-16113161316Dokumen1 halamanCaltrain Fares Effective 2-28-16113161316Pallav AnandBelum ada peringkat
- IsenDokumen4 halamanIsenPallav AnandBelum ada peringkat
- 3 2 Review Sampling, CIDokumen24 halaman3 2 Review Sampling, CIPallav AnandBelum ada peringkat
- Pallav ReportDokumen5 halamanPallav ReportPallav AnandBelum ada peringkat
- 6 Chi SquareDokumen3 halaman6 Chi SquarePallav AnandBelum ada peringkat
- 3.1 Hypothesis Testing (Critical Value Approach) : StatisticsDokumen3 halaman3.1 Hypothesis Testing (Critical Value Approach) : StatisticsPallav AnandBelum ada peringkat
- 4 HypoDokumen4 halaman4 HypoPallav AnandBelum ada peringkat
- 2 Hypo TestingDokumen4 halaman2 Hypo TestingPallav AnandBelum ada peringkat
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Manual IOL Master EN PDFDokumen8 halamanManual IOL Master EN PDFMirela MarinescuBelum ada peringkat
- Sexual Violence: A Feminist Criminological AnalysisDokumen25 halamanSexual Violence: A Feminist Criminological AnalysisBasant SoniBelum ada peringkat
- Chapter 3-Memory ManagementDokumen51 halamanChapter 3-Memory ManagementdsweetalkerBelum ada peringkat
- Lockpicking - Simplified PDFDokumen30 halamanLockpicking - Simplified PDFOtávio Camargo75% (4)
- Alarm MonitoringDokumen430 halamanAlarm Monitoringnnava5051Belum ada peringkat
- Mpu6 - Generic Horizon-manual-short-Form Issue 1.3 - No SafetyDokumen44 halamanMpu6 - Generic Horizon-manual-short-Form Issue 1.3 - No SafetyDean BurnsBelum ada peringkat
- Solid State Drive Forensics: Where Do We Stand?Dokumen16 halamanSolid State Drive Forensics: Where Do We Stand?Leunaidus ..Belum ada peringkat
- Unit-3 Lesson 4 Cyber SecurityDokumen15 halamanUnit-3 Lesson 4 Cyber Securitysreeharirpillai0805Belum ada peringkat
- Hackplanet Certified Metasploit Expert - Metasploit TrainingDokumen4 halamanHackplanet Certified Metasploit Expert - Metasploit TrainingShubham MittalBelum ada peringkat
- SOP for E-ProcurementDokumen20 halamanSOP for E-Procurementdillipsh123Belum ada peringkat
- Kingdom of Haven: Neverwinter Nights 2Dokumen82 halamanKingdom of Haven: Neverwinter Nights 2Justin WhittakerBelum ada peringkat
- Everything You Need to Know About Torrents for BeginnersDokumen10 halamanEverything You Need to Know About Torrents for BeginnersGeorge PalaBelum ada peringkat
- Grand Theft Auto San AndreasDokumen229 halamanGrand Theft Auto San AndreastechnosconeBelum ada peringkat
- Smex 10.0 sp1 AgDokumen376 halamanSmex 10.0 sp1 AgMickaelBelum ada peringkat
- Haker Arrives at Level 7 Deep WepDokumen16 halamanHaker Arrives at Level 7 Deep WepSelena MayorgaBelum ada peringkat
- What Is Cyber LawDokumen3 halamanWhat Is Cyber LawMayank GargBelum ada peringkat
- Strahlenfolter - TI - 9nania - My Story - Secret Tech, Mind Control & Other Weird Stuff - Playlist - YoutubeDokumen13 halamanStrahlenfolter - TI - 9nania - My Story - Secret Tech, Mind Control & Other Weird Stuff - Playlist - YoutubeTimo_KaehlkeBelum ada peringkat
- Emigration Clearance StepsDokumen36 halamanEmigration Clearance StepsMohamed ShafiBelum ada peringkat
- Andy Ramerez ABC15Dokumen1 halamanAndy Ramerez ABC15Eric NeitzelBelum ada peringkat
- How To Add Responsibility To USER Using PLDokumen3 halamanHow To Add Responsibility To USER Using PLVenkatesan RamamoorthyBelum ada peringkat
- JKPSC RecruitmentDokumen6 halamanJKPSC RecruitmentHiten BansalBelum ada peringkat
- NGX License GuideDokumen19 halamanNGX License GuideRiccardo TrazziBelum ada peringkat
- Ramboll Whit by Bird Remote VPN Access GuideDokumen6 halamanRamboll Whit by Bird Remote VPN Access Guidecarol_lewisBelum ada peringkat
- Network Security Using Image ProcessingDokumen5 halamanNetwork Security Using Image ProcessingnanokhanBelum ada peringkat
- Praveen Sir Hall Ticket 2018Dokumen1 halamanPraveen Sir Hall Ticket 2018Rajesh KannaBelum ada peringkat
- Computer Forensics - Past Present FutureDokumen15 halamanComputer Forensics - Past Present FutureGiovani ZandonaiBelum ada peringkat
- Timex Datalink USB ManualDokumen4 halamanTimex Datalink USB ManualkpkarlbomBelum ada peringkat
- 04 - Evidence Collection and Data SeizureDokumen7 halaman04 - Evidence Collection and Data SeizureKranthi Kumar ChBelum ada peringkat
- Indefinite Integral PartDokumen6 halamanIndefinite Integral PartSaisriram KarthikeyaBelum ada peringkat
- Similarly God Won't Give Problems Without SolutionsDokumen43 halamanSimilarly God Won't Give Problems Without Solutionsrh_rathodBelum ada peringkat