Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Document Forgery Detection Using Distortion Mutation of Geometric Parameters in CharactersDokumen14 halamanDocument Forgery Detection Using Distortion Mutation of Geometric Parameters in CharactersSweety ChaddhaBelum ada peringkat
- RPFs OldDokumen5 halamanRPFs OldSweety ChaddhaBelum ada peringkat
- Awareness of Voter Passion Greatly Improves Metric Social ChoiceDokumen34 halamanAwareness of Voter Passion Greatly Improves Metric Social ChoiceSweety ChaddhaBelum ada peringkat
- Modeling AGI Safety Frameworks With Causal Influence DiagramsDokumen12 halamanModeling AGI Safety Frameworks With Causal Influence DiagramsSweety ChaddhaBelum ada peringkat
- RPFsDokumen6 halamanRPFsSweety ChaddhaBelum ada peringkat
- Generic Ontology Design Patterns at Work: A B B A BDokumen12 halamanGeneric Ontology Design Patterns at Work: A B B A BSweety ChaddhaBelum ada peringkat
- RPFs OldDokumen5 halamanRPFs OldSweety ChaddhaBelum ada peringkat
- RahuDokumen6 halamanRahuSweety ChaddhaBelum ada peringkat
- Bayesian Modelling Improves Trust in Medical PredictionsDokumen7 halamanBayesian Modelling Improves Trust in Medical PredictionsSweety ChaddhaBelum ada peringkat
- All Params Tess4Dokumen27 halamanAll Params Tess4Sweety ChaddhaBelum ada peringkat
- HaikuDokumen2 halamanHaikuSweety ChaddhaBelum ada peringkat
- C Make ListsDokumen8 halamanC Make ListsSweety ChaddhaBelum ada peringkat
- Sales Report by Region, Rep, Item, and DateDokumen2 halamanSales Report by Region, Rep, Item, and DatenabayeelBelum ada peringkat
- Date Region Person Item Units Cost TotalDokumen1 halamanDate Region Person Item Units Cost TotalSweety ChaddhaBelum ada peringkat
- User Profiling Techniques:: A Comparative Study in The Context of E-Commerce WebsitesDokumen21 halamanUser Profiling Techniques:: A Comparative Study in The Context of E-Commerce WebsitesSweety ChaddhaBelum ada peringkat
- Employees SQLDokumen3 halamanEmployees SQLSweety ChaddhaBelum ada peringkat
- Bootstrap CheatsheetDokumen1 halamanBootstrap CheatsheetsvdmfgbcBelum ada peringkat
- GSA Request ResponseDokumen2 halamanGSA Request ResponseSweety ChaddhaBelum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- ICT G6 B2 Sheet1 FlowchartalgorithmDokumen7 halamanICT G6 B2 Sheet1 FlowchartalgorithmKarim ZahranBelum ada peringkat
- Last Push Physical Science Paper 2 Sep 2018Dokumen87 halamanLast Push Physical Science Paper 2 Sep 2018Mãbrïï Brïdgy XilumaneBelum ada peringkat
- Svi Secivil Dec14Dokumen2 halamanSvi Secivil Dec14Rahul BajajBelum ada peringkat
- Limit Load Analysis of Bolted Flange ConnectionsDokumen11 halamanLimit Load Analysis of Bolted Flange ConnectionsMansonBelum ada peringkat
- CK 12 Basic Algebra Concepts B v16 Jli s1Dokumen780 halamanCK 12 Basic Algebra Concepts B v16 Jli s1Phil Beckett100% (1)
- Shade Your Id Number. On The Orange BookletDokumen1 halamanShade Your Id Number. On The Orange BookletCharles AugustusBelum ada peringkat
- Taxomy and Evaluation of Primality Testing AlgorithmsDokumen21 halamanTaxomy and Evaluation of Primality Testing AlgorithmsMou LoudBelum ada peringkat
- 50 Mathematical Puzzles and OdditiesDokumen88 halaman50 Mathematical Puzzles and OdditiesmatijahajekBelum ada peringkat
- Chapter 3 - Stories Categorical Data TellDokumen15 halamanChapter 3 - Stories Categorical Data TellBryant BachelorBelum ada peringkat
- Unpacking PDFDokumen15 halamanUnpacking PDFNicole HernandezBelum ada peringkat
- Task Sheet #4 For Lesson 4 REMOROZA, DINNAH H.Dokumen4 halamanTask Sheet #4 For Lesson 4 REMOROZA, DINNAH H.dinnah100% (1)
- H2 MYE Revision Package Integration SolutionsDokumen9 halamanH2 MYE Revision Package Integration SolutionsTimothy HandokoBelum ada peringkat
- DM - 05 - 04 - Rule-Based Classification PDFDokumen72 halamanDM - 05 - 04 - Rule-Based Classification PDFMohamad ArifBelum ada peringkat
- The Islamia University of Bahawalpur: Faculty of Engineering & TechnologyDokumen5 halamanThe Islamia University of Bahawalpur: Faculty of Engineering & TechnologyBeenish HassanBelum ada peringkat
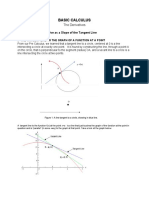
- Basic Calculus: Derivatives ExplainedDokumen25 halamanBasic Calculus: Derivatives ExplainedKrrje IBelum ada peringkat
- Electrical Engineering - Frame WorkDokumen10 halamanElectrical Engineering - Frame WorkMocharu ArtBelum ada peringkat
- Books For Reference FOR CSIR NET/JRF EXAMSDokumen3 halamanBooks For Reference FOR CSIR NET/JRF EXAMSjeganrajrajBelum ada peringkat
- Use The Substitution Method To Solve The Following SimultaneouslyDokumen3 halamanUse The Substitution Method To Solve The Following SimultaneouslyMartin MachezaBelum ada peringkat
- LectureDokumen35 halamanLectureSuvin NambiarBelum ada peringkat
- Demand System Estimation NewDokumen13 halamanDemand System Estimation NewGaurav JakhuBelum ada peringkat
- Stress-Strain Relations for Linear Elastic MaterialsDokumen5 halamanStress-Strain Relations for Linear Elastic MaterialsAditya AgrawalBelum ada peringkat
- Adilet Imambekov - Strongly Correlated Phenomena With Ultracold Atomic GasesDokumen200 halamanAdilet Imambekov - Strongly Correlated Phenomena With Ultracold Atomic GasesItama23Belum ada peringkat
- Seismic Analysis of Steel Storage Tanks, OverviewDokumen14 halamanSeismic Analysis of Steel Storage Tanks, OverviewRodolfo CBelum ada peringkat
- Christoph Reinhart: L12 Thermal Mass and Heat FlowDokumen64 halamanChristoph Reinhart: L12 Thermal Mass and Heat FlowT N Roland BourgeBelum ada peringkat
- Operations Research - MBA - 2nd SemDokumen225 halamanOperations Research - MBA - 2nd SemA.K.Praveen kumarBelum ada peringkat
- GRADE 3 KINDNESS Least Learned Skills in Mathematics2020 - 2021Dokumen2 halamanGRADE 3 KINDNESS Least Learned Skills in Mathematics2020 - 2021Ma88% (16)
- Physics 1C Midterm With SolutionDokumen9 halamanPhysics 1C Midterm With SolutionSarita DokaniaBelum ada peringkat
- ME 406 The Logistic Map: 1. IntroductionDokumen32 halamanME 406 The Logistic Map: 1. IntroductionsustrasBelum ada peringkat
- Ref 9 PDFDokumen10 halamanRef 9 PDFAli H. NumanBelum ada peringkat
- V Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1Dokumen152 halamanV Foreword VI Preface VII Authors' Profiles VIII Convention Ix Abbreviations X List of Tables Xi List of Figures Xii 1 1July Rodriguez100% (3)