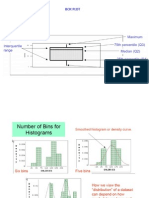
Anda mungkin juga menyukai
- Cold Storage Assignment Solution Ankur JainDokumen6 halamanCold Storage Assignment Solution Ankur JainAnkur Jain75% (8)
- Kuhn, Thomas - Copernican Revolution, The (Harvard, 1985) PDFDokumen159 halamanKuhn, Thomas - Copernican Revolution, The (Harvard, 1985) PDFLarissa Toledo83% (6)
- Tutorial 5Dokumen21 halamanTutorial 5ninglu wanBelum ada peringkat
- STA301 - Final Term Solved Subjective With Reference by MoaazDokumen28 halamanSTA301 - Final Term Solved Subjective With Reference by MoaazAdnan Khawaja61% (18)
- Hypothesis Testing: Two Populations: Learning ObjectivesDokumen23 halamanHypothesis Testing: Two Populations: Learning ObjectivesBENITEZ JOEL R.Belum ada peringkat
- PS2Dokumen2 halamanPS2Toulouse18Belum ada peringkat
- MidExam 6016201006 Muhammad Nahdi FebriansyahDokumen9 halamanMidExam 6016201006 Muhammad Nahdi FebriansyahJoseGonzalezRomeroBelum ada peringkat
- MA8452 PIT - by EasyEngineering - Net 2Dokumen74 halamanMA8452 PIT - by EasyEngineering - Net 2YUVARAJ YUVABelum ada peringkat
- Sunil Testing HypothesisDokumen39 halamanSunil Testing Hypothesisprayag DasBelum ada peringkat
- Hypothesis TestDokumen19 halamanHypothesis TestmalindaBelum ada peringkat
- 41 3 Tests Two SamplesDokumen22 halaman41 3 Tests Two SamplesvignanarajBelum ada peringkat
- Chapter10 StatsDokumen7 halamanChapter10 StatsPoonam NaiduBelum ada peringkat
- 2 Mean Hypothesis Tests With Sigma Unknown (2009)Dokumen4 halaman2 Mean Hypothesis Tests With Sigma Unknown (2009)Tin NguyenBelum ada peringkat
- Lecture 9Dokumen41 halamanLecture 9Dango QtrBelum ada peringkat
- ANOVA 1 F-RatioDokumen17 halamanANOVA 1 F-RatioHamza AsifBelum ada peringkat
- Tutorial 5Dokumen22 halamanTutorial 5Bake A DooBelum ada peringkat
- Chapter 13 Inference About Comparing Two Populations: QMDS 202 Data Analysis and ModelingDokumen9 halamanChapter 13 Inference About Comparing Two Populations: QMDS 202 Data Analysis and ModelingFaithBelum ada peringkat
- 202004032240235420anoop Singh Test of Significance For Large and Small SamplesDokumen8 halaman202004032240235420anoop Singh Test of Significance For Large and Small SamplesreenaBelum ada peringkat
- Lecture 9.0 - StatisticsDokumen39 halamanLecture 9.0 - StatisticsMohanad SulimanBelum ada peringkat
- Chi-Square, F-Tests & Analysis of Variance (Anova)Dokumen37 halamanChi-Square, F-Tests & Analysis of Variance (Anova)MohamedKijazyBelum ada peringkat
- M7L36Dokumen6 halamanM7L36abimanaBelum ada peringkat
- Hybrid Math 11 Stat Q1 M3 W3 V2Dokumen14 halamanHybrid Math 11 Stat Q1 M3 W3 V2L AlcosabaBelum ada peringkat
- ch8 4710Dokumen63 halamanch8 4710Leia SeunghoBelum ada peringkat
- PSet1 - Solnb SolutiondDokumen10 halamanPSet1 - Solnb Solutiondtest435345345Belum ada peringkat
- ScribeDokumen9 halamanScriberatesBelum ada peringkat
- Sta 305 HW 2Dokumen4 halamanSta 305 HW 2Jasmine NguyenBelum ada peringkat
- Unit 1Dokumen57 halamanUnit 1Ashok AmmaiyappanBelum ada peringkat
- I. Test of a Mean: σ unknown: X Z n Z N X t s n ttnDokumen12 halamanI. Test of a Mean: σ unknown: X Z n Z N X t s n ttnAli Arsalan SyedBelum ada peringkat
- Ae2223-II Exam 150414 FinalDokumen14 halamanAe2223-II Exam 150414 FinalAhmed Valentin KassemBelum ada peringkat
- Hypothesis Testing For Two Sample MeansDokumen17 halamanHypothesis Testing For Two Sample MeansShailja SinghBelum ada peringkat
- CHP Eight StatisticDokumen17 halamanCHP Eight StatisticFaris SyahmiBelum ada peringkat
- Lecture 3 - Statistical TestsDokumen35 halamanLecture 3 - Statistical Testscheta21Belum ada peringkat
- Estimation and Hypothesis Testing: Two Populations (PART 1)Dokumen46 halamanEstimation and Hypothesis Testing: Two Populations (PART 1)Sami Un BashirBelum ada peringkat
- MA8452 2M QB PIT - by WWW - Easyengineering.net 4Dokumen47 halamanMA8452 2M QB PIT - by WWW - Easyengineering.net 4YUVARAJ YUVABelum ada peringkat
- Sadia Ghafoor 1054 BS Chemistry 4 Morning Analytical Chemistry DR - Hussain Ullah Assignment: Chi Square and T Test Chi Square TestDokumen7 halamanSadia Ghafoor 1054 BS Chemistry 4 Morning Analytical Chemistry DR - Hussain Ullah Assignment: Chi Square and T Test Chi Square TestPirate 001Belum ada peringkat
- T-Test or Z-Test DecisionDokumen11 halamanT-Test or Z-Test Decisionkami_r202Belum ada peringkat
- IISER BiostatDokumen87 halamanIISER BiostatPrithibi Bodle GacheBelum ada peringkat
- Two Populations PDFDokumen16 halamanTwo Populations PDFdarwin_huaBelum ada peringkat
- Assignment 1Dokumen3 halamanAssignment 1Mitasha KapoorBelum ada peringkat
- Hypothesis Testing QuestionsDokumen20 halamanHypothesis Testing QuestionsAbhinav ShankarBelum ada peringkat
- 12.probstat - Ch12-Tes Hipotesis 2Dokumen45 halaman12.probstat - Ch12-Tes Hipotesis 2misterBelum ada peringkat
- Hypothesis Tests and Confidence Intervals in Multiple RegressionDokumen44 halamanHypothesis Tests and Confidence Intervals in Multiple RegressionRa'fat JalladBelum ada peringkat
- Point and Interval Estimation-26!08!2011Dokumen28 halamanPoint and Interval Estimation-26!08!2011Syed OvaisBelum ada peringkat
- ANOVADokumen6 halamanANOVAmisganabbbbbbbbbbBelum ada peringkat
- 2022 SUMATH3020 Day 14Dokumen3 halaman2022 SUMATH3020 Day 14Abby HorneBelum ada peringkat
- BES220 S2 Oct2022 - MemoDokumen8 halamanBES220 S2 Oct2022 - MemoSimphiwe BenyaBelum ada peringkat
- VarianceDokumen31 halamanVariancePashmeen KaurBelum ada peringkat
- Experimental Design I Lecture 6 070915Dokumen17 halamanExperimental Design I Lecture 6 070915Marlvin PrimeBelum ada peringkat
- Syllabus Ma 8452 - Statistics and Numerical MethodsDokumen48 halamanSyllabus Ma 8452 - Statistics and Numerical Methodstalha azanBelum ada peringkat
- Multiple Comparison Tests-1Dokumen45 halamanMultiple Comparison Tests-1Ali HassanBelum ada peringkat
- Directions: Read Carefully The Question and Choose The Best Answer On Each Item. Encircle YourDokumen3 halamanDirections: Read Carefully The Question and Choose The Best Answer On Each Item. Encircle YourFRANCHESKA MACATUNOBelum ada peringkat
- Lecture No.11Dokumen15 halamanLecture No.11Awais RaoBelum ada peringkat
- Readings For Lecture 5,: S S N N S NDokumen16 halamanReadings For Lecture 5,: S S N N S NSara BayedBelum ada peringkat
- Estimation HandoutDokumen7 halamanEstimation HandoutshanBelum ada peringkat
- Small Sample TestsDokumen10 halamanSmall Sample TestsJohn CarterBelum ada peringkat
- Econometrics ExamDokumen8 halamanEconometrics Examprnh88Belum ada peringkat
- Virtual Campaign Blue VariantDokumen28 halamanVirtual Campaign Blue VariantCELESTE HERNANDEZBelum ada peringkat
- Hypothesis Testing ClassDokumen14 halamanHypothesis Testing ClassLixia D.Belum ada peringkat
- Learn Statistics Fast: A Simplified Detailed Version for StudentsDari EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsBelum ada peringkat
- Performance Element Distinguished Proficient Intermediate MinimalDokumen1 halamanPerformance Element Distinguished Proficient Intermediate MinimalhabernardBelum ada peringkat
- Arma ModelDokumen15 halamanArma Modelpawan verma vermaBelum ada peringkat
- Personal Budget PlannerDokumen4 halamanPersonal Budget PlannerHendry Rao100% (1)
- Quiz 1Dokumen1 halamanQuiz 1habernardBelum ada peringkat
- Course Introduction and Basics of Interest TheoryDokumen19 halamanCourse Introduction and Basics of Interest TheoryhabernardBelum ada peringkat
- Practice 2Dokumen2 halamanPractice 2habernardBelum ada peringkat
- AMS HW3 ProblemsDokumen1 halamanAMS HW3 ProblemshabernardBelum ada peringkat
- Bastidas HW 4 Chap 2Dokumen5 halamanBastidas HW 4 Chap 2Jenifer Lopez SuarezBelum ada peringkat
- Cengage EBA 2e Chapter04Dokumen35 halamanCengage EBA 2e Chapter04joseBelum ada peringkat
- Research Aim: Holt-Winter's Method For Multiplicative SeasonalityDokumen8 halamanResearch Aim: Holt-Winter's Method For Multiplicative SeasonalityTwinkle ChoudharyBelum ada peringkat
- Ilac P10:01Dokumen49 halamanIlac P10:01Harold David Gil MuñozBelum ada peringkat
- Probability Sampling - According To BJYU's, It Utilizes Some Form of Random Selection. in ThisDokumen28 halamanProbability Sampling - According To BJYU's, It Utilizes Some Form of Random Selection. in ThisShiela Louisianne AbañoBelum ada peringkat
- Steps of ForecastingDokumen5 halamanSteps of ForecastingHashar RashidBelum ada peringkat
- Assignment 1 For MPH Weekend Students JinkaDokumen2 halamanAssignment 1 For MPH Weekend Students JinkaEleni H100% (1)
- CAPE Applied Mathematics 2008 U1 P032 TTDokumen5 halamanCAPE Applied Mathematics 2008 U1 P032 TTIdris SegulamBelum ada peringkat
- 1.3. The Analytical ProcessDokumen14 halaman1.3. The Analytical ProcessJohn LopezBelum ada peringkat
- Business Logic ReviewerDokumen17 halamanBusiness Logic Reviewerlanz kristoff rachoBelum ada peringkat
- Business Research Methods, OXFORD University Press, ISBN: 978 983 47074 77Dokumen5 halamanBusiness Research Methods, OXFORD University Press, ISBN: 978 983 47074 77MOHAMED rabei ahmedBelum ada peringkat
- UpgradDokumen8 halamanUpgradLata SurajBelum ada peringkat
- Research 2: Ms. Mariecor C. BalberDokumen31 halamanResearch 2: Ms. Mariecor C. BalberMariecorBelum ada peringkat
- Running Head: Experimental and Ex Post Facto Design 1Dokumen19 halamanRunning Head: Experimental and Ex Post Facto Design 1anne leeBelum ada peringkat
- President Ramon Magsaysay State UniversityDokumen11 halamanPresident Ramon Magsaysay State UniversityIratusGlennCruzBelum ada peringkat
- WiproDokumen21 halamanWiproJatinBelum ada peringkat
- Weber and Ancient Judaism PDFDokumen25 halamanWeber and Ancient Judaism PDFdennistrilloBelum ada peringkat
- Lecture 8Dokumen27 halamanLecture 8Kimberly BalinBelum ada peringkat
- Sr38 Lean AccountingDokumen24 halamanSr38 Lean AccountingYurisdal Bowie AzwanBelum ada peringkat
- Pengaruh Advertising, Brand Awareness Dan Brand Trust Terhadap Keputusan Pembelian Produk Merek Make Over (Studi Pada Mahasiswa FEB UM Metro) Gendhis Haningkas Tinika Dewi, FitrianiDokumen13 halamanPengaruh Advertising, Brand Awareness Dan Brand Trust Terhadap Keputusan Pembelian Produk Merek Make Over (Studi Pada Mahasiswa FEB UM Metro) Gendhis Haningkas Tinika Dewi, FitrianiDwie Rizky RachmadaniBelum ada peringkat
- Thesis Data Analysis SectionDokumen5 halamanThesis Data Analysis Sectioniinlutvff100% (2)
- PHYSICSDokumen11 halamanPHYSICSZenil MehtaBelum ada peringkat
- Sample Size Calculation: H.E. Misiri PHD in BiostatisticsDokumen32 halamanSample Size Calculation: H.E. Misiri PHD in BiostatisticsHumphrey MisiriBelum ada peringkat
- GAF 530: Statistics For Risk and Decision Making Course ObjectivesDokumen2 halamanGAF 530: Statistics For Risk and Decision Making Course ObjectivesLombe Mutono100% (1)
- ANOVA Model With One Qualitative VariableDokumen4 halamanANOVA Model With One Qualitative Variablesukma aliBelum ada peringkat
- CMN 102 Manual Fall 2010Dokumen208 halamanCMN 102 Manual Fall 2010Tiffany LiouBelum ada peringkat
- Dynamic Panel DataDokumen51 halamanDynamic Panel DataSERGIO REQUENABelum ada peringkat
- Msa 1 10Dokumen31 halamanMsa 1 10MahendraBelum ada peringkat