Anda mungkin juga menyukai
- Observability at Twitter - Technical Overview, Part I - Twitter BlogsDokumen7 halamanObservability at Twitter - Technical Overview, Part I - Twitter BlogsFinigan JoyceBelum ada peringkat
- Developing Dynamic Reports Using Rich Internet ApplicationsDokumen10 halamanDeveloping Dynamic Reports Using Rich Internet Applicationsalia_684Belum ada peringkat
- Hackathon Problem StatementDokumen3 halamanHackathon Problem StatementhasibBelum ada peringkat
- Big Data, Machine Learning Shape Performance-Monitoring DevelopmentsDokumen5 halamanBig Data, Machine Learning Shape Performance-Monitoring DevelopmentsDxtr MedinaBelum ada peringkat
- Revised Developer Tools ProposalDokumen9 halamanRevised Developer Tools ProposalNate LindstromBelum ada peringkat
- 1.1 Industrial IotDokumen21 halaman1.1 Industrial IotRithu Reddy VBelum ada peringkat
- Analytic Applications - Part 1Dokumen66 halamanAnalytic Applications - Part 1Koppala ObulreddyBelum ada peringkat
- Application Performance Measurement and Analysis Made Easier and More AutomaticDokumen4 halamanApplication Performance Measurement and Analysis Made Easier and More Automaticscribd-itBelum ada peringkat
- K Analytics Design DocDokumen9 halamanK Analytics Design DocVimal BahugunaBelum ada peringkat
- What Is An Adapter?: Publication ServiceDokumen5 halamanWhat Is An Adapter?: Publication ServicejsriramyaBelum ada peringkat
- Colloquium 2018IMG066Dokumen23 halamanColloquium 2018IMG066Tushar Guha NeogiBelum ada peringkat
- A Concise Guide to Microservices for Executive (Now for DevOps too!)Dari EverandA Concise Guide to Microservices for Executive (Now for DevOps too!)Penilaian: 1 dari 5 bintang1/5 (1)
- Oracle Real User Experience Insight: An Oracle White Paper September, 2011Dokumen15 halamanOracle Real User Experience Insight: An Oracle White Paper September, 2011Rohit MishraBelum ada peringkat
- Migrating Lotus Notes Applications To Google AppsDokumen7 halamanMigrating Lotus Notes Applications To Google AppsAuliya SantBelum ada peringkat
- DocumentationDokumen96 halamanDocumentationonly leds (Only LED's)Belum ada peringkat
- Ab Initio CapabilitiesDokumen6 halamanAb Initio CapabilitiesLuis YañezBelum ada peringkat
- Waterfall: 1. To Study About Identify The Development Model For Software With Proper ExplanationDokumen23 halamanWaterfall: 1. To Study About Identify The Development Model For Software With Proper ExplanationgreninjaBelum ada peringkat
- Assmnt2phase1 SoftwarearchitectureDokumen26 halamanAssmnt2phase1 Softwarearchitectureapi-283791392Belum ada peringkat
- LabVIEW For Measurement and Data AnalysisDokumen9 halamanLabVIEW For Measurement and Data Analysismikeiancu20023934Belum ada peringkat
- Web Server Log AnalyzerDokumen12 halamanWeb Server Log Analyzerudhayasurya786Belum ada peringkat
- 5 Questions To Ask Before Opting For A Business IntelligenceDokumen8 halaman5 Questions To Ask Before Opting For A Business IntelligenceRaghav MittalBelum ada peringkat
- Project Synopsis SampleDokumen11 halamanProject Synopsis SampleVaibhav SinghBelum ada peringkat
- Collaboration Analytics: Implementation GuideDokumen7 halamanCollaboration Analytics: Implementation GuideChaurasiaVBelum ada peringkat
- Architecting A MachineDokumen23 halamanArchitecting A MachineEd CherBelum ada peringkat
- Project Proposal ON Department Store Management Information SystemDokumen12 halamanProject Proposal ON Department Store Management Information Systemgamdias321Belum ada peringkat
- Ebook GuideToOpenTelemetryDokumen17 halamanEbook GuideToOpenTelemetryDavid UzielBelum ada peringkat
- S4: Distributed Stream Computing PlatformDokumen8 halamanS4: Distributed Stream Computing PlatformOtávio CarvalhoBelum ada peringkat
- Online Banking System Implementing J2EE and SOADokumen27 halamanOnline Banking System Implementing J2EE and SOAhaskinsdBelum ada peringkat
- Business Intelligence: Business Intelligence Tools Business Intelligence Uses Business Intelligence NewsDokumen6 halamanBusiness Intelligence: Business Intelligence Tools Business Intelligence Uses Business Intelligence NewsRaghav PrabhuBelum ada peringkat
- Mule Core ComponentsDokumen7 halamanMule Core ComponentsRameshChBelum ada peringkat
- Final Year Proposal On 24 Hours News PortalDokumen15 halamanFinal Year Proposal On 24 Hours News Portalprince of_darkness75% (16)
- Aadhar PDFDokumen32 halamanAadhar PDFMahesh SabuBelum ada peringkat
- IBM® Tivoli® Software: Document Version 4Dokumen50 halamanIBM® Tivoli® Software: Document Version 4RajMohenBelum ada peringkat
- Performance Report System (PRS)Dokumen61 halamanPerformance Report System (PRS)naveedalisha100% (10)
- VCX RFP InfoDokumen37 halamanVCX RFP Infoapi-3830335Belum ada peringkat
- Tibco Spot Miner 8.2 UguideDokumen756 halamanTibco Spot Miner 8.2 UguideikeyadaBelum ada peringkat
- RefCardz - Getting Started With MicroservicesDokumen6 halamanRefCardz - Getting Started With MicroservicesajulienBelum ada peringkat
- A Developer's Guide To Lift-And-Shift Cloud Migration: DetailDokumen17 halamanA Developer's Guide To Lift-And-Shift Cloud Migration: DetailAlex ValenciaBelum ada peringkat
- Application Services GovernanceDokumen9 halamanApplication Services GovernancejhampiaBelum ada peringkat
- Silverlight Based Interface To Bing: MM - Dd.yyyy 0.1.0Dokumen9 halamanSilverlight Based Interface To Bing: MM - Dd.yyyy 0.1.0Manjula AshokBelum ada peringkat
- Jurnal Integrasi Aplikasi PerusahaanDokumen8 halamanJurnal Integrasi Aplikasi PerusahaanMadani RahmatullahBelum ada peringkat
- 04 Resource MonitoringDokumen35 halaman04 Resource Monitoringkanedakodama100% (1)
- TIBCO BusinessEvents - A Powerful Tool For Complex Event ProcessingDokumen3 halamanTIBCO BusinessEvents - A Powerful Tool For Complex Event Processingkrishna vengalasettyBelum ada peringkat
- S A AS - C S B: (Saas-Csb)Dokumen6 halamanS A AS - C S B: (Saas-Csb)John BergBelum ada peringkat
- Google Web VitalsDokumen8 halamanGoogle Web VitalsbuenamusicainfoBelum ada peringkat
- ITC 251 Lab Assessments 2 Answers Part 1 Report WritingDokumen4 halamanITC 251 Lab Assessments 2 Answers Part 1 Report WritingThunder BoltBelum ada peringkat
- Reporting ToolsDokumen7 halamanReporting ToolsShakhir MohunBelum ada peringkat
- Software Requirements Specification: I. Table of ContentsDokumen19 halamanSoftware Requirements Specification: I. Table of ContentsNikolay GrybeniukBelum ada peringkat
- Productionizing ML With Workflows at TwitterDokumen11 halamanProductionizing ML With Workflows at TwitterFinigan JoyceBelum ada peringkat
- Software Requirements TraceabilityDokumen20 halamanSoftware Requirements TraceabilityKishore ChittellaBelum ada peringkat
- Billing System Mini Project.1Dokumen11 halamanBilling System Mini Project.1mahikpc3Belum ada peringkat
- Analysis of Log Data and Statistics Report Generation Using HadoopDokumen5 halamanAnalysis of Log Data and Statistics Report Generation Using HadoopPradipsinh ChavdaBelum ada peringkat
- Development of Effort Tracking SystemDokumen27 halamanDevelopment of Effort Tracking SystemAditi BhateBelum ada peringkat
- SAP BO Reporting and Analysis Applications SAP BO Reporting and Analysis ApplicationsDokumen43 halamanSAP BO Reporting and Analysis Applications SAP BO Reporting and Analysis ApplicationsKiran KumarBelum ada peringkat
- NI Tutorial 3062 enDokumen4 halamanNI Tutorial 3062 enkmBelum ada peringkat
- ProspDokumen14 halamanProspAbdo FuadBelum ada peringkat
- Using Rapid Prototyping To Develop A Data MartDokumen7 halamanUsing Rapid Prototyping To Develop A Data MartfernandojhBelum ada peringkat
- Efficient Multi Vendor Services For Field Based Service: AbstractDokumen5 halamanEfficient Multi Vendor Services For Field Based Service: AbstractInternational Journal of Engineering and TechniquesBelum ada peringkat
- Knight's Microsoft Business Intelligence 24-Hour Trainer: Leveraging Microsoft SQL Server Integration, Analysis, and Reporting Services with Excel and SharePointDari EverandKnight's Microsoft Business Intelligence 24-Hour Trainer: Leveraging Microsoft SQL Server Integration, Analysis, and Reporting Services with Excel and SharePointPenilaian: 3 dari 5 bintang3/5 (1)
- How To Build Microservices: Top 10 Hacks To Modeling, Integrating & Deploying Microservices: The Blokehead Success SeriesDari EverandHow To Build Microservices: Top 10 Hacks To Modeling, Integrating & Deploying Microservices: The Blokehead Success SeriesPenilaian: 1 dari 5 bintang1/5 (1)
- Integrated Data Management System For Data Center: Debasis Dash, Juthika Dash, Younghee Park, Jerry GaoDokumen6 halamanIntegrated Data Management System For Data Center: Debasis Dash, Juthika Dash, Younghee Park, Jerry GaoFinigan JoyceBelum ada peringkat
- Tslearn, A Machine Learning Toolkit For Time Series Data: January 2020Dokumen8 halamanTslearn, A Machine Learning Toolkit For Time Series Data: January 2020Finigan JoyceBelum ada peringkat
- Searching For Correlations in Simultaneous X-Ray and UV Emission in The Narrow-Line Seyfert 1 Galaxy 1H 0707 (495Dokumen8 halamanSearching For Correlations in Simultaneous X-Ray and UV Emission in The Narrow-Line Seyfert 1 Galaxy 1H 0707 (495Finigan JoyceBelum ada peringkat
- Productionizing ML With Workflows at TwitterDokumen11 halamanProductionizing ML With Workflows at TwitterFinigan JoyceBelum ada peringkat
- Benchmarking Apache Kafka - 2 Million Writes Per Second (On Three Cheap Machines) - LinkedIn EngineeringDokumen9 halamanBenchmarking Apache Kafka - 2 Million Writes Per Second (On Three Cheap Machines) - LinkedIn EngineeringFinigan JoyceBelum ada peringkat
- Mining Multivariate Time Series With Mixed Sampling RatesDokumen11 halamanMining Multivariate Time Series With Mixed Sampling RatesFinigan JoyceBelum ada peringkat
- A Temperature Control For Plastic Extruder Used Fuzzy Genetic AlgorithmsDokumen7 halamanA Temperature Control For Plastic Extruder Used Fuzzy Genetic AlgorithmsFinigan JoyceBelum ada peringkat
- 2013 Arduino PID Lab 0Dokumen7 halaman2013 Arduino PID Lab 0Uma MageshwariBelum ada peringkat
- Datacenter RFP PDFDokumen49 halamanDatacenter RFP PDFabeba100% (1)
- Buyers Guide MESDokumen22 halamanBuyers Guide MESscribdjh100% (2)
- Akka IO (Java)Dokumen8 halamanAkka IO (Java)Finigan JoyceBelum ada peringkat
- Creating An SVG File With D3 and NodeDokumen3 halamanCreating An SVG File With D3 and NodeFinigan JoyceBelum ada peringkat
- Ambari BasicsDokumen2 halamanAmbari BasicsFinigan JoyceBelum ada peringkat
- Next-Generation Information Analytics: IDOL 10: Built For The Era of Big DataDokumen8 halamanNext-Generation Information Analytics: IDOL 10: Built For The Era of Big DataFinigan JoyceBelum ada peringkat
- 1600 Column Limit Per TableDokumen3 halaman1600 Column Limit Per TableFinigan JoyceBelum ada peringkat
- Building and Running ManifoldCFDokumen17 halamanBuilding and Running ManifoldCFFinigan JoyceBelum ada peringkat
- This Year's MODEL - Process Engineering (DOP)Dokumen4 halamanThis Year's MODEL - Process Engineering (DOP)Finigan JoyceBelum ada peringkat
- PostgreSQL Update Internals - JeremiahDokumen6 halamanPostgreSQL Update Internals - JeremiahFinigan JoyceBelum ada peringkat
- RAMI 4.0: An Architectural Model For Industrie 4.0Dokumen31 halamanRAMI 4.0: An Architectural Model For Industrie 4.0Finigan JoyceBelum ada peringkat
- MSC 72 NameCardDokumen3 halamanMSC 72 NameCardFinigan JoyceBelum ada peringkat
- (轉貼) 常用英文商業書信大全(做外貿必看) at Kelvin的Blog記事本 - - 痞客邦 PIXNET - -Dokumen9 halaman(轉貼) 常用英文商業書信大全(做外貿必看) at Kelvin的Blog記事本 - - 痞客邦 PIXNET - -Finigan JoyceBelum ada peringkat
- Brent OptimizationDokumen8 halamanBrent OptimizationFinigan JoyceBelum ada peringkat
- Dynamic Modeling and Gain Scheduling Control of A Chilled Water Cooling System (Thesis)Dokumen125 halamanDynamic Modeling and Gain Scheduling Control of A Chilled Water Cooling System (Thesis)Finigan JoyceBelum ada peringkat
- Flash Calculations Using The Soave-Redlich-Kwong Equation of State - File Exchange - MATLAB CentralDokumen2 halamanFlash Calculations Using The Soave-Redlich-Kwong Equation of State - File Exchange - MATLAB CentralFinigan JoyceBelum ada peringkat
- Intro Che Thermodynamics Computer Program DownloadDokumen2 halamanIntro Che Thermodynamics Computer Program DownloadFinigan JoyceBelum ada peringkat
- t34 13Dokumen10 halamant34 13Finigan JoyceBelum ada peringkat
- Nasa - T-MATS GitHubDokumen2 halamanNasa - T-MATS GitHubFinigan JoyceBelum ada peringkat
- 45-TQM in Indian Service Sector PDFDokumen16 halaman45-TQM in Indian Service Sector PDFsharan chakravarthyBelum ada peringkat
- Supermarkets - UK - November 2015 - Executive SummaryDokumen8 halamanSupermarkets - UK - November 2015 - Executive Summarymaxime78540Belum ada peringkat
- Santos vs. Reyes: VOL. 368, OCTOBER 25, 2001 261Dokumen13 halamanSantos vs. Reyes: VOL. 368, OCTOBER 25, 2001 261Aaron CariñoBelum ada peringkat
- To The Lighthouse To The SelfDokumen36 halamanTo The Lighthouse To The SelfSubham GuptaBelum ada peringkat
- Appleby, Telling The Truth About History, Introduction and Chapter 4Dokumen24 halamanAppleby, Telling The Truth About History, Introduction and Chapter 4Steven LubarBelum ada peringkat
- FINAL-Ordinance B.tech - 1Dokumen12 halamanFINAL-Ordinance B.tech - 1Utkarsh PathakBelum ada peringkat
- Price ReferenceDokumen2 halamanPrice Referencemay ann rodriguezBelum ada peringkat
- TallyDokumen70 halamanTallyShree GuruBelum ada peringkat
- OD428150379753135100Dokumen1 halamanOD428150379753135100Sourav SantraBelum ada peringkat
- Unit 1 PDFDokumen5 halamanUnit 1 PDFaadhithiyan nsBelum ada peringkat
- Module 7: Storm Over El Filibusterismo: ObjectivesDokumen7 halamanModule 7: Storm Over El Filibusterismo: ObjectivesJanelle PedreroBelum ada peringkat
- PERDEV2Dokumen7 halamanPERDEV2Riza Mae GardoseBelum ada peringkat
- Matalam V Sandiganbayan - JasperDokumen3 halamanMatalam V Sandiganbayan - JasperJames LouBelum ada peringkat
- Swot MerckDokumen3 halamanSwot Mercktomassetya0% (1)
- Mock Act 1 - Student - 2023Dokumen8 halamanMock Act 1 - Student - 2023Big bundahBelum ada peringkat
- Tok SB Ibdip Ch1Dokumen16 halamanTok SB Ibdip Ch1Luis Andrés Arce SalazarBelum ada peringkat
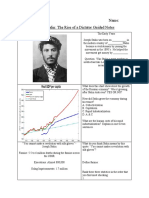
- Stalin Guided NotesDokumen2 halamanStalin Guided Notesapi-536892868Belum ada peringkat
- SIP Annex 5 - Planning WorksheetDokumen2 halamanSIP Annex 5 - Planning WorksheetGem Lam SenBelum ada peringkat
- Witherby Connect User ManualDokumen14 halamanWitherby Connect User ManualAshish NayyarBelum ada peringkat
- People vs. Tampus DigestDokumen2 halamanPeople vs. Tampus Digestcmv mendozaBelum ada peringkat
- Tucker Travis-Reel Site 2013-1Dokumen2 halamanTucker Travis-Reel Site 2013-1api-243050578Belum ada peringkat
- Test 5Dokumen4 halamanTest 5Lam ThúyBelum ada peringkat
- RPA Solutions - Step Into The FutureDokumen13 halamanRPA Solutions - Step Into The FutureThe Poet Inside youBelum ada peringkat
- House Tax Assessment Details PDFDokumen1 halamanHouse Tax Assessment Details PDFSatyaBelum ada peringkat
- Aircraft FatigueDokumen1 halamanAircraft FatigueSharan RajBelum ada peringkat
- Acknowledgment, Dedication, Curriculum Vitae - Lanie B. BatoyDokumen3 halamanAcknowledgment, Dedication, Curriculum Vitae - Lanie B. BatoyLanie BatoyBelum ada peringkat
- Colville GenealogyDokumen7 halamanColville GenealogyJeff MartinBelum ada peringkat
- Parent Leaflet Child Death Review v2Dokumen24 halamanParent Leaflet Child Death Review v2InJailOutSoonBelum ada peringkat
- SUDAN A Country StudyDokumen483 halamanSUDAN A Country StudyAlicia Torija López Carmona Verea100% (1)
- Basic Fortigate Firewall Configuration: Content at A GlanceDokumen17 halamanBasic Fortigate Firewall Configuration: Content at A GlanceDenisa PriftiBelum ada peringkat