Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- DFo 2 1Dokumen15 halamanDFo 2 1Donna HernandezBelum ada peringkat
- Organic Chemistry 1Dokumen265 halamanOrganic Chemistry 1Israk Mustakim IslamBelum ada peringkat
- ReviewsDokumen1 halamanReviewsa_44mBelum ada peringkat
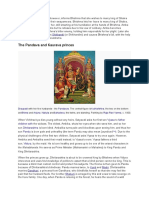
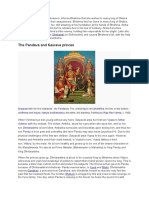
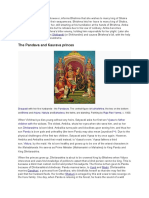
- The Pandava and Kaurava Princes: Drupada Shikhandi ArjunaDokumen4 halamanThe Pandava and Kaurava Princes: Drupada Shikhandi Arjunaa_44mBelum ada peringkat
- The Pandava and Kaurava Princes: Drupada Shikhandi ArjunaDokumen2 halamanThe Pandava and Kaurava Princes: Drupada Shikhandi Arjunaa_44mBelum ada peringkat
- The Pandava and Kaurava Princes: Drupada Shikhandi ArjunaDokumen2 halamanThe Pandava and Kaurava Princes: Drupada Shikhandi Arjunaa_44mBelum ada peringkat
- The Pandava and Kaurava Princes: Drupada Shikhandi ArjunaDokumen1 halamanThe Pandava and Kaurava Princes: Drupada Shikhandi Arjunaa_44mBelum ada peringkat
- Drupada Shikhandi ArjunaDokumen1 halamanDrupada Shikhandi Arjunaa_44mBelum ada peringkat
- NumerologyDokumen10 halamanNumerologya_44mBelum ada peringkat
- NumerologyDokumen6 halamanNumerologya_44mBelum ada peringkat
- Sankranthi PDFDokumen39 halamanSankranthi PDFMaruthiBelum ada peringkat
- Derebe TekesteDokumen75 halamanDerebe TekesteAbinet AdemaBelum ada peringkat
- Draft PDFDokumen166 halamanDraft PDFashwaq000111Belum ada peringkat
- 1995 Biology Paper I Marking SchemeDokumen13 halaman1995 Biology Paper I Marking Schemetramysss100% (2)
- C4 Vectors - Vector Lines PDFDokumen33 halamanC4 Vectors - Vector Lines PDFMohsin NaveedBelum ada peringkat
- EN 50122-1 January 2011 Corrientes RetornoDokumen81 halamanEN 50122-1 January 2011 Corrientes RetornoConrad Ziebold VanakenBelum ada peringkat
- Union Test Prep Nclex Study GuideDokumen115 halamanUnion Test Prep Nclex Study GuideBradburn Nursing100% (2)
- 1916 South American Championship Squads - WikipediaDokumen6 halaman1916 South American Championship Squads - WikipediaCristian VillamayorBelum ada peringkat
- Understanding PTS Security PDFDokumen37 halamanUnderstanding PTS Security PDFNeon LogicBelum ada peringkat
- Open Letter To Hon. Nitin Gadkari On Pothole Problem On National and Other Highways in IndiaDokumen3 halamanOpen Letter To Hon. Nitin Gadkari On Pothole Problem On National and Other Highways in IndiaProf. Prithvi Singh KandhalBelum ada peringkat
- Knee JointDokumen28 halamanKnee JointRaj Shekhar Singh100% (1)
- Final Selection Criteria Tunnel Cons TraDokumen32 halamanFinal Selection Criteria Tunnel Cons TraMd Mobshshir NayeemBelum ada peringkat
- Hydraulic Mining ExcavatorDokumen8 halamanHydraulic Mining Excavatorasditia_07100% (1)
- Matka Queen Jaya BhagatDokumen1 halamanMatka Queen Jaya BhagatA.K.A. Haji100% (4)
- Final WMS2023 HairdressingDokumen15 halamanFinal WMS2023 HairdressingMIRAWATI SAHIBBelum ada peringkat
- Manual For Tacho Universal Edition 2006: Legal DisclaimerDokumen9 halamanManual For Tacho Universal Edition 2006: Legal DisclaimerboirxBelum ada peringkat
- Individual Career Plan: DIRECTIONS: Answer The Following Questions in Paragraph Form (3-4 Sentences) Per QuestionDokumen2 halamanIndividual Career Plan: DIRECTIONS: Answer The Following Questions in Paragraph Form (3-4 Sentences) Per Questionapi-526813290Belum ada peringkat
- Analytical Chem Lab #3Dokumen4 halamanAnalytical Chem Lab #3kent galangBelum ada peringkat
- Blockchains: Architecture, Design and Use CasesDokumen26 halamanBlockchains: Architecture, Design and Use Caseseira kBelum ada peringkat
- Conservation Assignment 02Dokumen16 halamanConservation Assignment 02RAJU VENKATABelum ada peringkat
- Chemistry Investigatory Project (R)Dokumen23 halamanChemistry Investigatory Project (R)BhagyashreeBelum ada peringkat
- RMC 102-2017 HighlightsDokumen3 halamanRMC 102-2017 HighlightsmmeeeowwBelum ada peringkat
- Civ Beyond Earth HotkeysDokumen1 halamanCiv Beyond Earth HotkeysExirtisBelum ada peringkat
- Pipe Cleaner Lesson PlanDokumen2 halamanPipe Cleaner Lesson PlanTaylor FranklinBelum ada peringkat
- Trade MarkDokumen2 halamanTrade MarkRohit ThoratBelum ada peringkat
- TFGDokumen46 halamanTFGAlex Gigena50% (2)
- Lesson Plan For Implementing NETSDokumen5 halamanLesson Plan For Implementing NETSLisa PizzutoBelum ada peringkat
- Electronic Spin Inversion: A Danger To Your HealthDokumen4 halamanElectronic Spin Inversion: A Danger To Your Healthambertje12Belum ada peringkat