Anda mungkin juga menyukai
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Clustering With Multiviewpoint-BasedDokumen6 halamanClustering With Multiviewpoint-BasedSuveetha SuviBelum ada peringkat
- DFDSFSDFDokumen1 halamanDFDSFSDFSuveetha SuviBelum ada peringkat
- A Secure Erasure Code-Based Cloud Storage System With Secure Data ForwardingDokumen13 halamanA Secure Erasure Code-Based Cloud Storage System With Secure Data ForwardingJAYAPRAKASHBelum ada peringkat
- Effective Pattern Discovery For Text MiningDokumen8 halamanEffective Pattern Discovery For Text MiningJAYAPRAKASHBelum ada peringkat
- Cloud Computing Security From Single To Multi-CloudsDokumen8 halamanCloud Computing Security From Single To Multi-CloudsJAYAPRAKASHBelum ada peringkat
- A Gossip Protocol For Dynamic Resource Management in Large Cloud EnvironmentsDokumen10 halamanA Gossip Protocol For Dynamic Resource Management in Large Cloud EnvironmentsJAYAPRAKASHBelum ada peringkat
- A Privacy-Preserving Location Monitoring System For Wireless Sensor NetworksDokumen33 halamanA Privacy-Preserving Location Monitoring System For Wireless Sensor NetworksSuveetha SuviBelum ada peringkat
- EduCloud PaaS Versus IaaS Cloud UsageDokumen2 halamanEduCloud PaaS Versus IaaS Cloud UsageSuveetha SuviBelum ada peringkat
- Bootstrapping Ontologies For Web ServicesDokumen8 halamanBootstrapping Ontologies For Web ServicesSuveetha SuviBelum ada peringkat
- New DocumentDokumen68 halamanNew DocumentSuveetha SuviBelum ada peringkat
- Cut Detection in Wireless Sensor NetworksDokumen6 halamanCut Detection in Wireless Sensor NetworksSuveetha SuviBelum ada peringkat
- 2909autonomous Mobile Mesh NetworksDokumen6 halaman2909autonomous Mobile Mesh NetworksSuveetha SuviBelum ada peringkat
- A Novel Data Embedding Method Using AdaptiveDokumen7 halamanA Novel Data Embedding Method Using AdaptiveSuveetha SuviBelum ada peringkat
- New DocumentDokumen68 halamanNew DocumentSuveetha SuviBelum ada peringkat
- NEW123Dokumen1 halamanNEW123Suveetha SuviBelum ada peringkat
- Solar Water Purification by Thermal MethodeDokumen5 halamanSolar Water Purification by Thermal MethodeSuveetha SuviBelum ada peringkat
- Student Information ManagementDokumen8 halamanStudent Information ManagementSuveetha SuviBelum ada peringkat
- Ai and Opinion MiningDokumen5 halamanAi and Opinion Miningfriendz675Belum ada peringkat
- Employee Transfer DocumentDokumen48 halamanEmployee Transfer DocumentSuveetha SuviBelum ada peringkat
- Reactive Power and AC Voltage Control of LCCDokumen3 halamanReactive Power and AC Voltage Control of LCCSuveetha SuviBelum ada peringkat
- Suppression of Low Frequency Oscillation in Traction Network of High-Speed Railway Based On Auto Disturbance Rejection ControlDokumen12 halamanSuppression of Low Frequency Oscillation in Traction Network of High-Speed Railway Based On Auto Disturbance Rejection ControlSuveetha SuviBelum ada peringkat
- CGPUDokumen71 halamanCGPUSuveetha SuviBelum ada peringkat
- Applicaition Level Data TracnsperantDokumen48 halamanApplicaition Level Data TracnsperantSuveetha SuviBelum ada peringkat
- Generating Searchable Public-Key CiphertextsDokumen5 halamanGenerating Searchable Public-Key CiphertextsSuveetha SuviBelum ada peringkat
- Network and Information SecurityDokumen2 halamanNetwork and Information SecuritySuveetha SuviBelum ada peringkat
- ADBDokumen6 halamanADBSuveetha SuviBelum ada peringkat
- Network and Information SecurityDokumen2 halamanNetwork and Information SecuritySuveetha SuviBelum ada peringkat
- Cloud Computing TechniquesDokumen2 halamanCloud Computing TechniquesSuveetha SuviBelum ada peringkat
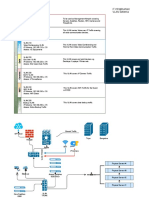
- IT Infrastructure VLAN Schema: BackupDokumen1 halamanIT Infrastructure VLAN Schema: BackupAmar Preet Singh100% (1)
- FGS-2824 User's ManualDokumen241 halamanFGS-2824 User's ManualPavelBelum ada peringkat
- T1h-Ebc (100) User ManualDokumen75 halamanT1h-Ebc (100) User ManualclaudiocbmBelum ada peringkat
- Wired Lans: Ethernet: Mcgraw-HillDokumen41 halamanWired Lans: Ethernet: Mcgraw-Hillprince keshriBelum ada peringkat
- CN Notes - Unit IDokumen17 halamanCN Notes - Unit Iapi-278882881Belum ada peringkat
- Haramaya University: Haramaya Institute of TechnologyDokumen40 halamanHaramaya University: Haramaya Institute of TechnologyEyob Adamu100% (1)
- User's Manual: KX-NTV150Dokumen136 halamanUser's Manual: KX-NTV150Chandra TioBelum ada peringkat
- OpenWrt Failsafe (OpenWrt Wiki) INGLESDokumen6 halamanOpenWrt Failsafe (OpenWrt Wiki) INGLESescaner rocioBelum ada peringkat
- Virtualization in IEC 61850 Digital Substations 1571238277Dokumen8 halamanVirtualization in IEC 61850 Digital Substations 1571238277hggjvBelum ada peringkat
- SG OtisElevator Interface (10.3)Dokumen55 halamanSG OtisElevator Interface (10.3)Yasser ArafatBelum ada peringkat
- C172 - Network Security FoundationsDokumen16 halamanC172 - Network Security FoundationsMichael ABelum ada peringkat
- Using The Layer 2 Traceroute UtilityDokumen4 halamanUsing The Layer 2 Traceroute UtilityJaved ShaikBelum ada peringkat
- 03 Layer 2 - LAN Switching Configuration Guide-BookDokumen210 halaman03 Layer 2 - LAN Switching Configuration Guide-Booka.giacchettoBelum ada peringkat
- Technical Manual TELLIN-USAU Universal Signaling Access UnitDokumen86 halamanTechnical Manual TELLIN-USAU Universal Signaling Access Unitrobins rajBelum ada peringkat
- IGMP Multicast WebinarDokumen35 halamanIGMP Multicast Webinaredonat0894Belum ada peringkat
- DO AmbassadorsCookbook2 PDFDokumen142 halamanDO AmbassadorsCookbook2 PDFbojan100% (1)
- HP 1910 24g Poe 170w Je008a Manual de UsuarioDokumen9 halamanHP 1910 24g Poe 170w Je008a Manual de UsuarioMagodma TqmBelum ada peringkat
- Im33k10a10 50eDokumen40 halamanIm33k10a10 50efernandovaras2005Belum ada peringkat
- Vraj 2.9.2 Lab - Basic Switch and End Device ConfigurationDokumen3 halamanVraj 2.9.2 Lab - Basic Switch and End Device ConfigurationVRAJ PRAJAPATIBelum ada peringkat
- Extremeswitching X435 Series: HighlightsDokumen6 halamanExtremeswitching X435 Series: HighlightsRahmat KhanBelum ada peringkat
- Network Switch: From Wikipedia, The Free EncyclopediaDokumen7 halamanNetwork Switch: From Wikipedia, The Free EncyclopediashravandownloadBelum ada peringkat
- 00 Catalog SIP E7 CompleteDokumen934 halaman00 Catalog SIP E7 Completezinab90Belum ada peringkat
- 090.560-CS Quantum LX Condenser-Vessel 3.0x 2011-08Dokumen92 halaman090.560-CS Quantum LX Condenser-Vessel 3.0x 2011-08Franz CorasBelum ada peringkat
- PS CORE Graduate Programme OverviewDokumen2 halamanPS CORE Graduate Programme OverviewChristopher AiyapiBelum ada peringkat
- Resume - Manas Kumar Latest AugustDokumen3 halamanResume - Manas Kumar Latest AugustManas PanigrahiBelum ada peringkat
- Switch v7LAB StudentDokumen206 halamanSwitch v7LAB Studentkcf4scribdBelum ada peringkat
- Notas JNCDADokumen31 halamanNotas JNCDAAlban AliuBelum ada peringkat
- DCMDS20SG Vol1Dokumen454 halamanDCMDS20SG Vol1Kv142 KvBelum ada peringkat
- 300 620 CCNP Data Center AciDokumen1.348 halaman300 620 CCNP Data Center AciHossain HalderBelum ada peringkat
- INFO-6078 - Lab 2 - OSI Model - Layers 2 & 3Dokumen3 halamanINFO-6078 - Lab 2 - OSI Model - Layers 2 & 3Minh Phuc LưBelum ada peringkat