Anda mungkin juga menyukai
- Readme PDFDokumen2 halamanReadme PDFAnant NaikBelum ada peringkat
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningDari EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningBelum ada peringkat
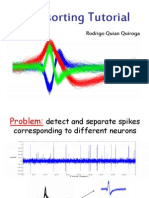
- Spike Sorting TutorialDokumen25 halamanSpike Sorting Tutorialtiger05Belum ada peringkat
- Digital Spectral Analysis MATLAB® Software User GuideDari EverandDigital Spectral Analysis MATLAB® Software User GuideBelum ada peringkat
- MCS 041 2011Dokumen7 halamanMCS 041 2011peetkumarBelum ada peringkat
- ATAT Interface: Contributed by Long XunDokumen32 halamanATAT Interface: Contributed by Long XunDong YehBelum ada peringkat
- 0/1 Knapsack Algorithm Comparison: Jacek Dzikowski Illinois Institute of Technology E-Mail: Dzikjac@iit - EduDokumen15 halaman0/1 Knapsack Algorithm Comparison: Jacek Dzikowski Illinois Institute of Technology E-Mail: Dzikjac@iit - EduskimdadBelum ada peringkat
- A Matlab GUI For Use With ISOLA Fortran Codes: Esokos@upatras - GR Jz@karel - Troja.mff - Cuni.czDokumen34 halamanA Matlab GUI For Use With ISOLA Fortran Codes: Esokos@upatras - GR Jz@karel - Troja.mff - Cuni.czGunadi Suryo JatmikoBelum ada peringkat
- Ecg ViewerDokumen12 halamanEcg ViewerMarisolBelum ada peringkat
- Parallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory ArchitecturesDokumen7 halamanParallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory Architecturesvermashanu89Belum ada peringkat
- Dynamic Clustering in WSNDokumen7 halamanDynamic Clustering in WSNakshaygoreBelum ada peringkat
- Lab 2 - Hierarchical Design and Linear SystemsDokumen7 halamanLab 2 - Hierarchical Design and Linear SystemsErcanŞişkoBelum ada peringkat
- Mattias Ohlsson - Exercise I: Perceptrons and Multi-Layer Perceptrons For Classification and Prediction of Time SeriesDokumen13 halamanMattias Ohlsson - Exercise I: Perceptrons and Multi-Layer Perceptrons For Classification and Prediction of Time SeriesAsvcxvBelum ada peringkat
- Mallopt Man InstructDokumen6 halamanMallopt Man InstructBharanitharan SundaramBelum ada peringkat
- Lab 1Dokumen13 halamanLab 1YJohn88Belum ada peringkat
- LAMMPSDokumen92 halamanLAMMPSdaniyalhassan2789Belum ada peringkat
- Notes CodeDokumen8 halamanNotes CodeIsmael ArceBelum ada peringkat
- Atom-4 2 0Dokumen17 halamanAtom-4 2 0Elias BritoBelum ada peringkat
- Networks Lab Assignment 2Dokumen2 halamanNetworks Lab Assignment 2006honey006Belum ada peringkat
- Systemverilog UVM QADokumen9 halamanSystemverilog UVM QAAshwini PatilBelum ada peringkat
- Ct-Ask Manual v1.1Dokumen7 halamanCt-Ask Manual v1.1GAGANPREET SINGHBelum ada peringkat
- Mvc2 ManualDokumen49 halamanMvc2 ManualMICHELLE ALEXANDRA SOTOMAYOR MONTECINOSBelum ada peringkat
- Mtinv PDFDokumen50 halamanMtinv PDFrolohe15207Belum ada peringkat
- Torch: The Fundamentals ofDokumen45 halamanTorch: The Fundamentals ofAravind AriharasudhanBelum ada peringkat
- Lab 1Dokumen11 halamanLab 1Rigor RempilloBelum ada peringkat
- Sheng BTEDokumen11 halamanSheng BTESoumya MondalBelum ada peringkat
- Some SAC Tips and Macro ExamplesDokumen7 halamanSome SAC Tips and Macro Examplesvelkus2013Belum ada peringkat
- MZmine GC-MS Tutorial v1.1Dokumen11 halamanMZmine GC-MS Tutorial v1.1Thomas AuffrayBelum ada peringkat
- c3d2OpenSim - TutorialDokumen8 halamanc3d2OpenSim - TutorialStefanBelum ada peringkat
- Ansys - MEMS Lab IntroductionDokumen9 halamanAnsys - MEMS Lab IntroductionJag JagBelum ada peringkat
- Software-Defined Radio Lab 2: Data Modulation and TransmissionDokumen8 halamanSoftware-Defined Radio Lab 2: Data Modulation and TransmissionpaulCGBelum ada peringkat
- GloMoSim ManualDokumen5 halamanGloMoSim Manualmohammedyusuf887500Belum ada peringkat
- Principal Component Analysis of Protein DynamicsDokumen5 halamanPrincipal Component Analysis of Protein DynamicsmnstnBelum ada peringkat
- Simulation Methods in Statistical Physics, Project Report, FK7029, Stockholm UniversityDokumen31 halamanSimulation Methods in Statistical Physics, Project Report, FK7029, Stockholm Universitysebastian100% (2)
- 4 Implementing Application Specific Routines: App.c App.cDokumen5 halaman4 Implementing Application Specific Routines: App.c App.cKailash BhosaleBelum ada peringkat
- Machine Learning AssignmentDokumen8 halamanMachine Learning AssignmentJoshuaDownesBelum ada peringkat
- 1 Computer Lab For Astrophysical Gasdynamics Course (Mellema 2011)Dokumen9 halaman1 Computer Lab For Astrophysical Gasdynamics Course (Mellema 2011)LurzizareBelum ada peringkat
- Scan Primitives For Vector ComputersDokumen10 halamanScan Primitives For Vector ComputersAnonymous RrGVQjBelum ada peringkat
- ECG Viewer v1.2.1 User ManualDokumen12 halamanECG Viewer v1.2.1 User ManualalinaBelum ada peringkat
- ECG Viewer v1.2.1 User ManualDokumen12 halamanECG Viewer v1.2.1 User ManualalinaBelum ada peringkat
- ECG Viewer v1.2.1 User ManualDokumen12 halamanECG Viewer v1.2.1 User ManualalinaBelum ada peringkat
- Homework 1: Wireless Sensor NetworksDokumen3 halamanHomework 1: Wireless Sensor NetworksNgọc TháiBelum ada peringkat
- Mechanical Vibration Lab ReportDokumen7 halamanMechanical Vibration Lab ReportChris NichollsBelum ada peringkat
- Fundamentals of Machine Learning Support Vector Machines, Practical SessionDokumen4 halamanFundamentals of Machine Learning Support Vector Machines, Practical SessionvothiquynhyenBelum ada peringkat
- Atp ComtradeDokumen8 halamanAtp ComtradeJorge VascoBelum ada peringkat
- FYSMENA4111 Computer Lab 4 DOSDokumen5 halamanFYSMENA4111 Computer Lab 4 DOSwer809Belum ada peringkat
- Computer Organisation and Architecture:Multiplier DesignDokumen6 halamanComputer Organisation and Architecture:Multiplier DesignSreekanth GopalanBelum ada peringkat
- Sorting Proj DetailsDokumen6 halamanSorting Proj DetailsCS60Lakshya PantBelum ada peringkat
- KJ Mohamed Dhanish MIP 2Dokumen36 halamanKJ Mohamed Dhanish MIP 2180051601033 ecea2018Belum ada peringkat
- Modeling and Digital Simulation Case Studies: 3.1 Pre-Lab AssignmentDokumen13 halamanModeling and Digital Simulation Case Studies: 3.1 Pre-Lab AssignmentLittle_skipBelum ada peringkat
- Earthquake PredictionDokumen20 halamanEarthquake PredictionGnrBelum ada peringkat
- The Beginners Guide To Analyzing GSM Data in MatLabDokumen9 halamanThe Beginners Guide To Analyzing GSM Data in MatLabapi-26400509Belum ada peringkat
- A Neural Network Model Using PythonDokumen10 halamanA Neural Network Model Using PythonKarol SkowronskiBelum ada peringkat
- ArticuloDokumen7 halamanArticuloGonzalo Peñaloza PlataBelum ada peringkat
- User Guide Incompact3d V1-0Dokumen8 halamanUser Guide Incompact3d V1-0Danielle HaysBelum ada peringkat
- Enter Post Title HereDokumen12 halamanEnter Post Title HereArun JagaBelum ada peringkat
- Tutorial 1Dokumen11 halamanTutorial 1Witold SzejgisBelum ada peringkat
- MaxEnt Lambda FilesDokumen6 halamanMaxEnt Lambda FilesMarek BednářBelum ada peringkat
- NS2 Lab Manual NS-2Dokumen37 halamanNS2 Lab Manual NS-2binzbinz100% (1)
- ISSCC ShortCourseDokumen3 halamanISSCC ShortCoursesanjayr_nittBelum ada peringkat
- HW 4Dokumen6 halamanHW 4sanjayr_nittBelum ada peringkat
- Enz A Short Story of EKV ModelDokumen7 halamanEnz A Short Story of EKV Modelsanjayr_nittBelum ada peringkat
- Cadence SimDokumen34 halamanCadence Simsanjayr_nittBelum ada peringkat
- ALD Training CorporateDokumen5 halamanALD Training Corporatesanjayr_nittBelum ada peringkat
- ISSCC ShortCourseDokumen3 halamanISSCC ShortCoursesanjayr_nittBelum ada peringkat
- Spectre STB AnalysisDokumen6 halamanSpectre STB Analysissanjayr_nittBelum ada peringkat
- Spectre Noise Analysis: Vishal Saxena, Boise State UniversityDokumen19 halamanSpectre Noise Analysis: Vishal Saxena, Boise State UniversityWazir SinghBelum ada peringkat
- Chap01 (12 12 06)Dokumen15 halamanChap01 (12 12 06)Arjun SrinivasBelum ada peringkat
- Lecture2 - Device Operation and ModelsDokumen7 halamanLecture2 - Device Operation and Modelssanjayr_nittBelum ada peringkat
- Loop Stability AnalysisDokumen44 halamanLoop Stability AnalysisMallikarjun S PatilBelum ada peringkat
- Lecture 192 - Cmos Passive Components - I: (READING: Text-Sec. 2.10) ObjectiveDokumen10 halamanLecture 192 - Cmos Passive Components - I: (READING: Text-Sec. 2.10) Objectivesanjayr_nittBelum ada peringkat
- Chap01 (12 12 06)Dokumen15 halamanChap01 (12 12 06)Arjun SrinivasBelum ada peringkat
- E4215: Analog Filter Synthesis and Design Frequently Used Numerical ApproximationsDokumen2 halamanE4215: Analog Filter Synthesis and Design Frequently Used Numerical Approximationssanjayr_nittBelum ada peringkat
- OverviewDokumen19 halamanOverviewsanjayr_nittBelum ada peringkat
- Allen Practice AnalogDokumen23 halamanAllen Practice AnalogvarunjothishBelum ada peringkat
- Tutorial1 08 PDFDokumen2 halamanTutorial1 08 PDFsanjayr_nittBelum ada peringkat
- DM ch10Dokumen64 halamanDM ch10sanjayr_nittBelum ada peringkat
- Mixer Ised 2013Dokumen5 halamanMixer Ised 2013sanjayr_nittBelum ada peringkat
- Ee 348 S13 SyllabusDokumen8 halamanEe 348 S13 Syllabussanjayr_nittBelum ada peringkat
- Ee 348 S13 SyllabusDokumen8 halamanEe 348 S13 Syllabussanjayr_nittBelum ada peringkat
- Announcements: - BJT (Cont'd) - BJT Amplifiers Reading: Chapter 4.6-5.1Dokumen25 halamanAnnouncements: - BJT (Cont'd) - BJT Amplifiers Reading: Chapter 4.6-5.1sanjayr_nittBelum ada peringkat
- Nokia 1616/1800 User Guide: Cyan CyanDokumen44 halamanNokia 1616/1800 User Guide: Cyan Cyansanjayr_nittBelum ada peringkat
- OtaDokumen8 halamanOtasanjayr_nittBelum ada peringkat
- OtaDokumen8 halamanOtasanjayr_nittBelum ada peringkat
- Summative Test Gr7Dokumen1 halamanSummative Test Gr7Les Angelz100% (1)
- Steam / Power SystemDokumen63 halamanSteam / Power SystemNabil SalimBelum ada peringkat
- WPS For Different Materail by BhelDokumen176 halamanWPS For Different Materail by Bhelsaisssms911691% (46)
- KPS Alignment Procedure & FormulaDokumen4 halamanKPS Alignment Procedure & FormulaWidhyatmika RestuBelum ada peringkat
- DMD Effects in MMF and Delay CalculationDokumen7 halamanDMD Effects in MMF and Delay CalculationMartin Escribano MadinaBelum ada peringkat
- MODULE 0 CPE105 Review On StatisticsDokumen12 halamanMODULE 0 CPE105 Review On StatisticsKishiane Ysabelle L. CabaticBelum ada peringkat
- Fan Laws: Table 1 Fan Laws Parameters Variable ‘n' Speed Variable ‘ρ' Density Variable ‘d' Impeller Diameter p Q PpowDokumen3 halamanFan Laws: Table 1 Fan Laws Parameters Variable ‘n' Speed Variable ‘ρ' Density Variable ‘d' Impeller Diameter p Q Ppowgeetikag_23Belum ada peringkat
- Tutorial 4 JawapanDokumen6 halamanTutorial 4 JawapanlimBelum ada peringkat
- KA Chemistry Notes PartialDokumen146 halamanKA Chemistry Notes PartialAnjali PradhanBelum ada peringkat
- Day 4 and 5 - Deductive Reasoning and Two Column Proofs AnswersDokumen4 halamanDay 4 and 5 - Deductive Reasoning and Two Column Proofs Answersapi-253195113Belum ada peringkat
- Poly MobilDokumen49 halamanPoly MobilPham Thanh HUng0% (1)
- From External Alarm 17pli061 Asam - Asam - JorongDokumen4 halamanFrom External Alarm 17pli061 Asam - Asam - JorongAMSARAH BR MUNTHEBelum ada peringkat
- Norma JIC 37Dokumen36 halamanNorma JIC 37guguimirandaBelum ada peringkat
- Control Systems Design ProjectDokumen3 halamanControl Systems Design ProjectHasan ÇalışkanBelum ada peringkat
- Matlab Manual1Dokumen25 halamanMatlab Manual1Richard BrooksBelum ada peringkat
- Chapter 1-Part 1: Half-Wave RectifiersDokumen50 halamanChapter 1-Part 1: Half-Wave RectifiersWeehao SiowBelum ada peringkat
- Chapter 1-Thermodynamic-Merged-CompressedDokumen60 halamanChapter 1-Thermodynamic-Merged-CompressedAina SyafiqahBelum ada peringkat
- Powerflex 750-Series Ac Drives: Technical DataDokumen242 halamanPowerflex 750-Series Ac Drives: Technical DataJosé Santiago Miranda BernaolaBelum ada peringkat
- No Load Test: ObjectiveDokumen5 halamanNo Load Test: ObjectiveyashBelum ada peringkat
- Lab ReportDokumen4 halamanLab ReportSyafiq MTBelum ada peringkat
- Inorganic Chemistry 2 Main Exam (3) and MemoDokumen11 halamanInorganic Chemistry 2 Main Exam (3) and MemoKgasu MosaBelum ada peringkat
- Sequential Logic: Unit-IDokumen86 halamanSequential Logic: Unit-IMonika RawatBelum ada peringkat
- Some Best Questions On TrigonometryDokumen4 halamanSome Best Questions On TrigonometryRaghav MadanBelum ada peringkat
- EE2253 - Control Systems PDFDokumen124 halamanEE2253 - Control Systems PDFaduveyBelum ada peringkat
- Athene S Theory of Everything PDFDokumen19 halamanAthene S Theory of Everything PDFAdriana Ealangi0% (1)
- Power Amplifiers: Ranjith Office Level 4 - Building 193 - EEE BuildingDokumen19 halamanPower Amplifiers: Ranjith Office Level 4 - Building 193 - EEE BuildingArambya Ankit KallurayaBelum ada peringkat
- The Law of CosinesDokumen12 halamanThe Law of CosinesLei Xennia YtingBelum ada peringkat
- Gurgaon Tuitions Contacts NumbersDokumen8 halamanGurgaon Tuitions Contacts NumbersSai KiranBelum ada peringkat
- Aerodyn2 Discussion 11 Ceilings Ant Time To ClimbDokumen26 halamanAerodyn2 Discussion 11 Ceilings Ant Time To Climbshop printBelum ada peringkat
- Properties of LiOH and LiNO3 Aqueous SolutionsDokumen13 halamanProperties of LiOH and LiNO3 Aqueous Solutionstim tengBelum ada peringkat
- How to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipDari EverandHow to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipPenilaian: 4.5 dari 5 bintang4.5/5 (1135)
- Summary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisDari EverandSummary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisPenilaian: 4.5 dari 5 bintang4.5/5 (22)
- How to Improve English Speaking: How to Become a Confident and Fluent English SpeakerDari EverandHow to Improve English Speaking: How to Become a Confident and Fluent English SpeakerPenilaian: 4.5 dari 5 bintang4.5/5 (56)
- Summary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisDari EverandSummary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisPenilaian: 5 dari 5 bintang5/5 (15)
- Summary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisDari EverandSummary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisPenilaian: 4.5 dari 5 bintang4.5/5 (2)
- Summary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisDari EverandSummary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisPenilaian: 4.5 dari 5 bintang4.5/5 (30)
- Weapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingDari EverandWeapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingPenilaian: 4.5 dari 5 bintang4.5/5 (149)
- The 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessageDari EverandThe 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessagePenilaian: 5 dari 5 bintang5/5 (73)
- The Story of the World, Vol. 1 AudiobookDari EverandThe Story of the World, Vol. 1 AudiobookPenilaian: 4.5 dari 5 bintang4.5/5 (3)
- Dumbing Us Down: The Hidden Curriculum of Compulsory SchoolingDari EverandDumbing Us Down: The Hidden Curriculum of Compulsory SchoolingPenilaian: 4.5 dari 5 bintang4.5/5 (496)
- Stoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionDari EverandStoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionPenilaian: 5 dari 5 bintang5/5 (51)
- Summary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisDari EverandSummary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisPenilaian: 5 dari 5 bintang5/5 (3)
- Summary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisDari EverandSummary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisPenilaian: 4 dari 5 bintang4/5 (6)
- Little Soldiers: An American Boy, a Chinese School, and the Global Race to AchieveDari EverandLittle Soldiers: An American Boy, a Chinese School, and the Global Race to AchievePenilaian: 4 dari 5 bintang4/5 (25)
- Learn Spanish While SleepingDari EverandLearn Spanish While SleepingPenilaian: 4 dari 5 bintang4/5 (20)
- Why Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativeDari EverandWhy Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativePenilaian: 3.5 dari 5 bintang3.5/5 (54)
- Summary of The Power of Habit: Why We Do What We Do in Life and Business by Charles DuhiggDari EverandSummary of The Power of Habit: Why We Do What We Do in Life and Business by Charles DuhiggPenilaian: 4.5 dari 5 bintang4.5/5 (261)
- Make It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningDari EverandMake It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningPenilaian: 4.5 dari 5 bintang4.5/5 (55)
- The Story of the World, Vol. 2 AudiobookDari EverandThe Story of the World, Vol. 2 AudiobookPenilaian: 5 dari 5 bintang5/5 (1)
- Gladys Aylward: The Adventure of a LifetimeDari EverandGladys Aylward: The Adventure of a LifetimePenilaian: 5 dari 5 bintang5/5 (10)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindDari EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindBelum ada peringkat
- Summary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisDari EverandSummary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisPenilaian: 5 dari 5 bintang5/5 (2)
- Cynical Theories: How Activist Scholarship Made Everything about Race, Gender, and Identity―and Why This Harms EverybodyDari EverandCynical Theories: How Activist Scholarship Made Everything about Race, Gender, and Identity―and Why This Harms EverybodyPenilaian: 4.5 dari 5 bintang4.5/5 (221)
- Learn Japanese - Level 1: Introduction to Japanese, Volume 1: Volume 1: Lessons 1-25Dari EverandLearn Japanese - Level 1: Introduction to Japanese, Volume 1: Volume 1: Lessons 1-25Penilaian: 5 dari 5 bintang5/5 (17)
- You Are Not Special: And Other EncouragementsDari EverandYou Are Not Special: And Other EncouragementsPenilaian: 4.5 dari 5 bintang4.5/5 (6)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4.5 dari 5 bintang4.5/5 (1873)
- On Becoming Babywise (Updated and Expanded): Giving Your Infant the Gift of Nightime SleepDari EverandOn Becoming Babywise (Updated and Expanded): Giving Your Infant the Gift of Nightime SleepPenilaian: 4 dari 5 bintang4/5 (22)