Anda mungkin juga menyukai
- Formulário de Cadastro de ÍtensDokumen2 halamanFormulário de Cadastro de ÍtensAndersonAfdsilvasBelum ada peringkat
- NR 01 - Ohsas 18001 - 2007Dokumen68 halamanNR 01 - Ohsas 18001 - 2007CPSSTBelum ada peringkat
- Historia Da Cosmologia 1Dokumen15 halamanHistoria Da Cosmologia 1João Paulo GomesBelum ada peringkat
- 7 Saga Detonado 1Dokumen25 halaman7 Saga Detonado 1Paulo SantanaBelum ada peringkat
- Apostila de Brincadeiras e AtividadesDokumen10 halamanApostila de Brincadeiras e AtividadesvagnerBelum ada peringkat
- Contexto Do Diagnóstico de MEDokumen34 halamanContexto Do Diagnóstico de MErodrigobiondiBelum ada peringkat
- Cartilha Fies Renegociacao 2022Dokumen19 halamanCartilha Fies Renegociacao 2022Paulo AndersonBelum ada peringkat
- Aula 24 - Música e LiteraturaDokumen20 halamanAula 24 - Música e LiteraturaTarcisio Jackson Halley SaBelum ada peringkat
- Apostila Biologia e Manejo em CativeiroDokumen54 halamanApostila Biologia e Manejo em CativeiroJunior GuimarãesBelum ada peringkat
- Teste Compreensao Oral 7 6ANODokumen2 halamanTeste Compreensao Oral 7 6ANOsusana lopesBelum ada peringkat
- Abordagem Neoclássica Da AdministraçãoDokumen7 halamanAbordagem Neoclássica Da AdministraçãoDavi CunhaBelum ada peringkat
- Funcao HidrocabornetoDokumen75 halamanFuncao HidrocabornetoLaércio souzaBelum ada peringkat
- 2002.04.07 - Acidente Entre Ônibus Da Viação São Geraldo e Uno Mille - Estado de MinasDokumen1 halaman2002.04.07 - Acidente Entre Ônibus Da Viação São Geraldo e Uno Mille - Estado de MinasluciomarioBelum ada peringkat
- As Áreas Metropolitanas de Lisboa e PortoDokumen2 halamanAs Áreas Metropolitanas de Lisboa e PortoRui Manuel Pereira JesusBelum ada peringkat
- Virus e Viroses - 3º Ano - Bio - 01Dokumen58 halamanVirus e Viroses - 3º Ano - Bio - 01Igor CajatyBelum ada peringkat
- Condição de Equilibro de Translação e de RotaçãoDokumen13 halamanCondição de Equilibro de Translação e de RotaçãoMomade Ibraimo AssaneBelum ada peringkat
- Arim Faixa Rio PretoDokumen199 halamanArim Faixa Rio PretoPauloBelum ada peringkat
- Ficha de CaixaDokumen1 halamanFicha de CaixaJefferson Jales MenescalBelum ada peringkat
- Qualidade Atendimento Ao ClienteDokumen62 halamanQualidade Atendimento Ao ClienteSirene MonturilBelum ada peringkat
- Plano Anual de Ensino - Língua Portuguesa FinalizadoDokumen9 halamanPlano Anual de Ensino - Língua Portuguesa FinalizadoRubia Cristiane BalckerBelum ada peringkat
- Resultado Avaliacao Parcial Documentacao Chamada-Regular Sisu-2023-1 10032023-235752Dokumen333 halamanResultado Avaliacao Parcial Documentacao Chamada-Regular Sisu-2023-1 10032023-235752Luis Fernando Pereira NevesBelum ada peringkat
- SINAPI CT LOTE1 ESCADAS v002Dokumen50 halamanSINAPI CT LOTE1 ESCADAS v002Ana Paula Ribeiro de AraujoBelum ada peringkat
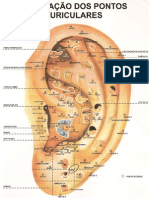
- Mapa de Auriculo TerapiaDokumen2 halamanMapa de Auriculo Terapiamemoriaseregressao100% (1)
- Febre Reumática Na CriançaDokumen24 halamanFebre Reumática Na CriançaMarco TuxoBelum ada peringkat
- E-Book Vida Leve - Lista de Compras e Sugestão AlimentarDokumen20 halamanE-Book Vida Leve - Lista de Compras e Sugestão AlimentarGenuina MonicoBelum ada peringkat
- Antibioticos Na Clinica VeterinariaDokumen13 halamanAntibioticos Na Clinica VeterinariaNady Chaves100% (1)
- O Estado Do Estado em Angola - Cesaltina AbreuDokumen15 halamanO Estado Do Estado em Angola - Cesaltina AbreuMadaleno Sita António DiasBelum ada peringkat
- 1 - O Que É A Viagem AstralDokumen3 halaman1 - O Que É A Viagem AstralSergio HentzBelum ada peringkat
- Karcher HD Maxi ManualDokumen6 halamanKarcher HD Maxi Manualjose_shermanBelum ada peringkat
- Valores Castração PetzferaDokumen1 halamanValores Castração PetzferaLuis Eduardo RibeiroBelum ada peringkat