Anda mungkin juga menyukai
- Input / Output: S.Vaishnavi Programming For Problem SolvingDokumen48 halamanInput / Output: S.Vaishnavi Programming For Problem SolvingkavyaBelum ada peringkat
- Formatting C PreviewDokumen9 halamanFormatting C PreviewgordanaBelum ada peringkat
- Formatting Text - MATLAB & Simulink - MathWorks IndiaDokumen8 halamanFormatting Text - MATLAB & Simulink - MathWorks IndiaARVINDBelum ada peringkat
- Printing Floating-Point Numbers Quickly and Accurately With IntegersDokumen11 halamanPrinting Floating-Point Numbers Quickly and Accurately With IntegersopaopaopaopaopaBelum ada peringkat
- A Tutorial For Matlab: FprintfDokumen5 halamanA Tutorial For Matlab: FprintfbrianBelum ada peringkat
- Formatting Numbers With C++ Output StreamsDokumen9 halamanFormatting Numbers With C++ Output StreamsVladBelum ada peringkat
- Gretl Guide (051 100)Dokumen50 halamanGretl Guide (051 100)Taha NajidBelum ada peringkat
- Secrets of PrintfDokumen6 halamanSecrets of PrintfguzskaBelum ada peringkat
- Data Structure Strings in C: Concepts, Input/Output, ManipulationDokumen14 halamanData Structure Strings in C: Concepts, Input/Output, ManipulationNaveen GowdruBelum ada peringkat
- Advanced AutoLISP ProgrammingDokumen42 halamanAdvanced AutoLISP Programmingnosena13Belum ada peringkat
- 23665 - Programming المرحلة الثانيةDokumen51 halaman23665 - Programming المرحلة الثانيةMahmood HameedBelum ada peringkat
- CDokumen6 halamanCAmshgautamBelum ada peringkat
- 1.4 String FormattingDokumen7 halaman1.4 String Formattingmahanth gowdaBelum ada peringkat
- Python Floating Point Arithmetic Guide: Rounds, Formats & PrecisionDokumen4 halamanPython Floating Point Arithmetic Guide: Rounds, Formats & PrecisionFelipe Cabeza ParejaBelum ada peringkat
- Basic Tutorial (Part 4 of 8) : Making Plots of FunctionsDokumen8 halamanBasic Tutorial (Part 4 of 8) : Making Plots of FunctionsAdexa PutraBelum ada peringkat
- PrintfDokumen13 halamanPrintfKrishna Emanuel RochaBelum ada peringkat
- C Primer Plus NotesDokumen25 halamanC Primer Plus NotesChenzi JiangBelum ada peringkat
- Notebooks and Documents Part 2Dokumen112 halamanNotebooks and Documents Part 2Sweta AkhoriBelum ada peringkat
- The Language of Technical ComputingDokumen24 halamanThe Language of Technical Computingyogesh sharmaBelum ada peringkat
- Post Processor ManualDokumen16 halamanPost Processor ManualVagner Aux CadBelum ada peringkat
- Chapter-4: Managing Input and Output OperationDokumen55 halamanChapter-4: Managing Input and Output Operationvinod_msBelum ada peringkat
- Examples Documentation VPM FAQ Built in V: Advanced TopicsDokumen22 halamanExamples Documentation VPM FAQ Built in V: Advanced TopicszenBelum ada peringkat
- Mat Lab PlotsDokumen21 halamanMat Lab PlotsBecirspahic AlmirBelum ada peringkat
- String formatting in Python: 3 standard waysDokumen2 halamanString formatting in Python: 3 standard waysIZAAN SHARIEFBelum ada peringkat
- Fprintf (MATLAB Functions)Dokumen6 halamanFprintf (MATLAB Functions)Saurabh TiwariBelum ada peringkat
- Input Output PerlDokumen13 halamanInput Output Perlsreenivas_enishettyBelum ada peringkat
- CSCI 230 Basic I/O – printfDokumen19 halamanCSCI 230 Basic I/O – printfAnjali NaiduBelum ada peringkat
- Sample Exam 2Dokumen8 halamanSample Exam 2Ivan VargasBelum ada peringkat
- Numerical Computing Lab 2Dokumen25 halamanNumerical Computing Lab 2Aamna ImranBelum ada peringkat
- Session 7Dokumen11 halamanSession 7Keroro StoneBelum ada peringkat
- V Programming LanguageDokumen34 halamanV Programming LanguagezenBelum ada peringkat
- C Interview Questions and Answers For ExperiencedDokumen12 halamanC Interview Questions and Answers For Experiencedshenbagavalli kBelum ada peringkat
- Perl Faq 4Dokumen42 halamanPerl Faq 4jitenkum123Belum ada peringkat
- Printf Case StudyDokumen14 halamanPrintf Case StudytheyaimsBelum ada peringkat
- Matlab BasicDokumen25 halamanMatlab Basicyogesh sharmaBelum ada peringkat
- Plotting rpart trees with prpDokumen28 halamanPlotting rpart trees with prpalexa_sherpyBelum ada peringkat
- (Chapter 5) PHP Arithmetic Operators and Predefined Functions (And String Functions)Dokumen1 halaman(Chapter 5) PHP Arithmetic Operators and Predefined Functions (And String Functions)Samuel Alexander MarchantBelum ada peringkat
- Advanced PlottingDokumen65 halamanAdvanced PlottingNeelimaBelum ada peringkat
- 1 Python BasicsDokumen18 halaman1 Python BasicsArya BhattBelum ada peringkat
- Python String FormatDokumen15 halamanPython String FormatAbhilash MishraBelum ada peringkat
- CSE-326-16-Chapter StringDokumen38 halamanCSE-326-16-Chapter StringYogiBelum ada peringkat
- Fortran Arrays PDFDokumen6 halamanFortran Arrays PDFMirza BasitBelum ada peringkat
- Programming Assignment 1: Basic Data StructuresDokumen18 halamanProgramming Assignment 1: Basic Data StructuresJohn Justine VillarBelum ada peringkat
- Specman e BasicsDokumen27 halamanSpecman e BasicsReetika BishnoiBelum ada peringkat
- PRINTF FORMATTINGDokumen5 halamanPRINTF FORMATTINGLeandroSousaBrazBelum ada peringkat
- Programming Assignment 1: Basic Data StructuresDokumen18 halamanProgramming Assignment 1: Basic Data Structuresshreyansh guptaBelum ada peringkat
- Print Formatting in PythonDokumen3 halamanPrint Formatting in PythonJai KrishnaBelum ada peringkat
- Interview Questions CDokumen11 halamanInterview Questions CminafokehBelum ada peringkat
- R LecturesDokumen10 halamanR LecturesApam BenjaminBelum ada peringkat
- Basic Data Structures Programming Assignment 1Dokumen18 halamanBasic Data Structures Programming Assignment 1Daniel SerranoBelum ada peringkat
- 4Dokumen50 halaman4Oscard KanaBelum ada peringkat
- Coding for beginners The basic syntax and structure of codingDari EverandCoding for beginners The basic syntax and structure of codingBelum ada peringkat
- Python: Advanced Guide to Programming Code with PythonDari EverandPython: Advanced Guide to Programming Code with PythonBelum ada peringkat
- Guia 2 MMDokumen1 halamanGuia 2 MMuam22Belum ada peringkat
- Cadence Virtuoso Tutorial: University of Southern CaliforniaDokumen45 halamanCadence Virtuoso Tutorial: University of Southern CaliforniavishalwinsBelum ada peringkat
- An Analytical Equation For The Oscillation Frequency of High-Frequency Ring OscillatorsDokumen5 halamanAn Analytical Equation For The Oscillation Frequency of High-Frequency Ring Oscillatorsuam22Belum ada peringkat
- Layout of Integrated Capacitors and ResistorsDokumen38 halamanLayout of Integrated Capacitors and ResistorsRAJAMOHANBelum ada peringkat
- Precise Time Interval Measurement TechniquesDokumen20 halamanPrecise Time Interval Measurement Techniquesuam22Belum ada peringkat
- TOEFL PBT BookDokumen93 halamanTOEFL PBT Bookaqua_6978% (9)
- A Constant-Gain Time-Amplifier With Digital Self-CalibrationDokumen4 halamanA Constant-Gain Time-Amplifier With Digital Self-Calibrationuam22Belum ada peringkat
- TI - SensitivityDokumen48 halamanTI - Sensitivityuam22Belum ada peringkat
- t2004 Digital ConverterDokumen102 halamant2004 Digital Converteruam22Belum ada peringkat
- An Improved Fast Acquisition Phase Frequency Detector For High Speed Phase-Locked LoopsDokumen9 halamanAn Improved Fast Acquisition Phase Frequency Detector For High Speed Phase-Locked Loopsuam22Belum ada peringkat
- Layout RulesDokumen53 halamanLayout RulesAlan SamBelum ada peringkat
- RendonWCallejaMisalignCoilsSWJ2014 PDFDokumen13 halamanRendonWCallejaMisalignCoilsSWJ2014 PDFuam22Belum ada peringkat
- An Improved Fast Acquisition Phase Frequency Detector For High Speed Phase-Locked LoopsDokumen9 halamanAn Improved Fast Acquisition Phase Frequency Detector For High Speed Phase-Locked Loopsuam22Belum ada peringkat
- AIC Project PDFDokumen6 halamanAIC Project PDFuam22Belum ada peringkat
- SC AC Simulation PDFDokumen5 halamanSC AC Simulation PDFuam22Belum ada peringkat
- Znosko-Borovsky - How Not To Play Chess PDFDokumen60 halamanZnosko-Borovsky - How Not To Play Chess PDFuam22Belum ada peringkat
- Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.776 High Speed Communications Circuits Spring 2005Dokumen29 halamanMassachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.776 High Speed Communications Circuits Spring 2005adi3443Belum ada peringkat
- CMOS Phase Frequency Detector For High Speed Applications: Masuri - Othman@mimos - MyDokumen4 halamanCMOS Phase Frequency Detector For High Speed Applications: Masuri - Othman@mimos - Myuam22Belum ada peringkat
- Modeling PLL Components Using Verilog-ADokumen3 halamanModeling PLL Components Using Verilog-Auam22Belum ada peringkat
- Difference TADokumen2 halamanDifference TAuam22Belum ada peringkat
- The Experimental GenerationDokumen15 halamanThe Experimental Generationuam22Belum ada peringkat
- Matching PropertiesDokumen8 halamanMatching Propertiesuam22Belum ada peringkat
- Escala de Do Mayor para Ukelele. Ejercicios Rítmicos PDFDokumen2 halamanEscala de Do Mayor para Ukelele. Ejercicios Rítmicos PDFuam22Belum ada peringkat
- Data TransmissionDokumen12 halamanData Transmissionuam22Belum ada peringkat
- Into To NumpyDokumen49 halamanInto To NumpyquakigBelum ada peringkat
- Hspice IntegDokumen500 halamanHspice Integuam22Belum ada peringkat
- CMP 2019Dokumen5 halamanCMP 2019uam22Belum ada peringkat
- Anaconda QuickstartDokumen5 halamanAnaconda QuickstartRenato Guimarães0% (1)
- CMP 2019Dokumen5 halamanCMP 2019uam22Belum ada peringkat
- Latch and Flip Flop Design ComparisonDokumen34 halamanLatch and Flip Flop Design Comparisonuam22Belum ada peringkat
- Predicting Star Ratings Based On Annotated Reviews of Mobile AppsDokumen8 halamanPredicting Star Ratings Based On Annotated Reviews of Mobile AppsAbdul KhaliqBelum ada peringkat
- Longuet-Higgins: Studies in Molecular Orbital Theory I: Resonance & Molecular Orbitals in Unsaturated HydrocarbonsDokumen11 halamanLonguet-Higgins: Studies in Molecular Orbital Theory I: Resonance & Molecular Orbitals in Unsaturated HydrocarbonsvanalexbluesBelum ada peringkat
- Ex NM&RSDokumen63 halamanEx NM&RSMuslim HedayetBelum ada peringkat
- Fun The Mystery of The Missing Kit Maths AdventureDokumen7 halamanFun The Mystery of The Missing Kit Maths AdventureJaredBelum ada peringkat
- Midterm 3 SolutionsDokumen6 halamanMidterm 3 SolutionscdzavBelum ada peringkat
- Stratified Random Sampling PrecisionDokumen10 halamanStratified Random Sampling PrecisionEPAH SIRENGOBelum ada peringkat
- Stack, Queue and Recursion in Data StructureDokumen26 halamanStack, Queue and Recursion in Data Structurechitvan KumarBelum ada peringkat
- Public Relations Review: Juan Meng, Bruce K. BergerDokumen12 halamanPublic Relations Review: Juan Meng, Bruce K. BergerChera HoratiuBelum ada peringkat
- Table of Common Laplace TransformsDokumen2 halamanTable of Common Laplace TransformsJohn Carlo SacramentoBelum ada peringkat
- Fatigue Analysis in Ansys WorkbenchDokumen14 halamanFatigue Analysis in Ansys WorkbenchAshokkumar VelloreBelum ada peringkat
- Decision Modeling Using SpreadsheetDokumen36 halamanDecision Modeling Using SpreadsheetamritaBelum ada peringkat
- Lab Report FormatDokumen2 halamanLab Report Formatsgupta792Belum ada peringkat
- Sachin S. Pawar: Career ObjectivesDokumen3 halamanSachin S. Pawar: Career ObjectivesSachin PawarBelum ada peringkat
- 9789533073248UWBTechnologiesDokumen454 halaman9789533073248UWBTechnologiesConstantin PişteaBelum ada peringkat
- Assignment 1 - Simple Harmonic MotionDokumen2 halamanAssignment 1 - Simple Harmonic MotionDr. Pradeep Kumar SharmaBelum ada peringkat
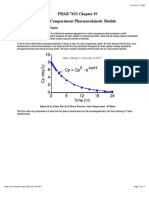
- PHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsDokumen23 halamanPHAR 7633 Chapter 19 Multi-Compartment Pharmacokinetic ModelsBandameedi RamuBelum ada peringkat
- I Can Statements - 4th Grade CC Math - NBT - Numbers and Operations in Base Ten Polka DotsDokumen13 halamanI Can Statements - 4th Grade CC Math - NBT - Numbers and Operations in Base Ten Polka DotsbrunerteachBelum ada peringkat
- Magnetic Field Splitting of Spectral LinesDokumen2 halamanMagnetic Field Splitting of Spectral LinesSio MoBelum ada peringkat
- 199307Dokumen87 halaman199307vtvuckovicBelum ada peringkat
- SPUD 604 ManualDokumen37 halamanSPUD 604 ManualfbarrazaisaBelum ada peringkat
- Fundamentals of Csec Mathematics: Section I Answer All Questions in This Section All Working Must Be Clearly ShownDokumen18 halamanFundamentals of Csec Mathematics: Section I Answer All Questions in This Section All Working Must Be Clearly ShownSamantha JohnsonBelum ada peringkat
- G (X) F (X, Y) : Marginal Distributions Definition 5Dokumen13 halamanG (X) F (X, Y) : Marginal Distributions Definition 5Kimondo KingBelum ada peringkat
- Preparation of Vector Group DiffDokumen5 halamanPreparation of Vector Group DiffvenkateshbitraBelum ada peringkat
- Divya MishraDokumen1 halamanDivya MishraKashish AwasthiBelum ada peringkat
- The 3-Rainbow Index of GraphsDokumen28 halamanThe 3-Rainbow Index of GraphsDinda KartikaBelum ada peringkat
- Optimizing Planetary Gear Design for Load DistributionDokumen17 halamanOptimizing Planetary Gear Design for Load DistributionANURAAG AAYUSHBelum ada peringkat
- Monthly Reference 5Dokumen22 halamanMonthly Reference 5Nurul AbrarBelum ada peringkat
- PCM PrincipleDokumen31 halamanPCM PrincipleSachin PatelBelum ada peringkat
- Association Rule MiningDokumen50 halamanAssociation Rule MiningbhargaviBelum ada peringkat
- Radix 64 ConversionDokumen13 halamanRadix 64 ConversionRajendra Prasad100% (1)