Anda mungkin juga menyukai
- Leisure ClubsDokumen6 halamanLeisure ClubsHari PeravaliBelum ada peringkat
- Word ListDokumen63 halamanWord Listhari17101991Belum ada peringkat
- Compassion EssayDokumen5 halamanCompassion EssayHari Peravali100% (1)
- Report On The Tractor SectorDokumen32 halamanReport On The Tractor SectorSanjeev ChaudharyBelum ada peringkat
- Assignment EN671 2Dokumen2 halamanAssignment EN671 2Hari Peravali100% (1)
- Current Trend of Tractor Industry PDFDokumen8 halamanCurrent Trend of Tractor Industry PDFHari PeravaliBelum ada peringkat
- Molten Salt Thermal Storage TechnologyDokumen3 halamanMolten Salt Thermal Storage TechnologyHari PeravaliBelum ada peringkat
- Data Analytics Workshop Schedule: 11 AM - 12 NoonDokumen1 halamanData Analytics Workshop Schedule: 11 AM - 12 NoonHari PeravaliBelum ada peringkat
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (72)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- Neurocognitive NotesDokumen11 halamanNeurocognitive NotesSyifa SharifahBelum ada peringkat
- Confidential Psychological Report-MitchellDokumen4 halamanConfidential Psychological Report-Mitchellemill002100% (5)
- OMT Evaluation 6Dokumen34 halamanOMT Evaluation 6aza bellaBelum ada peringkat
- Evolution of the Senses Through the Lens of Sea RemediesDokumen12 halamanEvolution of the Senses Through the Lens of Sea RemediesisaiahBelum ada peringkat
- I. Primary (Idiopathic) ParkinsonismDokumen104 halamanI. Primary (Idiopathic) ParkinsonismNathasia SuryawijayaBelum ada peringkat
- Overview of ApraxiaDokumen12 halamanOverview of ApraxiaMaheswarBelum ada peringkat
- Histo Soruları PDFDokumen178 halamanHisto Soruları PDFtalhaburakturaliBelum ada peringkat
- The Test of Everyday Attention ManualDokumen6 halamanThe Test of Everyday Attention ManualmetteoroBelum ada peringkat
- Trigeminal Neuralgia PDFDokumen4 halamanTrigeminal Neuralgia PDFCHenyLeeBelum ada peringkat
- Nida2-Activity BookDokumen19 halamanNida2-Activity Bookapi-358626864Belum ada peringkat
- Peripheral Nerve Hyperexcitability SundromeDokumen14 halamanPeripheral Nerve Hyperexcitability SundromeLuis ReyesBelum ada peringkat
- Kernicterus: Sahisnuta BasnetDokumen10 halamanKernicterus: Sahisnuta BasnetVaibhav KrishnaBelum ada peringkat
- Head Injury Causes and TreatmentDokumen47 halamanHead Injury Causes and TreatmentnikowareBelum ada peringkat
- Spondylosis, Cervical and LumbarDokumen1 halamanSpondylosis, Cervical and LumbarLuis HerreraBelum ada peringkat
- Bell's Palsy ReportDokumen25 halamanBell's Palsy ReportRoderick AgbuyaBelum ada peringkat
- Disorders Practice TestDokumen15 halamanDisorders Practice Testsmkaranja100% (1)
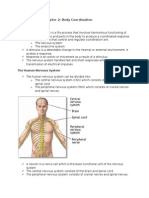
- Form 4 Science Chapter 2: Body Coordination (38Dokumen13 halamanForm 4 Science Chapter 2: Body Coordination (38Cheah Foo Kit50% (2)
- Unit 2 Medicinal Chemistry 4th Semester McqsDokumen52 halamanUnit 2 Medicinal Chemistry 4th Semester Mcqschannel jollyhood100% (1)
- Journal Article OA PDFDokumen6 halamanJournal Article OA PDFPutu 'yayuk' Widyani WiradiraniBelum ada peringkat
- Ringer's Solution Stimulates The Blood Plasma of Frogs and Moistens The Exposed Muscle. Isotonic To Amphibians - Hypertonic To HumansDokumen2 halamanRinger's Solution Stimulates The Blood Plasma of Frogs and Moistens The Exposed Muscle. Isotonic To Amphibians - Hypertonic To Humansmaypeee100% (1)
- PDF To WordDokumen193 halamanPDF To Wordjeffery0% (1)
- Final Study Guide Psyc101 Spring 2011Dokumen14 halamanFinal Study Guide Psyc101 Spring 2011FirstLady Williams100% (1)
- Anticonvulsant - WikipediaDokumen8 halamanAnticonvulsant - WikipediaRommelBaldagoBelum ada peringkat
- Chapter 11: Prognosis and Treatment PlanningDokumen10 halamanChapter 11: Prognosis and Treatment PlanningNikiBelum ada peringkat
- Web - Incar.tw-The Neurogenesis Diet and Lifestyle Upgrade Your Brain Upgrade Your LifeDokumen5 halamanWeb - Incar.tw-The Neurogenesis Diet and Lifestyle Upgrade Your Brain Upgrade Your LifeDinesh TanwarBelum ada peringkat
- A Seekers Journey - GregTurekDokumen100 halamanA Seekers Journey - GregTurekseeker33Belum ada peringkat
- Outcome Measure PresentationDokumen11 halamanOutcome Measure Presentationapi-547954700Belum ada peringkat
- Health Psychology Explains Stress, Coping and IllnessDokumen9 halamanHealth Psychology Explains Stress, Coping and IllnessShyam Kumar BanikBelum ada peringkat
- Nerve VagusDokumen6 halamanNerve Vagushildhan prabaBelum ada peringkat
- OCR Biology Practical Guide BookDokumen4 halamanOCR Biology Practical Guide BookFatima ImranBelum ada peringkat