Anda mungkin juga menyukai
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Scale Fingering ChartDokumen1 halamanScale Fingering ChartMatthew ReachBelum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- EXCEL - How To Write Perfect VLOOKUP and INDEX and MATCH FormulasDokumen29 halamanEXCEL - How To Write Perfect VLOOKUP and INDEX and MATCH Formulasgerrydimayuga100% (1)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Reverse Engineer An Excel Spreadsheet Into CA ERwin Data ModelerDokumen7 halamanReverse Engineer An Excel Spreadsheet Into CA ERwin Data ModelerMatthew Reach0% (1)
- Solution Manual For Investment Science by David LuenbergerDokumen94 halamanSolution Manual For Investment Science by David Luenbergerkoenajax96% (28)
- IBM Insurance IAA Warehouse GIMv85Dokumen23 halamanIBM Insurance IAA Warehouse GIMv85Matthew ReachBelum ada peringkat
- Hazardous Area ClassificationDokumen36 halamanHazardous Area Classificationvenkeeku100% (1)
- Astm A394 2008 PDFDokumen6 halamanAstm A394 2008 PDFJavier Ricardo Romero BohorquezBelum ada peringkat
- Sample Test - Exam 000-470 - IBM Unica Campaign V8.5Dokumen3 halamanSample Test - Exam 000-470 - IBM Unica Campaign V8.5Matthew ReachBelum ada peringkat
- Living and Working: in SwedenDokumen24 halamanLiving and Working: in SwedenMatthew ReachBelum ada peringkat
- Hadoop Interview QuestionsDokumen1 halamanHadoop Interview QuestionsMatthew ReachBelum ada peringkat
- EB2406 - Teradata PDFDokumen18 halamanEB2406 - Teradata PDFMatthew ReachBelum ada peringkat
- Idoc - Pub - Data Model Flexcube Data Model PDFDokumen353 halamanIdoc - Pub - Data Model Flexcube Data Model PDFMatthew ReachBelum ada peringkat
- Pyspark-1 6 1Dokumen32 halamanPyspark-1 6 1Matthew ReachBelum ada peringkat
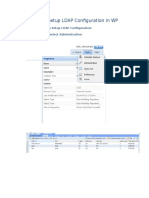
- How To Setup LDAP in ERwin Web PortalDokumen3 halamanHow To Setup LDAP in ERwin Web PortalMatthew ReachBelum ada peringkat
- Microsoft Data Warehouse Design ConsiderationsDokumen36 halamanMicrosoft Data Warehouse Design ConsiderationsMatthew ReachBelum ada peringkat
- 11 - Chapter 3 PDFDokumen123 halaman11 - Chapter 3 PDFMatthew ReachBelum ada peringkat
- A Loan-Level Data Collection For Buy-To-Let Lending: Phase 2Dokumen23 halamanA Loan-Level Data Collection For Buy-To-Let Lending: Phase 2Matthew ReachBelum ada peringkat
- PharmaSUG 2016 SS05Dokumen19 halamanPharmaSUG 2016 SS05Matthew ReachBelum ada peringkat
- Temporal Query Processing in TeradataDokumen6 halamanTemporal Query Processing in TeradataMatthew ReachBelum ada peringkat
- 6545 Us35000Dokumen4 halaman6545 Us35000Rafael BarrosBelum ada peringkat
- Arithmetic Unit: Dr. Sowmya BJDokumen146 halamanArithmetic Unit: Dr. Sowmya BJtinni09112003Belum ada peringkat
- NumaticsFRLFlexiblokR072010 EsDokumen40 halamanNumaticsFRLFlexiblokR072010 EsGabriel San Martin RifoBelum ada peringkat
- Beam Design: BackgroundDokumen2 halamanBeam Design: BackgroundolomizanaBelum ada peringkat
- Physics Gcse Coursework Resistance of A WireDokumen8 halamanPhysics Gcse Coursework Resistance of A Wiref5dq3ch5100% (2)
- W.R. Klemm (Auth.) - Atoms of Mind - The - Ghost in The Machine - Materializes-Springer Netherlands (2011)Dokumen371 halamanW.R. Klemm (Auth.) - Atoms of Mind - The - Ghost in The Machine - Materializes-Springer Netherlands (2011)El equipo de Genesis ProjectBelum ada peringkat
- SOFARSOLAR ModBus-RTU Communication ProtocolDokumen22 halamanSOFARSOLAR ModBus-RTU Communication ProtocolВячеслав ЛарионовBelum ada peringkat
- CH 12 Review Solutions PDFDokumen11 halamanCH 12 Review Solutions PDFOyinkansola OsiboduBelum ada peringkat
- Avh-X8550bt Operating Manual Eng-Esp-PorDokumen7 halamanAvh-X8550bt Operating Manual Eng-Esp-PorRannie IsonBelum ada peringkat
- Gas Turbine Compressor WashingDokumen8 halamanGas Turbine Compressor Washingwolf_ns100% (1)
- AtomDokumen15 halamanAtomdewi murtasimaBelum ada peringkat
- Low Temperature Plastics - EnsingerDokumen4 halamanLow Temperature Plastics - EnsingerAnonymous r3MoX2ZMTBelum ada peringkat
- Pavement Materials - AggregatesDokumen14 halamanPavement Materials - AggregatestombasinghBelum ada peringkat
- Measures of Central Tendency: Mean Median ModeDokumen20 halamanMeasures of Central Tendency: Mean Median ModeRia BarisoBelum ada peringkat
- HPC168 Passenger CounterDokumen9 halamanHPC168 Passenger CounterRommel GómezBelum ada peringkat
- CISCO Router Software - Configuration PDFDokumen408 halamanCISCO Router Software - Configuration PDFasalihovicBelum ada peringkat
- Surface Mount Multilayer Varistor: SC0805ML - SC2220ML SeriesDokumen8 halamanSurface Mount Multilayer Varistor: SC0805ML - SC2220ML SeriesTalebBelum ada peringkat
- Test Bank For Chemistry An Atoms Focused Approach 3rd Edition Thomas R Gilbert Rein V Kirss Stacey Lowery Bretz Natalie FosterDokumen38 halamanTest Bank For Chemistry An Atoms Focused Approach 3rd Edition Thomas R Gilbert Rein V Kirss Stacey Lowery Bretz Natalie Fosterauntyprosperim1ru100% (10)
- 20CB PDFDokumen59 halaman20CB PDFChidiebere Samuel OkogwuBelum ada peringkat
- Valence Bond Theory VBTDokumen32 halamanValence Bond Theory VBTAsif AhnafBelum ada peringkat
- Calculation Eurocode 2Dokumen4 halamanCalculation Eurocode 2rammirisBelum ada peringkat
- Hall 2005 NapaeinaDokumen10 halamanHall 2005 NapaeinaKellyta RodriguezBelum ada peringkat
- DIO 1000 v1.1 - EN Op ManualDokumen25 halamanDIO 1000 v1.1 - EN Op ManualMiguel Ángel Pérez FuentesBelum ada peringkat
- Product Bulletin N 6: Bearing Assemblies - Shaft VariationsDokumen1 halamanProduct Bulletin N 6: Bearing Assemblies - Shaft VariationsRANAIVOARIMANANABelum ada peringkat
- ECE ExperimentDokumen13 halamanECE Experimentasm98090% (1)
- Auto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3Dokumen4 halamanAuto-Tune Pid Temperature & Timer General Specifications: N L1 L2 L3sharawany 20Belum ada peringkat