Anda mungkin juga menyukai
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Pid1402 Pid1502 Pid1602 Pid1702 Pid1402 Pid1502 Pid1702 Pid1602Dokumen2 halamanPid1402 Pid1502 Pid1602 Pid1702 Pid1402 Pid1502 Pid1702 Pid1602musarraf172Belum ada peringkat
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5795)
- SS ZG520 HandoutDokumen7 halamanSS ZG520 Handoutmusarraf172Belum ada peringkat
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- Modern Control Technology Components & Systems (2nd Ed.)Dokumen2 halamanModern Control Technology Components & Systems (2nd Ed.)musarraf172Belum ada peringkat
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- Mechatronics Handout BITSDokumen3 halamanMechatronics Handout BITSmusarraf172Belum ada peringkat
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (588)
- FBL 2360Dokumen14 halamanFBL 2360musarraf172Belum ada peringkat
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (74)
- N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N NDokumen1 halamanN N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N N Nmusarraf172Belum ada peringkat
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Pulse Roller BrochureDokumen6 halamanPulse Roller Brochuremusarraf172100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (895)
- Calculating Earth Strip SizeDokumen4 halamanCalculating Earth Strip Sizemusarraf172Belum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- First Pass Master Tag PDFDokumen14 halamanFirst Pass Master Tag PDFmusarraf172Belum ada peringkat
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (400)
- Interroll Zone Control CardDokumen2 halamanInterroll Zone Control Cardmusarraf172Belum ada peringkat
- SEPIC Project ReportDokumen102 halamanSEPIC Project Reportmusarraf172Belum ada peringkat
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (345)
- OTM Reports FTI Training ManualDokumen78 halamanOTM Reports FTI Training ManualAquib Khan100% (2)
- Civ-Su-6001-C - Design of BuildingsDokumen37 halamanCiv-Su-6001-C - Design of BuildingsBolarinwaBelum ada peringkat
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Cold Rolled Steel Sheet-JFE PDFDokumen32 halamanCold Rolled Steel Sheet-JFE PDFEduardo Javier Granados SanchezBelum ada peringkat
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- 5 6176700143207711706Dokumen198 halaman5 6176700143207711706abc defBelum ada peringkat
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2259)
- ISO - 3601-2 O-Rings HousingDokumen56 halamanISO - 3601-2 O-Rings HousingAlexey FlidliderBelum ada peringkat
- DMIC ProjectDokumen33 halamanDMIC ProjectParminder RaiBelum ada peringkat
- Uses of The Components of Crude Oil As FuelsDokumen6 halamanUses of The Components of Crude Oil As FuelsPearl LawrenceBelum ada peringkat
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (266)
- M.3 Pressure Switches Hex 24: Rohs IiDokumen18 halamanM.3 Pressure Switches Hex 24: Rohs IiSeyedAli TabatabaeeBelum ada peringkat
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- (WWW - Manuallib.com) - MOELLER EASY512&Minus AB&Minus RCDokumen8 halaman(WWW - Manuallib.com) - MOELLER EASY512&Minus AB&Minus RCErik VermaakBelum ada peringkat
- Ic703 ServiceDokumen57 halamanIc703 Servicewalters2Belum ada peringkat
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Data Structure Algorithm Using C PresentationDokumen245 halamanData Structure Algorithm Using C PresentationdhruvwBelum ada peringkat
- En Privacy The Best Reseller SMM Panel, Cheap SEO and PR - MRPOPULARDokumen4 halamanEn Privacy The Best Reseller SMM Panel, Cheap SEO and PR - MRPOPULARZhenyuan LiBelum ada peringkat
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Qualcast 46cm Petrol Self Propelled Lawnmower: Assembly Manual XSZ46D-SDDokumen28 halamanQualcast 46cm Petrol Self Propelled Lawnmower: Assembly Manual XSZ46D-SDmark simpsonBelum ada peringkat
- Exterior Perspective 1: PasuquinDokumen1 halamanExterior Perspective 1: Pasuquinjay-ar barangayBelum ada peringkat
- MET Till DEC 2018 PDFDokumen171 halamanMET Till DEC 2018 PDFt.srinivasanBelum ada peringkat
- VX-1700 Owners ManualDokumen32 halamanVX-1700 Owners ManualVan ThaoBelum ada peringkat
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (121)
- Electrochemical Technologies in Wastewater Treatment PDFDokumen31 halamanElectrochemical Technologies in Wastewater Treatment PDFvahid100% (1)
- Crisfield - Vol1 - NonLinear Finite Element Analysis of Solids and Structures EssentialsDokumen360 halamanCrisfield - Vol1 - NonLinear Finite Element Analysis of Solids and Structures EssentialsAnonymous eCD5ZRBelum ada peringkat
- Course Material Fees: Terms 1190 - 1193Dokumen8 halamanCourse Material Fees: Terms 1190 - 1193Frances Ijeoma ObiakorBelum ada peringkat
- SW Product SummaryDokumen64 halamanSW Product SummaryFabio MenegatoBelum ada peringkat
- 200 Series Service Manual FLX200 & SCR200Dokumen39 halaman200 Series Service Manual FLX200 & SCR200Carlos Gomez100% (3)
- Process Control in SpinningDokumen31 halamanProcess Control in Spinningapi-2649455553% (15)
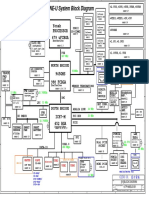
- Clevo M620ne-UDokumen34 halamanClevo M620ne-UHh woo't hoofBelum ada peringkat
- ANSYS Mechanical Basic Structural NonlinearitiesDokumen41 halamanANSYS Mechanical Basic Structural NonlinearitiesalexBelum ada peringkat
- Molinos VerticalesDokumen172 halamanMolinos VerticalesLeonardo RodriguezBelum ada peringkat
- Exterity g44 Serie 1.2 ManualDokumen87 halamanExterity g44 Serie 1.2 Manualruslan20851Belum ada peringkat
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- PeopleSoft Doc UpdateDokumen20 halamanPeopleSoft Doc UpdateupenderBelum ada peringkat
- .Preliminary PagesDokumen12 halaman.Preliminary PagesKimBabBelum ada peringkat
- Heat Rate Calc in ExcelDokumen13 halamanHeat Rate Calc in ExcelMukesh VadaliaBelum ada peringkat
- Excel 2016: Large Data 1 : Sorting and FilteringDokumen19 halamanExcel 2016: Large Data 1 : Sorting and FilteringSapna JoshiBelum ada peringkat