Anda mungkin juga menyukai
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- Mba Business Analytics SyllabusDokumen72 halamanMba Business Analytics SyllabusAnurag ChaturvediBelum ada peringkat
- Data Mining Concepts and TechniquesDokumen136 halamanData Mining Concepts and TechniquesGirish Acharya0% (1)
- Defining Data Science - The What, Where and How of Data Science - 365 Data Science PDFDokumen24 halamanDefining Data Science - The What, Where and How of Data Science - 365 Data Science PDFSəidə ƏlizadəBelum ada peringkat
- Chatterjee & HadiDokumen30 halamanChatterjee & HadiGaurav AtreyaBelum ada peringkat
- Categorical Data Analysis With SAS and SPSS ApplicationsDokumen576 halamanCategorical Data Analysis With SAS and SPSS Applicationsyas100% (1)
- SudansDeepState Final EnoughDokumen64 halamanSudansDeepState Final Enoughc4blue66Belum ada peringkat
- Revolutionary Sudan-TurabiDokumen317 halamanRevolutionary Sudan-Turabic4blue66Belum ada peringkat
- Democracy in Contemporary EgyptDokumen192 halamanDemocracy in Contemporary Egyptc4blue66Belum ada peringkat
- Predictive Model ValidatonDokumen14 halamanPredictive Model Validatonc4blue66Belum ada peringkat
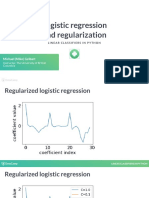
- Logistic Regression and Regularization: Michael (Mike) GelbartDokumen19 halamanLogistic Regression and Regularization: Michael (Mike) GelbartNourheneMbarekBelum ada peringkat
- Use Correct Statistics - Prof Bhisma Murti - 18 Nov 2020Dokumen19 halamanUse Correct Statistics - Prof Bhisma Murti - 18 Nov 2020Ayik M. MandagiBelum ada peringkat
- Nutrients 12 02540Dokumen13 halamanNutrients 12 02540Nishi Dewi RuciBelum ada peringkat
- Working PovertyDokumen172 halamanWorking Povertyapi-232238713Belum ada peringkat
- Predicting Acquisitions in India: ResearchDokumen21 halamanPredicting Acquisitions in India: ResearchAruna RoyBelum ada peringkat
- Jurnal INT 5Dokumen8 halamanJurnal INT 5Ratu Delima PuspitaBelum ada peringkat
- Count Trip Generation ModelsDokumen20 halamanCount Trip Generation ModelsKoti Reddy AlluBelum ada peringkat
- Prehospital Trauma Life Support (PHTLS) Training of Ambulance Caregivers and Impact On Survival of Trauma VictimsDokumen7 halamanPrehospital Trauma Life Support (PHTLS) Training of Ambulance Caregivers and Impact On Survival of Trauma VictimsvenggyBelum ada peringkat
- Fundamentos de Análisis Epidemiológico II: Tipo de alimentación afecta riesgo de enfermedad respiratoriaDokumen23 halamanFundamentos de Análisis Epidemiológico II: Tipo de alimentación afecta riesgo de enfermedad respiratoriaDiego Alejandro Muñoz GaviriaBelum ada peringkat
- Predicting STEM Enrollment Using Data MiningDokumen8 halamanPredicting STEM Enrollment Using Data MiningShuya HideakiBelum ada peringkat
- Taking College Courses in High School: A Strategy For College ReadinessDokumen44 halamanTaking College Courses in High School: A Strategy For College ReadinessScott FolsomBelum ada peringkat
- Investigating The Relationship Between Crash Severity, Traffic Barrier Type, and Vehicle Type in Crashes Involving Traffic BarrierDokumen12 halamanInvestigating The Relationship Between Crash Severity, Traffic Barrier Type, and Vehicle Type in Crashes Involving Traffic BarrierXiaoming YangBelum ada peringkat
- Regression Model Development For Exposure at Default (EAD) : July 2010Dokumen22 halamanRegression Model Development For Exposure at Default (EAD) : July 2010Viktória KónyaBelum ada peringkat
- Assignment Report - Group ADokumen31 halamanAssignment Report - Group Akeerthi reddyBelum ada peringkat
- Statist Bio 2Dokumen390 halamanStatist Bio 2Cristina Liliana TimuBelum ada peringkat
- 2004 Do Conditional Cash Transfers Improve Child Health Evidence From PROGRESA Control Randomized ExperimentDokumen8 halaman2004 Do Conditional Cash Transfers Improve Child Health Evidence From PROGRESA Control Randomized ExperimentnicovonBelum ada peringkat
- Jama Holmberg 2020 GM 200012 1600069989.70491Dokumen2 halamanJama Holmberg 2020 GM 200012 1600069989.70491Raisa Paredes PBelum ada peringkat
- Curiosity and Reward: Valence Predicts Choice and Information Prediction Errors Enhance LearningDokumen7 halamanCuriosity and Reward: Valence Predicts Choice and Information Prediction Errors Enhance LearningGunawan AzisBelum ada peringkat
- Shahnoor Et Al. Yamama Conf PDFDokumen6 halamanShahnoor Et Al. Yamama Conf PDFShahnoor AliBelum ada peringkat
- A Multivariate Model For Analyzing Crime Scene InformationDokumen26 halamanA Multivariate Model For Analyzing Crime Scene InformationNorberth Ioan OkrosBelum ada peringkat
- BSc-IV Econometrics II (ECO 205) Quiz 1 Results and AnalysisDokumen4 halamanBSc-IV Econometrics II (ECO 205) Quiz 1 Results and AnalysisMahnoorBelum ada peringkat
- Research AnalyticsDokumen2 halamanResearch AnalyticsDreamtech Press25% (4)
- Decomposition Analysis of Entrepreneurial Activities in JapanDokumen17 halamanDecomposition Analysis of Entrepreneurial Activities in Japangeorgekirby1138Belum ada peringkat
- Zaragoza EstrésDokumen6 halamanZaragoza EstrésAngelica RodriguezBelum ada peringkat
- NLOGIT Short Student Manual PDFDokumen141 halamanNLOGIT Short Student Manual PDFMM OrvinBelum ada peringkat