Anda mungkin juga menyukai
- Subtracting Multi Digit Numbers Requires Thought | Children's Arithmetic BooksDari EverandSubtracting Multi Digit Numbers Requires Thought | Children's Arithmetic BooksBelum ada peringkat
- Biochemistry TOSDokumen1 halamanBiochemistry TOSEdmike BucogBelum ada peringkat
- 62 Question Test Answer SheetDokumen1 halaman62 Question Test Answer SheetzumiebBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 2tstDokumen1 halamanEcoli 0 1 3 7 - Vs - 2 6 5 2tstMahit Kumar PaulBelum ada peringkat
- Negative numerical data seriesDokumen1 halamanNegative numerical data seriesMahit Kumar PaulBelum ada peringkat
- Radiation Pattern Reading Table: AntennaDokumen2 halamanRadiation Pattern Reading Table: AntennaMahesh MathpatiBelum ada peringkat
- Cate Nary Curve GeneratorDokumen4 halamanCate Nary Curve Generatorchucaronlinegmail.comBelum ada peringkat
- Sra Answer SheetDokumen1 halamanSra Answer SheetYt Prem100% (1)
- Bus Pariwisata Seat 2Dokumen1 halamanBus Pariwisata Seat 2arif NasrullohBelum ada peringkat
- Syllabus Math001-Term 211Dokumen2 halamanSyllabus Math001-Term 211rsm.s1Belum ada peringkat
- danh sách bài tập giải tíchDokumen1 halamandanh sách bài tập giải tíchr84mhtn6wrBelum ada peringkat
- Answer SheetDokumen1 halamanAnswer SheetLevi JokicBelum ada peringkat
- Cobb Egg Weight and Mass ChartDokumen3 halamanCobb Egg Weight and Mass ChartAlbert SupraptoBelum ada peringkat
- 2nd Quarter Science 9 ANSWER SHEETDokumen1 halaman2nd Quarter Science 9 ANSWER SHEETRobert Banaria BasinangBelum ada peringkat
- Tingkat Penghunian Kamar (TPK) Hotel Bintang Tahun 2016 Vs 2015Dokumen1 halamanTingkat Penghunian Kamar (TPK) Hotel Bintang Tahun 2016 Vs 2015Marsel SitinjakBelum ada peringkat
- Mock Nqesh Answer SheetDokumen3 halamanMock Nqesh Answer SheetAlphie TemblorBelum ada peringkat
- Answer SheetDokumen4 halamanAnswer SheetKristela Mae ColomaBelum ada peringkat
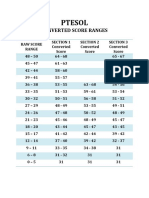
- PTESOL Converted ScoreDokumen1 halamanPTESOL Converted ScorejohnBelum ada peringkat
- PTESOL Converted ScoreDokumen1 halamanPTESOL Converted Scorejohn0% (1)
- Spelling First Term ExaminationDokumen1 halamanSpelling First Term ExaminationTanya HemnaniBelum ada peringkat
- Monographs Society Res Child - 2017 - Verdine - IV Results Links Between Spatial Assembly Later Spatial Skills andDokumen10 halamanMonographs Society Res Child - 2017 - Verdine - IV Results Links Between Spatial Assembly Later Spatial Skills andAslı KAYABelum ada peringkat
- Daftar Nilai CSDokumen4 halamanDaftar Nilai CSDonny KharizmaBelum ada peringkat
- Persentase Wanita Berumur 15-49 Tahun Dan Berstatus Kawin Yang Sedang Menggunakan - Memakai Alat KBDokumen3 halamanPersentase Wanita Berumur 15-49 Tahun Dan Berstatus Kawin Yang Sedang Menggunakan - Memakai Alat KBFerry PrabowoBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 1traDokumen4 halamanEcoli 0 1 3 7 - Vs - 2 6 5 1traMahit Kumar PaulBelum ada peringkat
- A B C D E A B C D E: Ranao Council - Alkhwarizmi International College Accountancy Department Mockboard ExaminationDokumen1 halamanA B C D E A B C D E: Ranao Council - Alkhwarizmi International College Accountancy Department Mockboard ExaminationchimchimcoliBelum ada peringkat
- Chess Score Sheet 1Dokumen1 halamanChess Score Sheet 1IAN CLEO B.TIAPEBelum ada peringkat
- Answer SheetDokumen1 halamanAnswer SheetAnnabeth ChaseBelum ada peringkat
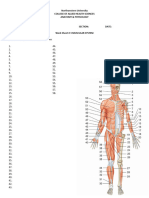
- Muscular System WorksheetDokumen2 halamanMuscular System Worksheetmyraaguinaldo01Belum ada peringkat
- Heat IndexDokumen1 halamanHeat IndexAHMEDMANSOUR56Belum ada peringkat
- Book 1Dokumen8 halamanBook 1Alexander P. BelkaBelum ada peringkat
- Climate ResultDokumen170 halamanClimate ResultisdfjBelum ada peringkat
- Syllabus For MATH 101Dokumen2 halamanSyllabus For MATH 101Ezzat FathyBelum ada peringkat
- Form 1 - Attendance SheetDokumen2 halamanForm 1 - Attendance Sheetkarl_poorBelum ada peringkat
- 3rd Terminal Examination 2nd Year MBBS (Batch 2020)Dokumen2 halaman3rd Terminal Examination 2nd Year MBBS (Batch 2020)kishanBelum ada peringkat
- JRMCU criminology exam answer sheetDokumen2 halamanJRMCU criminology exam answer sheetMarky CieloBelum ada peringkat
- Sample Answer Sheet CSC ExamDokumen2 halamanSample Answer Sheet CSC ExamLorymel Amosin Mayabason Salas0% (1)
- GUJCET Test 3 Answer Key 2021Dokumen1 halamanGUJCET Test 3 Answer Key 2021dhruv kakadiyaBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 5tstDokumen1 halamanEcoli 0 1 3 7 - Vs - 2 6 5 5tstMahit Kumar PaulBelum ada peringkat
- Answer SheetDokumen1 halamanAnswer Sheetlovelyjoy.saplingBelum ada peringkat
- 23set Cut Off Percentage16042022Dokumen1 halaman23set Cut Off Percentage16042022Subham NandiBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 3traDokumen4 halamanEcoli 0 1 3 7 - Vs - 2 6 5 3traMahit Kumar PaulBelum ada peringkat
- Find the pattern math worksheetDokumen1 halamanFind the pattern math worksheetjacwollongongBelum ada peringkat
- Seat BusDokumen7 halamanSeat BusRendi SalendraBelum ada peringkat
- K Subtracting DecimalsDokumen2 halamanK Subtracting DecimalsrandonamBelum ada peringkat
- JT - Question Sheet 1Dokumen1 halamanJT - Question Sheet 1G GBelum ada peringkat
- Gasoline Tax MapDokumen1 halamanGasoline Tax MapSpectrum MediaBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 5traDokumen4 halamanEcoli 0 1 3 7 - Vs - 2 6 5 5traMahit Kumar PaulBelum ada peringkat
- Aseeti Vata Vikara: DR - Jonah, Professor & Head, Dept - of Kayachikitsa, RGAMC-MaheDokumen1 halamanAseeti Vata Vikara: DR - Jonah, Professor & Head, Dept - of Kayachikitsa, RGAMC-MaheThala ThalapatyBelum ada peringkat
- Uas Stat1Dokumen16 halamanUas Stat1Arthur WallacenicholasBelum ada peringkat
- Answer SheetDokumen1 halamanAnswer SheetPhương Nam VuBelum ada peringkat
- BALANCE HIDRICO EjemploDokumen20 halamanBALANCE HIDRICO EjemploJadyCutipaPinoBelum ada peringkat
- Subject-Wise and Category-Wise Cut-Off Percentage of SET - 2018Dokumen1 halamanSubject-Wise and Category-Wise Cut-Off Percentage of SET - 2018Matin AhmedBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 4traDokumen4 halamanEcoli 0 1 3 7 - Vs - 2 6 5 4traMahit Kumar PaulBelum ada peringkat
- Anishish SharanDokumen15 halamanAnishish SharanAnishish SharanBelum ada peringkat
- Hasil DGN Mnggunakan SPSSDokumen14 halamanHasil DGN Mnggunakan SPSSratni ayuBelum ada peringkat
- Ecoli 0 1 3 7 - Vs - 2 6 5 4tstDokumen1 halamanEcoli 0 1 3 7 - Vs - 2 6 5 4tstMahit Kumar PaulBelum ada peringkat
- Aakash National Talent Hunt Exam 2019: AnswersDokumen1 halamanAakash National Talent Hunt Exam 2019: AnswersPugalmeena PugalmeenaBelum ada peringkat
- Speed Archive Test-6 - Answer KeyDokumen1 halamanSpeed Archive Test-6 - Answer Keysam.gamer.sg.opBelum ada peringkat
- Factorial Design DataDokumen12 halamanFactorial Design Datayasir83Belum ada peringkat
- (1104265) - Práctica #2 - Análisis MultivarianteDokumen147 halaman(1104265) - Práctica #2 - Análisis MultivarianteNataly SánBelum ada peringkat
- Data 1Dokumen1 halamanData 1Rossy Dinda PratiwiBelum ada peringkat
- Teamviewer9 Manual Managementconsole en PDFDokumen45 halamanTeamviewer9 Manual Managementconsole en PDFRossy Dinda PratiwiBelum ada peringkat
- Motivational Moments 2Dokumen321 halamanMotivational Moments 2Rashid Ahmad100% (2)
- Package NMF': August 1, 2020Dokumen191 halamanPackage NMF': August 1, 2020Rossy Dinda PratiwiBelum ada peringkat
- Building Gui Using AccessDokumen14 halamanBuilding Gui Using AccessMohamed AbdelBasetBelum ada peringkat
- NMF Vignette PDFDokumen36 halamanNMF Vignette PDFRossy Dinda PratiwiBelum ada peringkat
- 100 Excel Tips - EwB PDFDokumen106 halaman100 Excel Tips - EwB PDFAbhijit SahaBelum ada peringkat
- Holidays PDFDokumen3 halamanHolidays PDFRossy Dinda PratiwiBelum ada peringkat
- iflix Premieres Mystery Drama And Then There Were None in MalaysiaDokumen3 halamaniflix Premieres Mystery Drama And Then There Were None in MalaysiaRossy Dinda PratiwiBelum ada peringkat
- GraficDokumen2 halamanGraficGustavoBelum ada peringkat
- The Technological State in Indonesia (Ebook) PDFDokumen209 halamanThe Technological State in Indonesia (Ebook) PDFRossy Dinda PratiwiBelum ada peringkat
- Dewa19 Cinta Kan Membawamu Ke PDFDokumen5 halamanDewa19 Cinta Kan Membawamu Ke PDFZulfikri LatiefBelum ada peringkat
- Package NMF': August 1, 2020Dokumen191 halamanPackage NMF': August 1, 2020Rossy Dinda PratiwiBelum ada peringkat
- Holidays PDFDokumen3 halamanHolidays PDFRossy Dinda PratiwiBelum ada peringkat
- GraficDokumen2 halamanGraficGustavoBelum ada peringkat
- GraficDokumen2 halamanGraficGustavoBelum ada peringkat
- R For Data Science Cheat Sheet Tidyverse OverviewDokumen1 halamanR For Data Science Cheat Sheet Tidyverse OverviewJose AGBelum ada peringkat
- Customer Clustering Based On Customer Purchasing Sequence DataDokumen10 halamanCustomer Clustering Based On Customer Purchasing Sequence DataRossy Dinda PratiwiBelum ada peringkat
- Zijlema Lecturenotes ODE and SWEDokumen136 halamanZijlema Lecturenotes ODE and SWERossy Dinda PratiwiBelum ada peringkat
- PDE Solvable As ODE - PartCDokumen1 halamanPDE Solvable As ODE - PartCRossy Dinda PratiwiBelum ada peringkat
- 15Dokumen6 halaman15Rossy Dinda PratiwiBelum ada peringkat
- Control CourseDokumen126 halamanControl CourseDang Hai NguyenBelum ada peringkat
- Vol4 - Iss2 - 172 - 181 - Developing - A - Model - For - Measuring - Cu PDFDokumen10 halamanVol4 - Iss2 - 172 - 181 - Developing - A - Model - For - Measuring - Cu PDFRossy Dinda PratiwiBelum ada peringkat
- Artforum PDFDokumen23 halamanArtforum PDFRossy Dinda PratiwiBelum ada peringkat
- IM 10 Muhammad Ridwan Andi Purnomo 2015Dokumen8 halamanIM 10 Muhammad Ridwan Andi Purnomo 2015Rossy Dinda PratiwiBelum ada peringkat
- Accenture Customer Insights V2 PDFDokumen16 halamanAccenture Customer Insights V2 PDFRossy Dinda PratiwiBelum ada peringkat
- Machine Learning With Python/Scikit-Learn: - Application To The Estimation of Occupancy and Human ActivitiesDokumen113 halamanMachine Learning With Python/Scikit-Learn: - Application To The Estimation of Occupancy and Human Activitiesdilip_thimiriBelum ada peringkat
- Artforum PDFDokumen23 halamanArtforum PDFRossy Dinda PratiwiBelum ada peringkat
- V1 N2 Paper 16Dokumen5 halamanV1 N2 Paper 16Rossy Dinda PratiwiBelum ada peringkat
- Data Analysis With Python: An IntroductionDokumen37 halamanData Analysis With Python: An IntroductionRrohit DubeyBelum ada peringkat
- A Synopsis Submitted For The Degree ofDokumen21 halamanA Synopsis Submitted For The Degree ofAakash KaushikBelum ada peringkat
- Business ResearchDokumen2 halamanBusiness ResearchGeleen CantosBelum ada peringkat
- PSF For Resistance of Steel Frames To Ec3 Ec4Dokumen155 halamanPSF For Resistance of Steel Frames To Ec3 Ec4Daniel JamesBelum ada peringkat
- Solution Manual To Engineering Mechanics StaticsDokumen6 halamanSolution Manual To Engineering Mechanics StaticsTony17% (18)
- Model R R Square Adjusted R Square Std. Error of The Estimate 1, 892, 723, 47657Dokumen2 halamanModel R R Square Adjusted R Square Std. Error of The Estimate 1, 892, 723, 47657Tarina nandaBelum ada peringkat
- Aleksandra Vuletic, Censuse in 19th Century in SerbiaDokumen25 halamanAleksandra Vuletic, Censuse in 19th Century in SerbiaDejan ZivanovicBelum ada peringkat
- Sih 11 376Dokumen9 halamanSih 11 376RifqanfBelum ada peringkat
- Introduction To Information Theory Channel Capacity and ModelsDokumen30 halamanIntroduction To Information Theory Channel Capacity and Models文李Belum ada peringkat
- Bayes TheoremDokumen4 halamanBayes TheoremCaptain rebornBelum ada peringkat
- An Introduction To Regression AnalysisDokumen34 halamanAn Introduction To Regression AnalysisNikhil SinghBelum ada peringkat
- Panel Data ModelsDokumen112 halamanPanel Data ModelsAlemuBelum ada peringkat
- Bernoulli Experiments and Binomial Distribution ExplainedDokumen29 halamanBernoulli Experiments and Binomial Distribution ExplainedÇháråñ ÇhèrryBelum ada peringkat
- Unit 4 (STATISTICAL ESTIMATION AND SMALL SAMPLING THEORIES )Dokumen26 halamanUnit 4 (STATISTICAL ESTIMATION AND SMALL SAMPLING THEORIES )Zara NabilahBelum ada peringkat
- Getting Grounded On AnalyticsDokumen31 halamanGetting Grounded On AnalyticsIvan Jon Ferriol100% (2)
- Neural CorrelatesDokumen5 halamanNeural CorrelatesFábio Henrique AraújoBelum ada peringkat
- Predicting Accident Susceptibility: A Logistic Regression Analysis of Underground Coal Mine WorkersDokumen6 halamanPredicting Accident Susceptibility: A Logistic Regression Analysis of Underground Coal Mine WorkersDr-Rabia AlmamalookBelum ada peringkat
- Measures of Dispersion: Unit 1 Part 3Dokumen33 halamanMeasures of Dispersion: Unit 1 Part 3KamalSatijaBelum ada peringkat
- Ebook PDF Research Methods in Psychology 5th EditioDownload Ebook Ebook PDF Research Methods in Psychology 5th Edition PDFDokumen41 halamanEbook PDF Research Methods in Psychology 5th EditioDownload Ebook Ebook PDF Research Methods in Psychology 5th Edition PDFadelaida.demars502100% (34)
- Machine LearningDokumen136 halamanMachine LearningKenssy100% (2)
- Multiple Regression: Problem Set 7Dokumen3 halamanMultiple Regression: Problem Set 7ArkaBelum ada peringkat
- B.Sc. (Statistics) 1st To 6th Sem 2016-17 Modified - 25 - 7 - 17 PDFDokumen19 halamanB.Sc. (Statistics) 1st To 6th Sem 2016-17 Modified - 25 - 7 - 17 PDFAyush ParmarBelum ada peringkat
- Stata 2Dokumen11 halamanStata 2Chu BundyBelum ada peringkat
- Prelim Lesson 1-3Dokumen50 halamanPrelim Lesson 1-3Lourdios EdullantesBelum ada peringkat
- Chapter 1 4Dokumen76 halamanChapter 1 4Sean Suing100% (1)
- Chapter 2 Random VariablesDokumen41 halamanChapter 2 Random Variableshoa.tranquangducBelum ada peringkat
- Research Paper On Panel Data AnalysisDokumen5 halamanResearch Paper On Panel Data Analysisjolowomykit2100% (1)
- Modelling and Trading The EUR/USD Exchange Rate at The ECB FixingDokumen25 halamanModelling and Trading The EUR/USD Exchange Rate at The ECB FixingSergio Santos VillamilBelum ada peringkat
- Statistics Made Easy PresentationDokumen226 halamanStatistics Made Easy PresentationHariomMaheshwariBelum ada peringkat
- ThesisDokumen21 halamanThesisJonathan Delos SantosBelum ada peringkat
- Perez SLACDokumen16 halamanPerez SLACMarvz Leo100% (1)