Anda mungkin juga menyukai
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedDari EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedBelum ada peringkat
- Tip DS On HadoopDokumen14 halamanTip DS On HadoopVũ Hà Nam100% (1)
- Lab1 InstallationOfBigInsightDokumen72 halamanLab1 InstallationOfBigInsightBrijesh KumarBelum ada peringkat
- BDA Lab Manual-1Dokumen60 halamanBDA Lab Manual-1pavan chittalaBelum ada peringkat
- Session Title: Bob Johnston / IPS Grid & HA SolutionsDokumen31 halamanSession Title: Bob Johnston / IPS Grid & HA Solutionsnirmal_itBelum ada peringkat
- Industrial TrainingDokumen17 halamanIndustrial TrainingSandeep GhoshBelum ada peringkat
- Bda PracticalDokumen62 halamanBda Practicalvijay kholiaBelum ada peringkat
- Implementing A Highly Available Oracle Ebs A Highly AvailableDokumen57 halamanImplementing A Highly Available Oracle Ebs A Highly AvailablenizamBelum ada peringkat
- Module - 4-2Dokumen32 halamanModule - 4-2Raj KumarBelum ada peringkat
- MR YARN - Lab 1 - Cloud - Updated-V2.0Dokumen30 halamanMR YARN - Lab 1 - Cloud - Updated-V2.0BPSMB SulselBelum ada peringkat
- Spart Part 2Dokumen44 halamanSpart Part 2Aleena Nasir100% (1)
- Data and MetadataDokumen15 halamanData and MetadataJosuéLMBelum ada peringkat
- UCS BootCamp PDFDokumen306 halamanUCS BootCamp PDFtorrezmBelum ada peringkat
- Google Cloud Network Engineer Exam Prep SheetDokumen15 halamanGoogle Cloud Network Engineer Exam Prep Sheethilman mustofaBelum ada peringkat
- Ututorial of Hadoop Installation On Linux UbuntuDokumen20 halamanUtutorial of Hadoop Installation On Linux Ubuntuthis is riaBelum ada peringkat
- Describe The Functions and Features of HDPDokumen16 halamanDescribe The Functions and Features of HDPMahmoud Elmahdy100% (2)
- Entel - RAID Integrator Training - Day 1 InstallationDokumen59 halamanEntel - RAID Integrator Training - Day 1 Installationfelipito74Belum ada peringkat
- Part 03 Intro To HadoopDokumen22 halamanPart 03 Intro To HadoopSahera ShabnamBelum ada peringkat
- BlueData EPIC Software Architecture Technical White PaperDokumen29 halamanBlueData EPIC Software Architecture Technical White PaperRajesh ShenoyBelum ada peringkat
- BDA Module2 Hadoop EcosystemDokumen41 halamanBDA Module2 Hadoop EcosystemPrarthana Manavi100% (1)
- Chapter 2 Introduction To HadoopDokumen31 halamanChapter 2 Introduction To Hadoopshubham.ojha2102Belum ada peringkat
- Basic Network ConfigurationDokumen11 halamanBasic Network ConfigurationdelantotzBelum ada peringkat
- How To Install and Set Up A 3-Node Hadoop ClusterDokumen36 halamanHow To Install and Set Up A 3-Node Hadoop ClusterFernovy GesnerBelum ada peringkat
- Elden Christensen - Principal Program Manager Lead - Microsoft Symon Perriman - Vice President - 5nine SoftwareDokumen34 halamanElden Christensen - Principal Program Manager Lead - Microsoft Symon Perriman - Vice President - 5nine Softwarekranthi macharapuBelum ada peringkat
- Data W - Bigdata8Dokumen105 halamanData W - Bigdata8ujjwal subediBelum ada peringkat
- DataStage Knowledge TransferDokumen4 halamanDataStage Knowledge TransferMadhu SrinivasanBelum ada peringkat
- HDFS 79Dokumen74 halamanHDFS 79bhargaviBelum ada peringkat
- WarehouseDB On VM Think - 2019 - Speaker - 08102018-V3Dokumen20 halamanWarehouseDB On VM Think - 2019 - Speaker - 08102018-V3Vũ Hà NamBelum ada peringkat
- Installation and Architecture - 2019v2Dokumen32 halamanInstallation and Architecture - 2019v2abdiel AlveoBelum ada peringkat
- Gold Video Task CompltedDokumen31 halamanGold Video Task Compltedsrinivas75kBelum ada peringkat
- Shortnotes For CloudDokumen22 halamanShortnotes For CloudMahi MahiBelum ada peringkat
- Position: Target Companies: Customer Service Engineer - Platform Aix, Pseries Ibm, Maple, LocuzDokumen4 halamanPosition: Target Companies: Customer Service Engineer - Platform Aix, Pseries Ibm, Maple, LocuzIla IlanBelum ada peringkat
- DAN Lab ManuaLDokumen53 halamanDAN Lab ManuaLSARANYA ABelum ada peringkat
- Analysing Disk Performance Using Disk WatcherDokumen49 halamanAnalysing Disk Performance Using Disk WatchermagiciancBelum ada peringkat
- Active Directory FunctionsDokumen3 halamanActive Directory FunctionsDayakar MeruguBelum ada peringkat
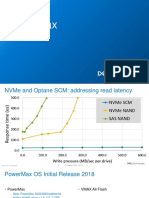
- Powermax Code Release InfoDokumen26 halamanPowermax Code Release InfoPavan NavBelum ada peringkat
- Cloudera Data Platform Private Cloud Base With IBM Spectrum ScaleDokumen42 halamanCloudera Data Platform Private Cloud Base With IBM Spectrum ScalecmkgroupBelum ada peringkat
- Ammett Williams Google Cloud NetworkDokumen12 halamanAmmett Williams Google Cloud Networkmatt streamBelum ada peringkat
- Google Cloud Professional: Cloud Network Engineer ExamDokumen12 halamanGoogle Cloud Professional: Cloud Network Engineer Exammatt streamBelum ada peringkat
- Storage - DS8K HA Best Practices - v1.9Dokumen27 halamanStorage - DS8K HA Best Practices - v1.9luweinetBelum ada peringkat
- Apache Hadoop Next Generation Compute Platform: Bikas Saha @bikassahaDokumen22 halamanApache Hadoop Next Generation Compute Platform: Bikas Saha @bikassahaRohitBelum ada peringkat
- 2018 IBM Systems Technical University: 22-26 Oct Rome, ItalyDokumen28 halaman2018 IBM Systems Technical University: 22-26 Oct Rome, ItalyAhmedBelum ada peringkat
- Leçon4 Hadoop Query LanguagesDokumen21 halamanLeçon4 Hadoop Query LanguagesMido proBelum ada peringkat
- MapReduce Component DesignDokumen5 halamanMapReduce Component DesignArivumathiBelum ada peringkat
- Most Importa NT Interview Question LinuxDokumen36 halamanMost Importa NT Interview Question LinuxbrutalxropBelum ada peringkat
- Nimble: By: Sakaanaa.M, 2017115583 GeneralDokumen13 halamanNimble: By: Sakaanaa.M, 2017115583 GeneralSakaanaa MohanBelum ada peringkat
- Sl. No. Steps: 1 Preparation of Server (VM Validation)Dokumen20 halamanSl. No. Steps: 1 Preparation of Server (VM Validation)Sourav SinghBelum ada peringkat
- Bda A2Dokumen17 halamanBda A2Deepti AgrawalBelum ada peringkat
- DABD AssignmentsDokumen9 halamanDABD Assignmentsdillip singhBelum ada peringkat
- 1-IBM Cloud PrivateDokumen66 halaman1-IBM Cloud PrivateMarijo BlaškanBelum ada peringkat
- 3 Build It - Introduction To IaaSDokumen44 halaman3 Build It - Introduction To IaaSKulbeer SinghBelum ada peringkat
- 11 TSM v5r4 NewsDokumen21 halaman11 TSM v5r4 NewsVajrala SreekanthBelum ada peringkat
- Step by Step Guideline For Building Running Hello World Hibernate ApplicationDokumen22 halamanStep by Step Guideline For Building Running Hello World Hibernate ApplicationmaripositaxBelum ada peringkat
- IBM Data Movement ToolDokumen12 halamanIBM Data Movement ToolGiancarlo Cuadros SolanoBelum ada peringkat
- Resume of MD Saiful HyderDokumen4 halamanResume of MD Saiful Hyderimtheboss*Belum ada peringkat
- Advances in Topographic Mapping ProgrammeDokumen2 halamanAdvances in Topographic Mapping ProgrammeMiloš BasarićBelum ada peringkat
- Data Organization - Why Are There So Many Roles - by Furcy Pin - YounitedTechDokumen9 halamanData Organization - Why Are There So Many Roles - by Furcy Pin - YounitedTechybBelum ada peringkat
- Deepa CVDokumen2 halamanDeepa CVShrutee PatilBelum ada peringkat
- First Exam - System Analysis and DesignDokumen2 halamanFirst Exam - System Analysis and DesignRod S Pangantihon Jr.0% (1)
- ASUG IL Presentation - Kellogg SymphonyDokumen36 halamanASUG IL Presentation - Kellogg SymphonySushmita Ghosh Biswas100% (1)
- Mcgraw-Hill/Irwin © 2006 The Mcgraw-Hill Companies, Inc., All Rights ReservedDokumen28 halamanMcgraw-Hill/Irwin © 2006 The Mcgraw-Hill Companies, Inc., All Rights ReservedRizky AdrianBelum ada peringkat
- Fake Social Media I'D Detection: Prof. Sushma Khatri Tushar SakargayanDokumen9 halamanFake Social Media I'D Detection: Prof. Sushma Khatri Tushar SakargayanSâçhín ShahBelum ada peringkat
- Fortinet Recertified ISO 9001:2011 Certification For High Standards of Quality ManagementDokumen2 halamanFortinet Recertified ISO 9001:2011 Certification For High Standards of Quality ManagementJulian Ernesto Martinez OlivaBelum ada peringkat
- Installing Enterprise Management V12Dokumen9 halamanInstalling Enterprise Management V12fsussanBelum ada peringkat
- Forgot Password Link On Apps Login PageDokumen3 halamanForgot Password Link On Apps Login Pagetushar43Belum ada peringkat
- Con Dump 000Dokumen12 halamanCon Dump 000ayudi septianBelum ada peringkat
- 04 Understanding Corporate LingoDokumen43 halaman04 Understanding Corporate LingoPatrick HugoBelum ada peringkat
- Natural Language Processing (NLP) - Developer GuidesDokumen4 halamanNatural Language Processing (NLP) - Developer GuidesSalton GerardBelum ada peringkat
- C.pa.00 TDI - DPM-2018 Privacy Impact Assessment - Sales Department - v2Dokumen16 halamanC.pa.00 TDI - DPM-2018 Privacy Impact Assessment - Sales Department - v2Nikko Carlo De LeonBelum ada peringkat
- Project Report On Data Transmission Using Multitasking SocketDokumen36 halamanProject Report On Data Transmission Using Multitasking SocketAwadheshKSingh100% (3)
- SSH Tunneling in Your ApplicationDokumen9 halamanSSH Tunneling in Your ApplicationNizar AchmadBelum ada peringkat
- Sample Data Centre Audit Report - DISA Lab Report 22.7.21 Vers 2Dokumen36 halamanSample Data Centre Audit Report - DISA Lab Report 22.7.21 Vers 2Abin ManuelBelum ada peringkat
- OBIEE 11g Assessment Datasheet PDFDokumen2 halamanOBIEE 11g Assessment Datasheet PDFSrikanth RoddaBelum ada peringkat
- 04 Data Modeling Advanced ConceptsDokumen34 halaman04 Data Modeling Advanced ConceptsSharifah AmizaBelum ada peringkat
- Project Proposal: COMSATS University Islamabad, Park Road, Chak Shahzad, Islamabad PakistanDokumen22 halamanProject Proposal: COMSATS University Islamabad, Park Road, Chak Shahzad, Islamabad PakistanEmma KhanBelum ada peringkat
- Lectures32606 31061 SixDokumen60 halamanLectures32606 31061 SixSucharita SahaBelum ada peringkat
- M2: Memory Management: Binding of Instructions and Data To MemoryDokumen3 halamanM2: Memory Management: Binding of Instructions and Data To Memory왕JΔIRΩBelum ada peringkat
- Identity-Based Distributed Provable Data Possession in Multi-Cloud Storage - Services ComputingDokumen16 halamanIdentity-Based Distributed Provable Data Possession in Multi-Cloud Storage - Services ComputingLeMeniz InfotechBelum ada peringkat
- A Project Report On "Payroll Management System"Dokumen48 halamanA Project Report On "Payroll Management System"harsh talpadaBelum ada peringkat
- Mail ServerDokumen25 halamanMail ServervinodBelum ada peringkat
- Network SimuDokumen3 halamanNetwork SimuvalicuinfoBelum ada peringkat
- Cehv11 Labs Module 12-Evading Ids, Firewalls, and Honeypots: ScenarioDokumen103 halamanCehv11 Labs Module 12-Evading Ids, Firewalls, and Honeypots: ScenarioSaubhagya IRIBLBelum ada peringkat
- WhitePaper Riverbed TechRequirements RFPDokumen9 halamanWhitePaper Riverbed TechRequirements RFPKevin WhitneyBelum ada peringkat
- Less15 Backups TB3Dokumen22 halamanLess15 Backups TB3MakokhanBelum ada peringkat
- AnswerDokumen10 halamanAnswerSurekhaben Shah56% (9)