Anda mungkin juga menyukai
- BOURBAKIDokumen26 halamanBOURBAKICEPRE-FISMABelum ada peringkat
- Feigenbaum ConstantsDokumen4 halamanFeigenbaum ConstantsGiannis Pardalis100% (1)
- Q Learning Java Ex2Dokumen4 halamanQ Learning Java Ex2liliana_sfarBelum ada peringkat
- 492 Study Report: Engin Deniz Alpman June 2, 2017Dokumen29 halaman492 Study Report: Engin Deniz Alpman June 2, 2017yuyiipBelum ada peringkat
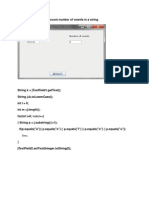
- Program To Convert Infix To Prefix Expression Using StackDokumen5 halamanProgram To Convert Infix To Prefix Expression Using Stackraj22067Belum ada peringkat
- Int Insertnumeric 0 Package ControlDokumen158 halamanInt Insertnumeric 0 Package ControlTuân LêBelum ada peringkat
- DAA LabprogsDokumen17 halamanDAA LabprogsZeha 1Belum ada peringkat
- ScriptsDokumen8 halamanScriptsranjithgottimukkalaBelum ada peringkat
- DAA Lab ProgramsDokumen26 halamanDAA Lab ProgramsV ManjunathBelum ada peringkat
- Function Return: //setam Proprietatile Fiecarui ObiectDokumen10 halamanFunction Return: //setam Proprietatile Fiecarui ObiectKrom VladimirBelum ada peringkat
- HW 5Dokumen12 halamanHW 5api-446897780Belum ada peringkat
- Objective: - Theory:-: Artificial Intelligence (Cs-1771)Dokumen28 halamanObjective: - Theory:-: Artificial Intelligence (Cs-1771)natinBelum ada peringkat
- 20IT116 Viraj Patoliya Practical 2Dokumen11 halaman20IT116 Viraj Patoliya Practical 2D21IT171 Jethwa Harshal KiritbhaiBelum ada peringkat
- Write A Program For Imlementing Perceptron Learning AlgorithmDokumen17 halamanWrite A Program For Imlementing Perceptron Learning AlgorithmHemant Panwar100% (1)
- מטלת בית 9 - הקצאה דינאמיתDokumen5 halamanמטלת בית 9 - הקצאה דינאמיתEvellina YurkovskiyBelum ada peringkat
- MessageDokumen3 halamanMessagemrtruongpk16Belum ada peringkat
- SortingDokumen3 halamanSortingAN NGUYỄN QUỐCBelum ada peringkat
- Google Test Framework PublicDokumen40 halamanGoogle Test Framework Publicultran1Belum ada peringkat
- Problem Set 1Dokumen15 halamanProblem Set 1Muhammad HamzaBelum ada peringkat
- Java Lab3Dokumen20 halamanJava Lab3rosh naBelum ada peringkat
- Indian Institute of Technology Delhi: Submitted byDokumen13 halamanIndian Institute of Technology Delhi: Submitted byRajeev PandeyBelum ada peringkat
- Peg Solitaire GameDokumen10 halamanPeg Solitaire GameKsheerod ToshniwalBelum ada peringkat
- Assignment02 21103085 Atul Kumar Gupta ADADokumen5 halamanAssignment02 21103085 Atul Kumar Gupta ADAbt21103085 Atul Kumar GuptaBelum ada peringkat
- CTDLDokumen5 halamanCTDLvinh20002000Belum ada peringkat
- Getting Started With Reinforcement Learning and Open AI GymDokumen10 halamanGetting Started With Reinforcement Learning and Open AI GymKSDBelum ada peringkat
- N Steps in Exactly M Jumps. Derive A Recurrence Relation For C (N, M), and Write A RecursiveDokumen9 halamanN Steps in Exactly M Jumps. Derive A Recurrence Relation For C (N, M), and Write A RecursiveAnand ThakkarBelum ada peringkat
- Rummy Card Game: CS351 - Artificial Intelligence Rida-e-Fatima 2012314 Zainub Wahid 2012420Dokumen11 halamanRummy Card Game: CS351 - Artificial Intelligence Rida-e-Fatima 2012314 Zainub Wahid 2012420Farooq AzamBelum ada peringkat
- CONM ProgramsDokumen54 halamanCONM Programsvnchougule8738Belum ada peringkat
- Java Assisgnment Solution: Q6Dokumen7 halamanJava Assisgnment Solution: Q6Aditya UpadhyayBelum ada peringkat
- Code:-: Name: Afzal PathanDokumen9 halamanCode:-: Name: Afzal PathanANDHAVARAPU MANOJ SAIBelum ada peringkat
- Computer Science WorksheetDokumen10 halamanComputer Science WorksheetAman sehgalBelum ada peringkat
- Imp NotesDokumen12 halamanImp Notesbc200403674Belum ada peringkat
- Con Reinforcement Aug Dec 2020Dokumen52 halamanCon Reinforcement Aug Dec 2020acer asusBelum ada peringkat
- Daa 4th and 5th PRGDokumen6 halamanDaa 4th and 5th PRGAdityavk GshanbhagBelum ada peringkat
- Code Exp-4Dokumen7 halamanCode Exp-4Aakashdeep SinghBelum ada peringkat
- Codes FinalDokumen8 halamanCodes FinalRaniel Gere GregorioBelum ada peringkat
- Sadar Patel College of Engineering, BakrolDokumen31 halamanSadar Patel College of Engineering, BakrolNirmalBelum ada peringkat
- Write A Program To Check Whether The String Belongs To The Grammar or NotDokumen33 halamanWrite A Program To Check Whether The String Belongs To The Grammar or NotJitender GargBelum ada peringkat
- WAP in C To Implement Shortest Path by Dijkstra AlgorithmDokumen7 halamanWAP in C To Implement Shortest Path by Dijkstra AlgorithmAnkur GuptaBelum ada peringkat
- Actividad 11 Neurona ArtificialDokumen9 halamanActividad 11 Neurona ArtificialHenryredcoat 2005Belum ada peringkat
- Submitted To: Submited byDokumen45 halamanSubmitted To: Submited byHaspreet SinghBelum ada peringkat
- TM - Assignment (3 Files Merged)Dokumen17 halamanTM - Assignment (3 Files Merged)Robiul Alam RobinBelum ada peringkat
- Store 1Dokumen12 halamanStore 1HuyCườngBelum ada peringkat
- Class: Weight Elevator Floor VertexadjDokumen25 halamanClass: Weight Elevator Floor VertexadjAlex FernandesBelum ada peringkat
- 2-D Ising Model SimulationDokumen11 halaman2-D Ising Model Simulationakhilesh_353859963Belum ada peringkat
- Job Sequencing and OptimizationDokumen13 halamanJob Sequencing and OptimizationFY20J1029 Gaurav ShelkeBelum ada peringkat
- SADAR PATEL: BFS and DFS Tic Tac Toe and Water Jug ProblemsDokumen31 halamanSADAR PATEL: BFS and DFS Tic Tac Toe and Water Jug ProblemsNirmalBelum ada peringkat
- SBB's UserScript to Make Tanks More Powerful in diep.ioDokumen4 halamanSBB's UserScript to Make Tanks More Powerful in diep.ioFranciscoBelum ada peringkat
- GC Exercitiu 2Dokumen3 halamanGC Exercitiu 2Caraman CatalinaBelum ada peringkat
- Netflix HomepageDokumen107 halamanNetflix HomepageAzulejoBelum ada peringkat
- Stock Class and Main ProgramDokumen7 halamanStock Class and Main ProgramKhaled HaniaBelum ada peringkat
- DSA Assignment 1Dokumen7 halamanDSA Assignment 1Noor ul AinBelum ada peringkat
- Matrix Inversion Using Gauss-Jordan Method in CDokumen4 halamanMatrix Inversion Using Gauss-Jordan Method in CJoyson SilvaBelum ada peringkat
- Ass 2Dokumen4 halamanAss 2Akash SahuBelum ada peringkat
- Algorithms Laboratory: Department of MCADokumen32 halamanAlgorithms Laboratory: Department of MCARakshitha RakshuuBelum ada peringkat
- All Hpc ProgramsDokumen16 halamanAll Hpc Programsaditya kambleBelum ada peringkat
- AnsweDokumen11 halamanAnsweFiro TaBelum ada peringkat
- Inderpal Singh - 101903343 - CompilerDokumen19 halamanInderpal Singh - 101903343 - CompilerInderpal SinghBelum ada peringkat
- Cheat_SheetDokumen14 halamanCheat_SheetQing Hong BoonBelum ada peringkat
- Practical Questions NetbeansDokumen16 halamanPractical Questions NetbeansAnonymous MjmbYlloBelum ada peringkat
- MOO in ManetDokumen13 halamanMOO in ManetGuru MekalaBelum ada peringkat
- Connectivity Vs TX Rane Vs Density PDFDokumen4 halamanConnectivity Vs TX Rane Vs Density PDFGuru MekalaBelum ada peringkat
- Bonnmotion - A Mobility Scenario Generation and Analysis ToolDokumen10 halamanBonnmotion - A Mobility Scenario Generation and Analysis ToolGuru MekalaBelum ada peringkat
- 2013 13 LibmanDokumen30 halaman2013 13 LibmanGuru MekalaBelum ada peringkat
- BonnMotion DocuDokumen31 halamanBonnMotion DocuganeshsairamBelum ada peringkat
- Comparative Study Waypoint The Evaluation: Random and Gauss-Markov Models Performance ofDokumen6 halamanComparative Study Waypoint The Evaluation: Random and Gauss-Markov Models Performance ofGuru MekalaBelum ada peringkat
- Li/FeS2 Battery Performance and ChemistryDokumen22 halamanLi/FeS2 Battery Performance and ChemistrypaulBelum ada peringkat
- Vehicle and Commercial Controls: Electrical Sector SolutionsDokumen197 halamanVehicle and Commercial Controls: Electrical Sector SolutionsVanderCastroBelum ada peringkat
- Ashrae Ashraejournal 2020.12Dokumen135 halamanAshrae Ashraejournal 2020.12Joao MoreiraBelum ada peringkat
- Nonlinear Control - An Overview: Fernando Lobo Pereira, Flp@fe - Up.ptDokumen57 halamanNonlinear Control - An Overview: Fernando Lobo Pereira, Flp@fe - Up.ptSteve DemirelBelum ada peringkat
- Sap StoDokumen7 halamanSap StoPavilion67% (3)
- Milgrams Experiment On Obedience To AuthorityDokumen2 halamanMilgrams Experiment On Obedience To Authorityapi-233605868Belum ada peringkat
- MGEC61 - LEC 01 & LEC 02 International Economics: Finance Summer 2021Dokumen8 halamanMGEC61 - LEC 01 & LEC 02 International Economics: Finance Summer 2021Yutong WangBelum ada peringkat
- Philip B. Crosby: Quality Guru Who Pioneered Zero Defects ConceptDokumen29 halamanPhilip B. Crosby: Quality Guru Who Pioneered Zero Defects Conceptphdmaker100% (1)
- Registration Form: National Hospital Insurance FundDokumen5 halamanRegistration Form: National Hospital Insurance FundOgweno OgwenoBelum ada peringkat
- Steps To Design A PCB Using OrcadDokumen3 halamanSteps To Design A PCB Using OrcadkannanvivekananthaBelum ada peringkat
- Stranger PaperDokumen3 halamanStranger Paperellie haBelum ada peringkat
- Math 362, Problem Set 5Dokumen4 halamanMath 362, Problem Set 5toancaoBelum ada peringkat
- WorkshopDokumen4 halamanWorkshopAmit GuptaBelum ada peringkat
- Sustainable Urban Transport Index for Bhopal, IndiaDokumen43 halamanSustainable Urban Transport Index for Bhopal, IndiaSayani MandalBelum ada peringkat
- Iron and Steel ReviewDokumen2 halamanIron and Steel ReviewSajal SinghBelum ada peringkat
- Manual Controlador C90Dokumen442 halamanManual Controlador C90Fabián MejíaBelum ada peringkat
- Section 05120 Structural Steel Part 1Dokumen43 halamanSection 05120 Structural Steel Part 1jacksondcplBelum ada peringkat
- Making A StandDokumen22 halamanMaking A StandQueens Nallic Cillan100% (2)
- Aimcat 2201Dokumen29 halamanAimcat 2201Anshul YadavBelum ada peringkat
- Physical Properties of SolutionsDokumen23 halamanPhysical Properties of Solutions董青天Belum ada peringkat
- ASTM D 3044 - 94 (Reapproved 2000) Shear Modulus of Wood-Based Structural PanelsDokumen3 halamanASTM D 3044 - 94 (Reapproved 2000) Shear Modulus of Wood-Based Structural Panelsalin2005Belum ada peringkat
- Interview@InfosysDokumen13 halamanInterview@InfosysSudheer KumarBelum ada peringkat
- PBS 1.1 Quiz Review (Sickels) 23Dokumen158 halamanPBS 1.1 Quiz Review (Sickels) 23tyson.bergsrudBelum ada peringkat
- CV - Nguyen Trung KienDokumen1 halamanCV - Nguyen Trung KienNguyễn Trung KiênBelum ada peringkat
- 8 State Based or Graph Based TestingDokumen4 halaman8 State Based or Graph Based TestingZINNIA MAZUMDER 19BIT0155Belum ada peringkat
- Ds Erhard Roco WaveDokumen27 halamanDs Erhard Roco Wavekad-7Belum ada peringkat
- Test Bank Business Ethics A Textbook With Cases 8th Edition by ShawDokumen8 halamanTest Bank Business Ethics A Textbook With Cases 8th Edition by ShawfjdeBelum ada peringkat
- OOADDokumen21 halamanOOADNamelessBelum ada peringkat
- List of Intel MicroprocessorsDokumen46 halamanList of Intel MicroprocessorsnirajbluelotusBelum ada peringkat
- Essential Rooms for Every HomeDokumen4 halamanEssential Rooms for Every HomePamela Joy SangalBelum ada peringkat