Anda mungkin juga menyukai
- John Krasinski PDFDokumen13 halamanJohn Krasinski PDFJackie Smith IIIBelum ada peringkat
- 10 Tips For Gaining Mass Scientific ApproachDokumen20 halaman10 Tips For Gaining Mass Scientific ApproachMajeed AlhBelum ada peringkat
- Wsorkout Programme Wider FitnessDokumen7 halamanWsorkout Programme Wider FitnessNedim100% (1)
- 4 Day Diet (TAC-Food - The Tactical Readiness Diet Plan)Dokumen13 halaman4 Day Diet (TAC-Food - The Tactical Readiness Diet Plan)KeyProphetBelum ada peringkat
- 2 Cases, Client Profile-Steve RogersDokumen11 halaman2 Cases, Client Profile-Steve Rogerstestbank100% (4)
- Ripped in 42Dokumen14 halamanRipped in 42Austin100% (1)
- Candito 6 Week Strength ProgramDokumen11 halamanCandito 6 Week Strength ProgramHafiz FaizalBelum ada peringkat
- GuruMann - Exercises - Workout-Intermediate Fat LossDokumen2 halamanGuruMann - Exercises - Workout-Intermediate Fat LossSuleiman AbdallahBelum ada peringkat
- 8 Muscle-Building Diet Essentials!Dokumen4 halaman8 Muscle-Building Diet Essentials!qapyrBelum ada peringkat
- Physical PreparationDokumen14 halamanPhysical Preparationapi-298014898Belum ada peringkat
- Strength and Mass The Ultimate 26 Week Guide To Building Life Changing Strength Muscle and Power 3413587639 1507721668Dokumen139 halamanStrength and Mass The Ultimate 26 Week Guide To Building Life Changing Strength Muscle and Power 3413587639 1507721668koBelum ada peringkat
- Body Recompositionin Trained Individuals Manuscript SCJ Augusut 2020Dokumen16 halamanBody Recompositionin Trained Individuals Manuscript SCJ Augusut 2020IliaBelum ada peringkat
- Training ProgramDokumen12 halamanTraining ProgramGiovanni Delli SantiBelum ada peringkat
- Macros For Cutting CalculatorDokumen8 halamanMacros For Cutting CalculatorDeannDonatoBelum ada peringkat
- InstructionsDokumen145 halamanInstructionsFlorinBelum ada peringkat
- Trainingprogram MutantmassDokumen1 halamanTrainingprogram MutantmassPri ViiaBelum ada peringkat
- MSPBehaviorLifestyleCh 230129 130715Dokumen29 halamanMSPBehaviorLifestyleCh 230129 130715Pierfrancesco Lucente100% (1)
- Kinobody Shredding Program Tips On CutsDokumen3 halamanKinobody Shredding Program Tips On CutsLord DrawnzerBelum ada peringkat
- Module Two Wellness PlanDokumen13 halamanModule Two Wellness PlannmmmmmmmmmmmBelum ada peringkat
- WORKOUT Forza e Potenza 8-12 SettimaneDokumen5 halamanWORKOUT Forza e Potenza 8-12 SettimaneGiovanni Delli SantiBelum ada peringkat
- South Indian Non Veg Diet Plan 1Dokumen1 halamanSouth Indian Non Veg Diet Plan 1Madhu IyerBelum ada peringkat
- Samyak Jain Egg Bulking Home WorkoutDokumen19 halamanSamyak Jain Egg Bulking Home Workoutsamyak jainBelum ada peringkat
- The Running Guru Runner's Training GuideDokumen25 halamanThe Running Guru Runner's Training GuideJoão Santos100% (1)
- 10 Best Tips For Keto Dite PlanDokumen18 halaman10 Best Tips For Keto Dite Planhealthylife34Belum ada peringkat
- The Incredible Muscular SystemDokumen13 halamanThe Incredible Muscular Systemchrisdaviscng100% (1)
- Armwrestling Exercise and Shoulder Internal RotationDokumen1 halamanArmwrestling Exercise and Shoulder Internal RotationFitt SallehBelum ada peringkat
- Simply Big and Strong-1Dokumen15 halamanSimply Big and Strong-1PlatesmackerBelum ada peringkat
- SHEILA Fitness TrainingDokumen8 halamanSHEILA Fitness TrainingMaria Stella DavinesBelum ada peringkat
- Kofax Capture Installation GuideDokumen142 halamanKofax Capture Installation GuideJuan Carlos S OBelum ada peringkat
- Exercise Routine For Weight Loss KenyaDokumen2 halamanExercise Routine For Weight Loss Kenyasandra ChemaseBelum ada peringkat
- RP GymFree FAQ 3Dokumen2 halamanRP GymFree FAQ 3Sven PhamBelum ada peringkat
- Physical Activities BenefitsDokumen4 halamanPhysical Activities Benefitsクリステ ィンBelum ada peringkat
- 5 Best Ways To Lose WeightDokumen2 halaman5 Best Ways To Lose Weightzishas1Belum ada peringkat
- Shockingfit Com Advanced Strength Hypetrophy 12 Weeks Workout RoutineDokumen32 halamanShockingfit Com Advanced Strength Hypetrophy 12 Weeks Workout RoutineBrad Powell100% (1)
- Mettle Macro and Calorie Calculator SimpleDokumen32 halamanMettle Macro and Calorie Calculator SimpleJay MikeBelum ada peringkat
- RP Sample Client Intake FormDokumen5 halamanRP Sample Client Intake FormPierfrancesco LucenteBelum ada peringkat
- Kynes Carb CyclingDokumen3 halamanKynes Carb Cyclingstormich656Belum ada peringkat
- 5 Methods To Force Muscle GrowthDokumen3 halaman5 Methods To Force Muscle GrowthGeico LizardBelum ada peringkat
- 6 Weeks To Sick Arms PDFDokumen2 halaman6 Weeks To Sick Arms PDFAMal KRishnaBelum ada peringkat
- Phiq099 Physical Iq Afaa Prospectus 6Dokumen15 halamanPhiq099 Physical Iq Afaa Prospectus 6tesfamichael100% (1)
- Rutina Marzo2012Dokumen11 halamanRutina Marzo2012Denisse Andrade LeyvaBelum ada peringkat
- Barbell and Dumbbell 5 Day SplitDokumen4 halamanBarbell and Dumbbell 5 Day SplitAmaan AbbasBelum ada peringkat
- You Are What and How You Eat: A Simple Guide to Eating ProperlyDari EverandYou Are What and How You Eat: A Simple Guide to Eating ProperlyBelum ada peringkat
- Built LeanDokumen4 halamanBuilt LeanKostaPemacBelum ada peringkat
- Self-Correcting Macro Plan (PC Users)Dokumen24 halamanSelf-Correcting Macro Plan (PC Users)Mohannad Ali100% (1)
- 3 Months To MassDokumen6 halaman3 Months To MassDavor SmolicBelum ada peringkat
- The Ramadan Nutrition Plan RNP For People With DiabetesDokumen15 halamanThe Ramadan Nutrition Plan RNP For People With DiabetesWinny DhestinaBelum ada peringkat
- RFP To Conduct DQA VASDokumen27 halamanRFP To Conduct DQA VASadrianBelum ada peringkat
- AMP - Marc Megna's 8-Week Aesthetics Meets Performance TrainerDokumen7 halamanAMP - Marc Megna's 8-Week Aesthetics Meets Performance Trainermohamed aliBelum ada peringkat
- Problems On Array For Interviews and Competitive Programming (., Tushti Kiao, Ue Chatterjee, Aditya) (Z-Library)Dokumen475 halamanProblems On Array For Interviews and Competitive Programming (., Tushti Kiao, Ue Chatterjee, Aditya) (Z-Library)qmu94562Belum ada peringkat
- Docker Anti Patterns Vertical 3Dokumen24 halamanDocker Anti Patterns Vertical 3Jagdesh RebbaBelum ada peringkat
- MurrelDokumen3 halamanMurrelsam_sivanesanBelum ada peringkat
- A Powerful Manifestation Technique Using Qi GongDokumen11 halamanA Powerful Manifestation Technique Using Qi Gongvirendhemre93% (14)
- Almond Purchasing ConsiderationsDokumen1 halamanAlmond Purchasing ConsiderationsJagdesh RebbaBelum ada peringkat
- Telangana Telugu Calendar 2017 DecemberDokumen1 halamanTelangana Telugu Calendar 2017 DecemberJagdesh RebbaBelum ada peringkat
- Telangana Telugu Calendar 2017 November PDFDokumen1 halamanTelangana Telugu Calendar 2017 November PDFJagdesh RebbaBelum ada peringkat
- DEER Exercise PDFDokumen25 halamanDEER Exercise PDFJagdesh Rebba100% (1)
- Chi Kung BibleDokumen219 halamanChi Kung BibleBarefoot_Scott100% (17)
- Transportation 2 - Technical ReportDokumen35 halamanTransportation 2 - Technical ReportJagdesh RebbaBelum ada peringkat
- Qigong Energy & MagnetsDokumen13 halamanQigong Energy & Magnetsunknown2ume95% (42)
- Da Stark HwanDokumen44 halamanDa Stark HwanPramod GosaviBelum ada peringkat
- Banned Manifestation Secrets - Richard Dotts PDFDokumen154 halamanBanned Manifestation Secrets - Richard Dotts PDFJagdesh Rebba94% (17)
- FTP Exploits by Ankit FadiaDokumen18 halamanFTP Exploits by Ankit Fadiapaul_17oct@yahoo.co.inBelum ada peringkat
- New Hydrogen Production InventionDokumen3 halamanNew Hydrogen Production InventionJagdesh RebbaBelum ada peringkat
- 4 29 14 Algae BioreactorsDokumen50 halaman4 29 14 Algae BioreactorsJagdesh RebbaBelum ada peringkat
- 99 Minute Millionaire - The Simp - Scott Alan TurnerDokumen576 halaman99 Minute Millionaire - The Simp - Scott Alan TurnerJagdesh RebbaBelum ada peringkat
- Origami - Everything You Need To - Sandra GiffordDokumen238 halamanOrigami - Everything You Need To - Sandra GiffordJagdesh RebbaBelum ada peringkat
- A Free Online LibraryDokumen3 halamanA Free Online LibraryJagdesh RebbaBelum ada peringkat
- Concentration: A Guide To Mental Mastery - Mouni Sadhu PDFDokumen192 halamanConcentration: A Guide To Mental Mastery - Mouni Sadhu PDFTravis MayerBelum ada peringkat
- Key Applications: IC3 Digital Literacy CertificationDokumen2 halamanKey Applications: IC3 Digital Literacy CertificationMuhammad Kazim100% (1)
- Week 1-Clients, Servers and Networks - HowtheWebWorksDokumen85 halamanWeek 1-Clients, Servers and Networks - HowtheWebWorksLazarus Kadett NdivayeleBelum ada peringkat
- Adaptador PERC H700 (Raid)Dokumen29 halamanAdaptador PERC H700 (Raid)Maria Eugenia Guerra SolerBelum ada peringkat
- Pricing OW 903 FinalDokumen39 halamanPricing OW 903 FinalemedinillaBelum ada peringkat
- 8051 AssemblerDokumen2 halaman8051 Assemblersharry19Belum ada peringkat
- User Guide To SimcaDokumen661 halamanUser Guide To SimcaAli HamiehBelum ada peringkat
- Procreate Artists Handbook PDFDokumen453 halamanProcreate Artists Handbook PDFBrian96% (23)
- Guide To Access VPN Through MobileDokumen15 halamanGuide To Access VPN Through Mobilerajeev singhBelum ada peringkat
- Infinity-Box ContentExtractor Installation Manual PDFDokumen10 halamanInfinity-Box ContentExtractor Installation Manual PDFAnonymous GZTu3fhnyoBelum ada peringkat
- Data Structures and Caatts For Data ExtractionDokumen33 halamanData Structures and Caatts For Data Extractionmary aligmayoBelum ada peringkat
- AI and Web Based Human Like Nteractive University Chatbot PDFDokumen3 halamanAI and Web Based Human Like Nteractive University Chatbot PDFpratik thakareBelum ada peringkat
- Assembly LabDokumen13 halamanAssembly LabKrishna Vasishta KavuturuBelum ada peringkat
- Netflix Full Technical Specifications PDFDokumen31 halamanNetflix Full Technical Specifications PDFJuan GaitánBelum ada peringkat
- Rahul Raj MantooDokumen3 halamanRahul Raj Mantooshakti4itBelum ada peringkat
- 50 Best Apache Spark Interview Questions & Answers (Updated)Dokumen1 halaman50 Best Apache Spark Interview Questions & Answers (Updated)Csvv VardhanBelum ada peringkat
- DeltaV OPC Events ServerDokumen3 halamanDeltaV OPC Events ServerIsraelBelum ada peringkat
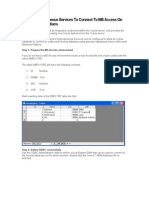
- Oracle Heterogeneous Services To Connect To MS Access On MS WindowsDokumen4 halamanOracle Heterogeneous Services To Connect To MS Access On MS WindowsAhmed Abd El LatifBelum ada peringkat
- PHP Project: "Online Entertainment World"Dokumen4 halamanPHP Project: "Online Entertainment World"Shubham KumarBelum ada peringkat
- Tuning All Layers of The Oracle E-Business SuiteDokumen2 halamanTuning All Layers of The Oracle E-Business SuiteTeddy WijayaBelum ada peringkat
- Topics For SA (System Analyst) (For Online Computerized Test) Sr. No. TopicsDokumen8 halamanTopics For SA (System Analyst) (For Online Computerized Test) Sr. No. TopicsRahul TiwariBelum ada peringkat
- Autosys CommandsDokumen5 halamanAutosys CommandsNigam PatelBelum ada peringkat
- PowerShell Transcript - deskTOP-B75KN0C.kxbg BRC.20220316124721Dokumen3 halamanPowerShell Transcript - deskTOP-B75KN0C.kxbg BRC.20220316124721Hoott NiiggaBelum ada peringkat
- Read MeyppppppppppppppoooooDokumen2 halamanRead MeyppppppppppppppoooooAnonymous 7dsX2F8nBelum ada peringkat
- WAN or Internet Access To GP-Pro EX: Application Note #1184Dokumen14 halamanWAN or Internet Access To GP-Pro EX: Application Note #1184muftah76Belum ada peringkat
- Formulas VlookupDokumen25 halamanFormulas VlookupJp CombisBelum ada peringkat
- Torrent ProjectDokumen18 halamanTorrent ProjectRahulBelum ada peringkat
- High WatermarkDokumen3 halamanHigh WatermarkMohd FauziBelum ada peringkat
- FreeNAS 11.2 U7 Legacy User Guide ScreenDokumen345 halamanFreeNAS 11.2 U7 Legacy User Guide ScreenJustin BlandBelum ada peringkat
- Mysql Dba QaDokumen4 halamanMysql Dba Qanavin_netBelum ada peringkat
- Chou, George Tsu-Der, Dbase III Plus Handbook, 2 Edition, Page 3Dokumen4 halamanChou, George Tsu-Der, Dbase III Plus Handbook, 2 Edition, Page 3Richille SordillaBelum ada peringkat