Anda mungkin juga menyukai
- Bison Pte OyateDokumen1 halamanBison Pte OyateBlackthornBelum ada peringkat
- UmnDokumen1 halamanUmnBlackthornBelum ada peringkat
- THE ARCHAEOLOGY OF THE DILMUN MERCHANT EA-NASIRDokumen5 halamanTHE ARCHAEOLOGY OF THE DILMUN MERCHANT EA-NASIRBlackthornBelum ada peringkat
- An Outline History of The Viet Nam Worker's PartyDokumen97 halamanAn Outline History of The Viet Nam Worker's PartyBlackthornBelum ada peringkat
- Hiphil Stem HebrewDokumen3 halamanHiphil Stem HebrewAnthony PowellBelum ada peringkat
- Psalm 2Dokumen1 halamanPsalm 2BlackthornBelum ada peringkat
- Etymological Dictionary Basque - TraskDokumen418 halamanEtymological Dictionary Basque - TraskKoen Van Den DriesscheBelum ada peringkat
- Psalm 1 - Text and TranslationDokumen1 halamanPsalm 1 - Text and TranslationBlackthornBelum ada peringkat
- Never Split the Difference: Negotiating As If Your Life Depended On ItDari EverandNever Split the Difference: Negotiating As If Your Life Depended On ItPenilaian: 4.5 dari 5 bintang4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeDari EverandShoe Dog: A Memoir by the Creator of NikePenilaian: 4.5 dari 5 bintang4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDari EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifePenilaian: 4 dari 5 bintang4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)Dari EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Penilaian: 4 dari 5 bintang4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDari EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RacePenilaian: 4 dari 5 bintang4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingDari EverandThe Little Book of Hygge: Danish Secrets to Happy LivingPenilaian: 3.5 dari 5 bintang3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDari EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FuturePenilaian: 4.5 dari 5 bintang4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDari EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryPenilaian: 3.5 dari 5 bintang3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDari EverandGrit: The Power of Passion and PerseverancePenilaian: 4 dari 5 bintang4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDari EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaPenilaian: 4.5 dari 5 bintang4.5/5 (265)
- On Fire: The (Burning) Case for a Green New DealDari EverandOn Fire: The (Burning) Case for a Green New DealPenilaian: 4 dari 5 bintang4/5 (73)
- The Emperor of All Maladies: A Biography of CancerDari EverandThe Emperor of All Maladies: A Biography of CancerPenilaian: 4.5 dari 5 bintang4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDari EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersPenilaian: 4.5 dari 5 bintang4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaDari EverandThe Unwinding: An Inner History of the New AmericaPenilaian: 4 dari 5 bintang4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnDari EverandTeam of Rivals: The Political Genius of Abraham LincolnPenilaian: 4.5 dari 5 bintang4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDari EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyPenilaian: 3.5 dari 5 bintang3.5/5 (2219)
- Rise of ISIS: A Threat We Can't IgnoreDari EverandRise of ISIS: A Threat We Can't IgnorePenilaian: 3.5 dari 5 bintang3.5/5 (137)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDari EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You ArePenilaian: 4 dari 5 bintang4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Dari EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Penilaian: 4.5 dari 5 bintang4.5/5 (119)
- Her Body and Other Parties: StoriesDari EverandHer Body and Other Parties: StoriesPenilaian: 4 dari 5 bintang4/5 (821)
- 9781107650411c02 p024-113Dokumen90 halaman9781107650411c02 p024-113Juan HidrovoBelum ada peringkat
- Pakistani English: Some Phonological and Phonetic FeaturesDokumen13 halamanPakistani English: Some Phonological and Phonetic FeaturesNihar AfridiBelum ada peringkat
- Hofling & Tesucun - Itzaj Maya Grammar-University of Utah Press (2000) PDFDokumen615 halamanHofling & Tesucun - Itzaj Maya Grammar-University of Utah Press (2000) PDFOcsicnarfX100% (1)
- Edith Tiempo'sDokumen25 halamanEdith Tiempo'sKendrick Jan Royd Tagab100% (1)
- LSA3 Pron FinalDokumen12 halamanLSA3 Pron Finaleal2012Belum ada peringkat
- Phonology For Listening - Relishing The MessyDokumen15 halamanPhonology For Listening - Relishing The MessyNoerdien Ooff De'ring100% (2)
- Cook (2008) - CH 4 - Acquiring and Teaching PronunciationDokumen22 halamanCook (2008) - CH 4 - Acquiring and Teaching PronunciationJoannaPilakBelum ada peringkat
- ELAStandards 2020Dokumen119 halamanELAStandards 2020ZimbleonBelum ada peringkat
- Peer Reviewed Article Subglottal Pressure Variation in Actors' Stage SpeechDokumen5 halamanPeer Reviewed Article Subglottal Pressure Variation in Actors' Stage SpeechMaríaBentancurBelum ada peringkat
- EA Korean1 BKLTDokumen31 halamanEA Korean1 BKLTDean TaylorBelum ada peringkat
- Hangul, The Korean Script The World's Best' AlphabetDokumen54 halamanHangul, The Korean Script The World's Best' AlphabetТев ЛевBelum ada peringkat
- Communicating Effectively in English HandoutDokumen13 halamanCommunicating Effectively in English HandoutJaqueline Cerial - BorbonBelum ada peringkat
- Dr. Gloria Lacson Foundation Colleges Health 1 Curriculum GuideDokumen9 halamanDr. Gloria Lacson Foundation Colleges Health 1 Curriculum GuideJean Marie Itang GarciaBelum ada peringkat
- Segments 01 (April 2021) - Rconlangs (Single Page)Dokumen224 halamanSegments 01 (April 2021) - Rconlangs (Single Page)Simon VotteroBelum ada peringkat
- (1913) Phonology & Grammar of Modern West Frisian: With Phonetic Texts & GlossaryDokumen194 halaman(1913) Phonology & Grammar of Modern West Frisian: With Phonetic Texts & GlossaryHerbert Hillary Booker 2nd100% (1)
- How to Pronounce -S and -ED EndingsDokumen29 halamanHow to Pronounce -S and -ED EndingsJelena JelenaBelum ada peringkat
- Introduction To Phonetic ScienceDokumen49 halamanIntroduction To Phonetic ScienceMonMaBelum ada peringkat
- Differential Diagnosis of Children With Suspected Childhood Apraxia of SpeechDokumen19 halamanDifferential Diagnosis of Children With Suspected Childhood Apraxia of Speechadriricalde100% (1)
- Lodge, David - Modern Criticism and Theory (1) - RemovedDokumen89 halamanLodge, David - Modern Criticism and Theory (1) - Removedbharathivarshini05Belum ada peringkat
- Russian GrammarDokumen158 halamanRussian GrammarCamarada KolobanovBelum ada peringkat
- PronunciationDokumen14 halamanPronunciationana_amyBelum ada peringkat
- Hangul Bat-Chim Rules 1: Lenition and Fortis: GrammarDokumen5 halamanHangul Bat-Chim Rules 1: Lenition and Fortis: GrammarAila Myrestel JunioBelum ada peringkat
- Acoustic Effects of Urdu On EngDokumen16 halamanAcoustic Effects of Urdu On EngDr Abdus SattarBelum ada peringkat
- Star Pron Bonus Stress RulesDokumen3 halamanStar Pron Bonus Stress Rulesapi-234740666Belum ada peringkat
- Heidi M. Altman-Eastern Cherokee Fishing (Contemporary American Indians) - University of Alabama Press (2006) PDFDokumen154 halamanHeidi M. Altman-Eastern Cherokee Fishing (Contemporary American Indians) - University of Alabama Press (2006) PDFNathan WagarBelum ada peringkat
- Kindergarten Learning ObjectivesDokumen12 halamanKindergarten Learning Objectivesapi-259785027Belum ada peringkat
- Collar - The Gate To Caesar PDFDokumen168 halamanCollar - The Gate To Caesar PDFKevin HarrisBelum ada peringkat
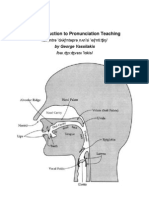
- An Introduction To Pronunciation Teaching: /NNTR 'DK NTPRNN Si 'E Nti: / /ba: Vas 'LkisDokumen37 halamanAn Introduction To Pronunciation Teaching: /NNTR 'DK NTPRNN Si 'E Nti: / /ba: Vas 'LkisGeorge Vassilakis50% (2)
- Stevenson The Rhythm of English VerseDokumen19 halamanStevenson The Rhythm of English VerselolsignupBelum ada peringkat
- AIOU warns against plagiarism in English assignmentsDokumen9 halamanAIOU warns against plagiarism in English assignmentsranaaliahmedBelum ada peringkat